REPL Driven Development et gestion des états
Lorsque l’on code en Clojure (mais pas que), il y a un outil formidable pour nous accompagner: le REPL. Dans cet article, je parlerais de programmation intéractive et de la gestion des états dans une application
Programmation intéractive
Présentation
En Clojure (et dans les langages de la famille des LISP en général), nous développons avec un REPL. On pourrait définir le REPL comme un interpréteur évolué, en permanence connecté à notre code.
Voici par exemple à quoi ressemble mon écran lorsque je code en Clojure (Emacs ftw):
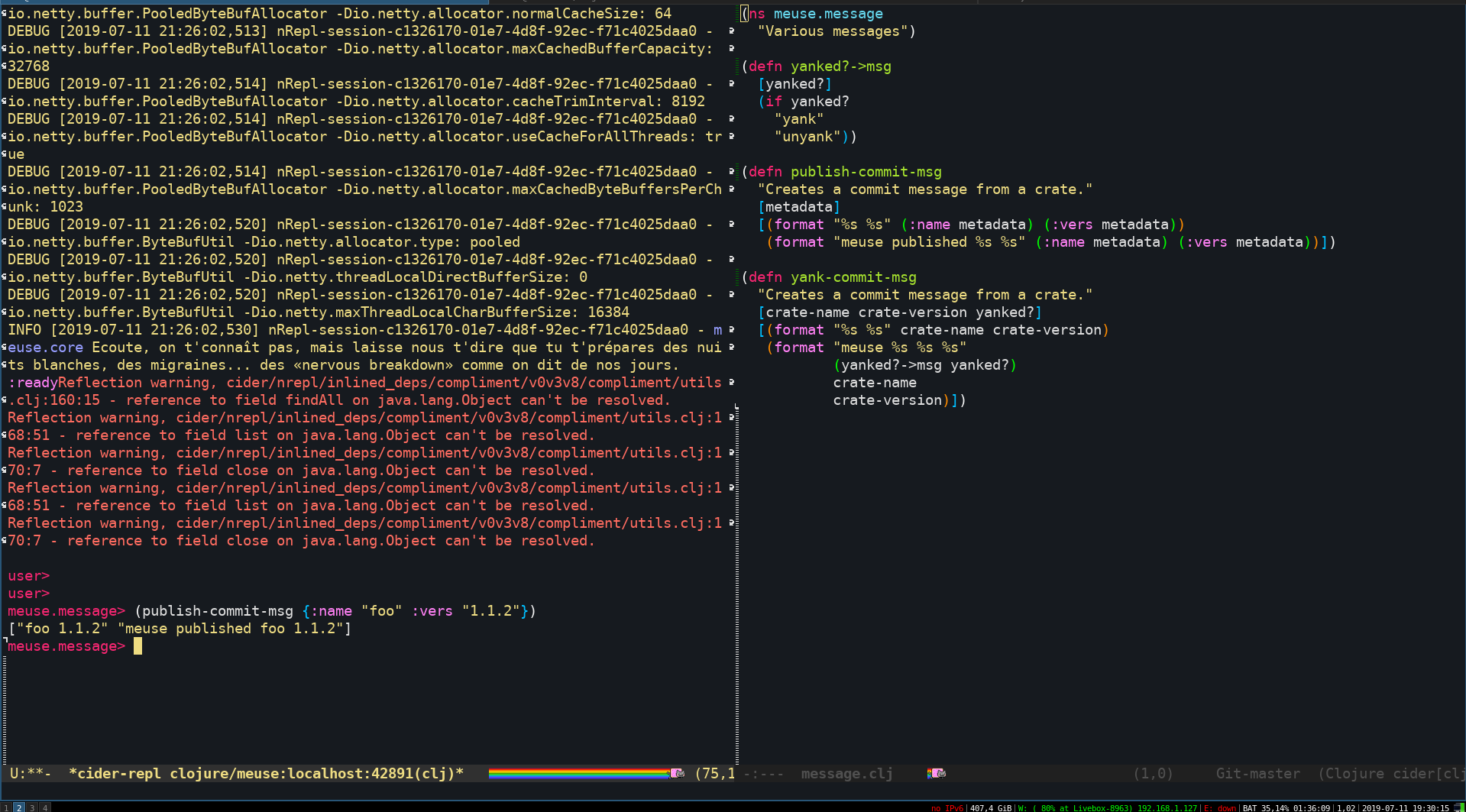
On peut voir ici que j’ai sur le côté gauche de mon écran mon REPL, et sur le côté droit mon code. Je peux à tout moment intéragir avec mon REPL, comme par exemple "charger" le code de mon projet dans le REPL et exécuter le code. Je peux également définir des fonctions, variables temporaires etc… directement dans le REPL.
