Use your Ansible logs ! / Exploitez vos logs Ansible !
English version here
J’utilise Ansible au quotidien. Tous les jours, mes collègues et moi même l’utilisons pour configurer nos serveurs et déployer nos applications, sur de nombreux environnements. Nous utilisons Jenkins pour piloter Ansible.
Tout cela génère une énorme quantité de logs, dont nous ne faisons pas grand chose à part une consultation après un déploiement via l’interface de Jenkins.
J’expliquerais dans cet article une façon d’exploiter ces logs, en s’appuyant sur les plugins callback d’Ansible. Grâce à ces plugins, il est possible d’obtenir des logs beaucoup plus détaillés que les logs Ansible de base, ainsi que de facilement les manipuler pour en tirer un maximum d’informations et de statistiques.
Les callbacks plugins d’Ansible
Présentation générale
Ansible peut être "étendu" avec des plugins. Je vais présenter ici les plugins de type callback (documentation). Les examples ici concernent Ansible 1.X, mais le fonctionnement est quasiment identique en version 2 et plus.
Ce plugin permet de définir un objet dont les fonctions seront appelées à différents moments lors de l’exécution d’Ansible. Exemple:
class CallbackModule(object):
def on_any(self, *args, *kwargs):
pass
def runner_on_failed(self, host, res, ignore_errors=False):
pass
def runner_on_ok(self, host, res):
pass
def runner_on_skipped(self, host, item=None):
pass
def playbook_on_start(self):
pass
def playbook_on_task_start(self, name, is_conditional):
pass
= etc...Un callback plugin est donc juste une classe implémentant un certain nombre de méthodes. J’en ai mis quelques unes dans cet exemple, mais il en existe beaucoup plus pour tout type d’événements (vous pouvez retrouver ces fonctions dans la doc d’Ansible ou dans les plugins callbacks fournis avec Ansible).
Fonctionnement détaillé
Par exemple, la fonction runner_on_failed sera appelé quand une task Ansible échouera. De la même façon, runner_on_ok sera appelé lorsque qu’une tâche sera en succès, runner_on_skipped lors d’une tâche ignorée etc…
Les fonctions de type playbook_on_ seront elles exécutées lors d’évènements liés aux playbooks (playbook_on_start lors du démarrage du playbook etc…).
Toutes ces fonctions recoivent des paramètres. C’est là que ça devient intéressant. Par exemple, nous disposons dans runner_on_ok des variables self, host, et res :
-
Commençons par la variable host. Comme son nom l’indique, cette variable contient l’host sur lequel s’applique la task.
-
La variable res contient les différentes informations sur la machine comme par exemple les variables de type fact, ainsi que quelques informations sur la task (état changed, module appelé…).
-
L’objet callback self contient un grand nombre d’informations sur l’exécution en cours. Rajoutons par exemple import pdb; pdb.set_trace(); dans la fonction runner_on_ok (pour utiliser le débugger Python) et lançons un déploiement. Un pp dir(self) pour lister les champs de l’objet donne:
(Pdb) pp dir(self)
['__class__',
'__delattr__',
'__dict__',
'__doc__',
'__format__',
'__getattribute__',
'__hash__',
'__init__',
'__module__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__',
'__weakref__',
'on_any',
'play',
'playbook',
'playbook_on_import_for_host',
'playbook_on_no_hosts_matched',
'playbook_on_no_hosts_remaining',
'playbook_on_not_import_for_host',
'playbook_on_notify',
'playbook_on_play_start',
'playbook_on_setup',
'playbook_on_start',
'playbook_on_stats',
'playbook_on_task_start',
'playbook_on_vars_prompt',
'runner_on_async_failed',
'runner_on_async_ok',
'runner_on_async_poll',
'runner_on_failed',
'runner_on_no_hosts',
'runner_on_ok',
'runner_on_skipped',
'runner_on_unreachable',
'state',
'task']L’objet self est une vraie mine d’or ! A coup de pdb (pp dir(self.task), pp dir(self.play) etc…) on se rend compte que l’on a accès à une énorme quantité d’informations sur notre déploiement. Détail de la tâche en cours (nom, rôle associé…), variables, informations sur le playbook… Il ne reste plus qu’à piocher dans ce qui nous intéresse ! Bien sûr, chaque fonction du plugin callback aura des paramètres différents (même si l’on retrouve des similarités, comme par exemple entre runner_on_failed et runner_on_ok).
playbook on start
La méthode playbook_on_start s’exécute, comme son nom l’indique, au lancement d’un playbook. Je voulais initialiser quelques variables à partir d’extra_vars, j’ai donc utilisé cette fonction pour le faire. Voici un exemple basique (je considère qu’une fonction get_timestamp me retourne le timestamp actuel) :
def playbook_on_start(self):
extra_vars = self.playbook.extra_vars
self.project = extra_vars["project"]
self.version = extra_vars["version"]
self.environment = extra_vars["environment"]
self.start_timestamp = get_timestamp()Ici, je récupère trois variables que je sais présentes en extra_vars. Une variable projet (le projet à déployer), une variable version (la version à déployer), une variable environment (dev, préprod, prod…), et le timestamp du démarrage du déploiement. J’utilise ces quatres informations pour identifier précisément un déploiement.
Bref, il est très facile de pouvoir rendre accessibles certaines variables en enrichissant self lors de l’exécution des fonctions (l’objet callback étant toujours le même dans un déploiement). Les autres variables de self sont bien sûr également accessibles si besoin.
playbook on stats
Une autre fonction intéressante est playbook_on_stats. Cette fonction est appelée à la fin du déploiement, et contient le résumé du déploiement. Voici par exemple la façon de récupérer le résumé (contenant les tasks unreachable, skipped, changed…) du déploiement par host :
def playbook_on_stats(self, stats):
hosts = stats.processed.keys()
for h in hosts:
summary = stats.summarize(h)Je récupère personnellement le résumé du déploiement par host, mais aussi un résumé global en additionnant chaque type de task (ok, skipped…) de chaque host.
La génération des logs
Il ne vous reste plus qu’à compléter les différentes fonctions du plugin callback pour générer des logs au format souhaité. Voici par exemple un exemple tout bête qui envoie (via http en utilisant le package requests) un log à un web server lorsqu’une task échoue:
def runner_on_failed(self, host, res, ignore_errors=False):
task = self.task
result = {
"timestamp": get_timestamp(),
"host": host,
"type": "task_failed",
"task": task.name,
"role": task.role_name,
"result": json.dumps(res),
"version": self.version, # Cette variable et les suivantes sont initialisées comme précédemment
"environment": self.environment,
"project": self.project,
"start_timestamp": self.start_timestamp
}
requests.post(url_web_server, data=json.dumps(result))On aura ici accès au timestamp, à l’host, au type d’évènement (task_failed), au nom de la task, au rôle associé à la task si il existe, au résultat détaillé de l’exécution de la task, et enfin aux variables définies plus tôt dans playbook_on_start (ces variables sont communes à tous les logs d’un même déploiement et permettent ensuite d’identifier les logs pour un déploiement donné).
Il ne reste plus qu’à écrire un code similaire dans les autres fonctions du plugin callback (en l’adaptant à chaque fois), et on arrive déjà sans grand effort à collecter des logs très intéressants !
Collectez et stockez vos logs
Les possibilités avec les plugins Ansible sont infinies. J’ai choisi de les envoyer comme dans l’exemple précédent dans un service web (9 lignes de Python avec Flask + kafka-python). Ce service ne réalise qu’une seule chose : après réception d’un log, il l’envoie dans Kafka. Un Logstash collecte ensuite les logs de Kafka pour les indexer dans Elasticsearch. J’ai essayé d’envoyer directement du plugin dans kafka, mais Ansible semble gérer bizarrement le cycle de vie de ses objets, ce qui posait quelques soucis avec kafka-python.
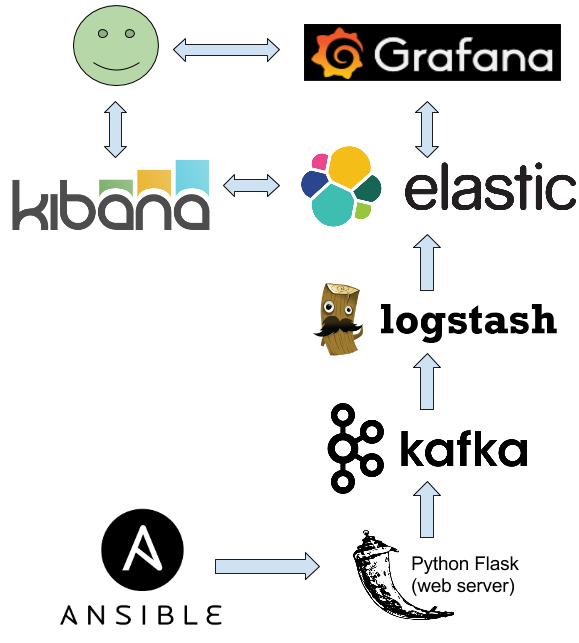
Vous pourriez très bien écrire les logs sur disque, ou les envoyer dans une base de données… Tout dépend de ce que voulez en faire. L’avantage d’Elasticsearch est qu’il est très facile ensuite de réaliser des requêtes complexes/des graphes sur les logs via Kibana/Grafana.