Quand je parles du REPL à d’autres développeurs, j’ai souvent des réflexions du type mais des interpréteurs il y en a dans tous les langages !. Effectivement, même Java a maintenant un REPL.
Pourtant, vous vous voyez coder avec le REPL en Java ? Charger un programmes Spring Boot dans un REPL puis intéragir avec ? Taper du code ultra verbeux dans le REPL ? Ceci est de la science fiction, et n’arrivera jamais.
Mon workflow
Lorsque je code en Clojure, mon workflow est le suivant:
-
Je réfléchis à mon problème en écrivant du code et en le chargeant dans le REPL. J’intéragis avec celui ci via le REPL (j’appelle les fonctions que j’écris avec certains paramètres par exemple).
-
J’écris des tests, et je fignole, toujours en utilisant le REPL. L’exécution de mes tests est
ultra rapide, car ma JVM/mon application est déjà démarrée.
Intéragir avec son code via le REPL ne remplace donc pas les tests. Par contre, la boucle de feedback sur ce que l’on fait est ultra rapide. J’écris une fonction, je peux immédiatement jouer avec.
Je ne pratique donc pas le TDD lorsque je fais du Clojure, je ne commence pas à écrire mes tests mais j’utilise le REPL pour définir la structure de mon programme, puis je les écris.
Le fait que Clojure soit un langage où la syntaxe est très concise et où l’immuabilité est très présente joue aussi. Je n’aurais pas la même expérience dans un langage verbeux ou pleins d’états.
D’ailleurs, parlons d’états.
Gestion des états
Composants
Comme dit précédemment, en Clojure pratiquement tout est immuable, ce qui est génial.
Mais dans un programme, j’ai quand même besoin d’états (faut bien faire des entrées/sorties un jour ou l’autre pour intéragir avec). Prenons par exemple Meuse, mon projet de registry Rust sur lequel je travaille actuellement.
Ce projet est une application web classique. Voici les composants devant garder un état/faisant des effets de bords dans cette application:
-
Le chargement de ma configuration (un fichier yaml).
-
Un serveur HTTP.
-
Un threadpool de connexion vers une base de données.
-
Un composant envoyant des commandes Git, et qui possède un lock.
Dans d’autres cas, j’aurais pû avoir un cache, ou d’autres threadpools… Mais finalement, il y a peu de composants avec état dans un programme.
On remarque facilement que ces états ont des dépendances. Mon composant database a besoin de sa configuration, le composant http a aussi besoin de sa configuration mais aussi du composant database et git. Le composant git a lui même besoin d’une configuration:
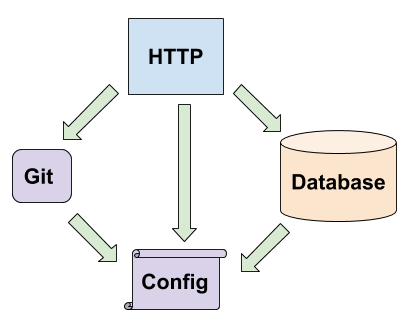
Les dépendances de mon application peuvent donc se voir comme un arbre.