Exploitation des logs
Rien qu’avec les informations fournies précédemment par le plugin callback, je peux :
-
Réaliser des recherches complexes dans Kibana (exemple : récupérer les tasks en échec pour le rôle HAproxy d’un projet donné ces 90 derniers jours sur la préprod). De plus, tous les logs sont centralisés au même endroit, ça évite d’avoir à se balader de jobs Jenkins en jobs Jenkins pour visualiser les logs (qui sont souvent illisibles avec l’option -vvvv d’Ansible)
-
Dans Grafana, par projet:
-
Résumé des derniers déploiements (heure de début, environnement, succès ou non, nombre de tasks skipped/changed/unreachable etc…)
-
Liste des déploiements lancés (ceux en cours sont donc lancés mais non terminés).
-
Nombre de déploiements terminés sur une période de temps
-
Nombre de déploiements lancés sur une période de temps (permet de comparer avec le nombre de déploiements terminés).
-
Nombre de task pour chaque rôle sur une période de temps en fonction du type de la task (skipped, changed…)
-
Nombre de fois qu’un rôle a été en échec.
-
Rôles les moins fiables (le plus souvent en échec).
-
Temps d’exécution de chaque rôle rôle (minimum, maximum, moyenne…).
-
Dans Grafana, tous les graphes cités précédemment mais de façon globale (donc sans la notion de projet).
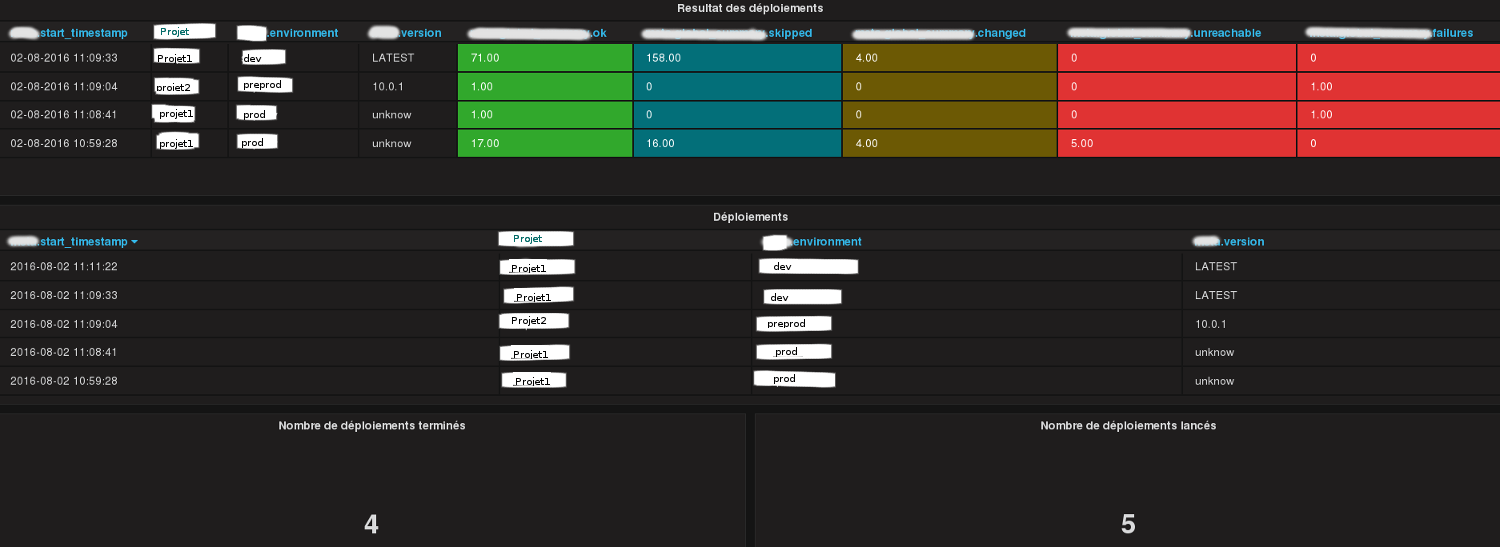
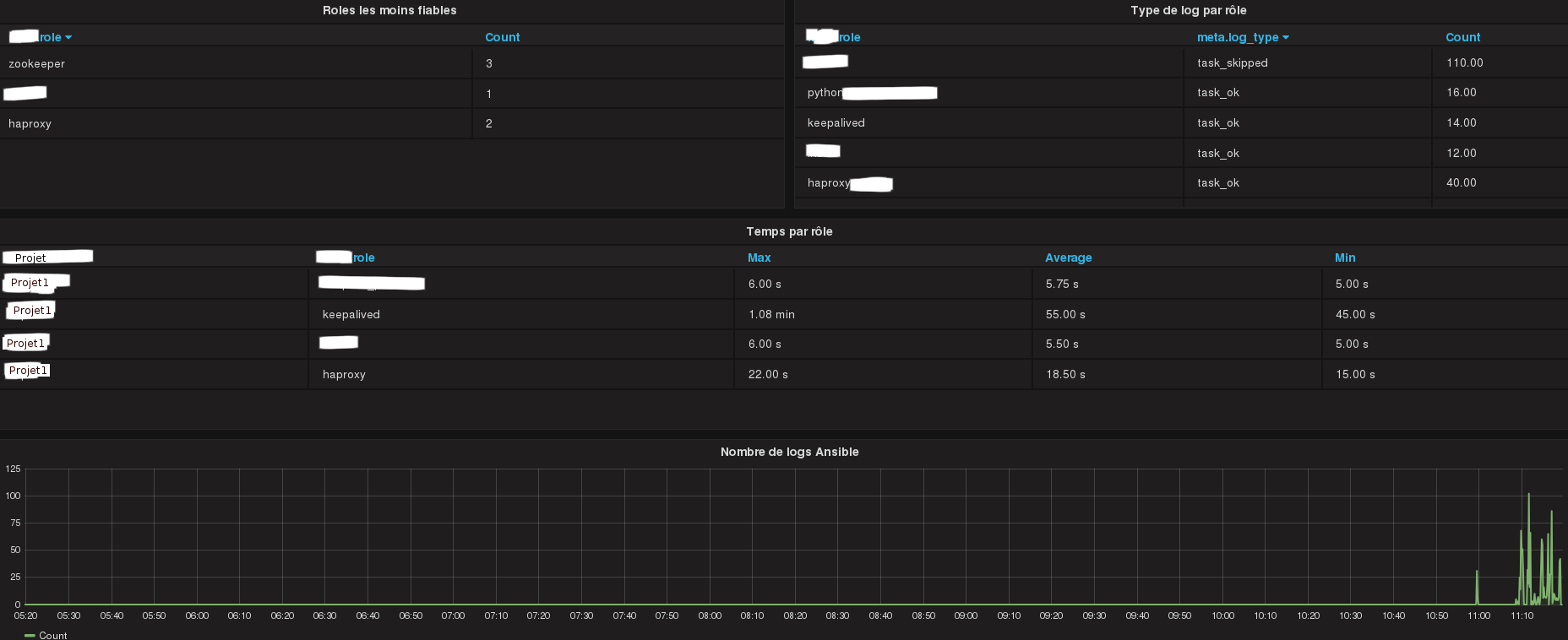
Ces deux images présentent quelques graphes Grafana (anonymisées) générés via les statistiques récoltées par le plugin. Liens vers les images en tailles réelles ici et ici.
Le temps par rôle peut être calculé assez simplement. Lors de l’exécution d’une task, on a accès dans le plugin au rôle associé à la task. J’initialise un dictionnaire où la clé est le nom du rôle, et la valeur un tableau de deux élements. Le premier élément est le timestamp de la première task du rôle. Je mets ensuite à jour le second élément (la date de fin du rôle) à chaque nouvelle task. J’envoie ensuite ces statistiques pour chaque rôle (si il n’y a pas eu de plantage pouvant causer de fausses durées) en fin de déploiement.