En Java, c’est généralement via l’injection de dépendance que les composants sont instanciés dans le bon ordre, et "stockés" dans un conteneur de façon un peu magique
En parlant de cela, je trouve dommage que l’écosystème Java pousse à cette pratique (@inject moi mes objets et après moi le déluge), là où quelques new et des constructeurs bien écrits suffiraient à résoudre le problème. Bref.
En Clojure, il est possible de définir ces composants via certaines librairies, comme par exemple component, mount ou integrant.
Sans rentrer dans les détails de chaque librairie, chacune permet à sa manière de définir cette hiérarchie de composant.
Chaque librairie permet aussi de facilement démarrer votre système (un système étant la somme de vos composants). Démarrer votre système équivant donc à démarrer votre application. Il est également possible de stopper le système, de le démarrer partiellement, et même de remplacer un composant par un mock pour les tests !
Et bien sûr, tout cela est faisable via le REPL. Un exemple:
-
Je démarre mon application via le REPL. Mon application est maintenant active. J’ajoute une nouvelle route dans mon routeur HTTP, "charge" mon code dans le REPL. La route est tout de suite active !
-
J’implémente le code de ma nouvelle route. A tout moment, je peux recharger mon code, et celui ci sera actif. Je peux également expérimenter facilement via le REPL.
-
j’écris des tests, qui comme dit précédemment s’exécutent à toute vitesse vu que ma JVM tourne déjà.
Il est possible de modifier n’importe quelle partie de mon programme à chaud à tout moment. Bref, mon confort de développement est énorme (je n’ai rien trouvé de semblable en Python/Rust/Go/Java/C etc…).
il est d’ailleurs même possible d’avoir un port ouvert avec un REPL pour vos applications même en prod si vous le voulez (bien que cela soit une grosse faille de sécurité). Mais c’est possible, et là aussi n’importe quelle fonction pourrait être patchée à chaud. Des gens ont fait des choses formidables comme cela, lisez donc ça par exemple:
An impressive instance of remote debugging occurred on NASA’s 1998 Deep Space 1 mission. A half year after the space craft launched, a bit of Lisp code was going to control the spacecraft for two days while conducting a sequence of experiments. Unfortunately, a subtle race condition in the code had escaped detection during ground testing and was already in space. When the bug manifested in the wild–100 million miles away from Earth–the team was able to diagnose and fix the running code, allowing the experiments to complete.
Etat du REPL
Il me reste un dernier soucis. Le REPL garde son état.
Imaginons que je démarre une application. Je vais pouvoir comme dit précédemment modifier à chaud mon programme, ou définir dans mon REPL des variables ou des fonctions.
Problème: il est facile de se perdre, et d’avoir un doute: est ce que le code dans mon fichier reflète le code qui tourne dans mon REPL ?
Pour cela, il existe des outils comme clojure.tools.namespace. Ces outils, combinés aux librairies de gestion de composants décrites précédemment, permettent de recharger proprement (et quasi instantanément) l’état de votre application. Une fois rechargé, vous avez la garantie que votre REPL est synchronisé avec votre code.
Arrêt d’un système
je parle beaucoup de stopper, ou recharger un système. Cela implique une chose: chaque composant stateful doit pouvoir être démarré et stoppé proprement.
Il arrive encore trop souvent de voir des programmes ne pouvant pas se stopper de manière propre. Cette approche n’est pas possible si l’on veut faire du REPL Driven Development.
C’est d’ailleurs une difficulté, même en Clojure. Certains bugs peuvent vous empêcher de stopper proprement certains composants. Cela casse donc votre workflow de développement. La bonne chose, c’est que cela nous force à faire des trucs propres pour que ça marche ;)
Conclusion
Cette façon de développer a été une des choses qui m’a fait accrocher à Clojure. Cette architecture sous forme de composants, le fait de toujours pouvoir stopper un système gracieusement… est quelque chose qu’il est selon moi nécessaire d’appliquer quel que soit le langage.
Si Clojure vous intéresse, allez donc faire un tour sur https://tour.mcorbin.fr/ :)