Pensez également à pré-traiter certains logs, comme par exemple les paramètres res des fonctions. Ces paramètres peuvent être trèèèèès longs (des dizaines de milliers de caractères), notamment lors de téléchargements volumineux avec Ansible en mode -vvvv. Je remplace généralement les résultats trop longs par un message de type résultat trop long (ce sont généralement des données inexploitables).
Ansible 2
Le porting guide d’Ansible livre quelques informations pour porter les plugins Callback en Ansible 2. Malheureusement, le fonctionnement interne d’Ansible ayant bougé, il faudra réadapter le code. En vrac :
-
Les extra_vars ne sont plus accessibles dans playbook_on_start mais seulement à partir de v2_playbook_on_play_start, et d’une façon un peu différente :
extra_vars = play.get_variable_manager().extra_vars-
Le nom du rôle est accessible dans v2_playbook_on_task_start. Pour garder une certaine compatibilité avec du code Ansible 1.X, vous pouvez faire :
if task._role is not None: # on verifie si c'est un role ou non
task.role_name = task._role._role_nameConclusion
Les possibilités du plugin callback sont infinies. Je pense sincèrement qu’en prenant le temps, il est possible de réaliser de nombreuses statistiques sur les déploiements (ainsi que de l’alerting, de la corrélation avec d’autres métriques comme des métriques systèmes…), surtout avec des outils puissants comme Kibana/Grafana. Bref, à creuser !
Add a comment
If you have a bug/issue with the commenting system, please send me an email (my email is in the "About" section).