Une introduction à Vector
Dans un précédent article, j’avais mentionné Vector comme une technologie qui me faisait de l’oeil. Je ferai un tour rapide de l’outil dans cet article, notamment pour récupérer des métriques, gérer des logs, avec une petite intégration InfluxDB.
Pourquoi utiliser Vector ?
Vector permet de collecter, transformer et transférer entre différents systèmes des logs et des métriques.
Par exemple, vous pouvez avec collecter des logs depuis différentes sources (journald, fichiers…), réaliser des transformations dessus (ajout de labels, transformations diverses) puis transférer tout ça à un système externe comme par exemple Elasticsearch ou Loki.
De la même manière, Vector peut ingérer des métriques (ou même scrap des métriques au format Prometheus comme nous le verrons plus tard), réaliser là aussi au besoin des transformations, et envoyer les métriques dans InfluxDB, Datadog…
Ecrit en Rust, Vector se veut léger et performant. Il peut être utilisé de différentes façons (il est possible de transférer les logs et métriques entre différentes instances de Vector, ce qui permet d’avoir des Vector "agents" et des Vector "centraux" recevant les informations des agents par exemple), s’intègre avec Kafka… Bref, l’outil a l’air très flexible (une section de la documentation explique tout ça).
Cet outil a tout pour me plaire, et cet article montre quelques exemples d’utilisation.
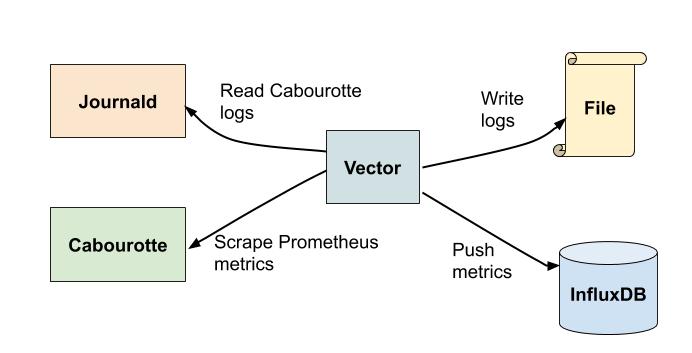
L’architecture que je vais présenter.
Nous allons ici utiliser Vector pour plusieurs choses:
-
Récupérer les logs et les métriques d’une instance de Cabourotte démarrée en tant que service systemd.
Vous ne connaissez pas Cabourotte ? C’est un outil que j’ai conçu pour pouvoir facilement configurer (notamment par API) et exécuter des healthchecks sur votre infrastructure, le tout en fournissant des métriques et logs pertinents. -
Réaliser quelques transformations.
-
Envoyer les métriques à InfluxDB et les logs dans un fichier (il serait possible d’envoyer les logs dans Loki ou Elasticsearch par exemple dans un cas d’utilisation réel).
Note: Je n’ai jamais utilisé InfluxDB 2.0, donc je n’irai pas très loin dans l’utilisation de cet outil.
Démarrer InfluxDB
Téléchargez InfluxDB depuis le site officiel.
Une fois téléchargé et décompressé, vous pouvez le lancer avec la simple commande ./influxd.
Allez ensuite sur http://localhost:8086 pour configurer InfluxDB. J’ai créé dans mon cas une organisation et un bucket appelé mcorbin.
Vous pouvez récupérer également dans cette interface le token InfluxDB.
Démarrer Cabourotte
Les releases de Cabourotte sont disponibles sur Github. Je vais utiliser ici la version 0.7.0 qui est la version la plus récente au moment où j’écris l’article.
Comme dit précédemment, je vais configurer Cabourotte en tant que service systemd. Placez le fichier suivant dans /etc/systemd/system/cabourotte.service
[Unit]
Description=The best tool to execute healthchecks on your infrastructure
After=network.target
ConditionPathExists=/etc/cabourotte/cabourotte.yml
[Service]
DynamicUser=yes
ExecStart=/usr/local/cabourotte/cabourotte daemon --config /etc/cabourotte/cabourotte.yml
Restart=on-failure
[Install]
WantedBy=multi-user.targetInstallez ensuite Cabourotte dans /usr/local/cabourotte et activez le service:
wget https://github.com/mcorbin/cabourotte/releases/download/v0.7.0/cabourotte_0.7.0_Linux_x86_64.tar.gz
sudo mkdir /usr/local/cabourotte/
sudo tar -C /usr/local/cabourotte -xzf cabourotte_0.7.0_Linux_x86_64.tar.gz
mkdir ~/Documents/vector
systemctl daemon-reloadCréons maintenant le fichier de configuration de Cabourotte.
Placez la configuration suivante dans /etc/cabourotte/cabourotte.yml. Vous pouvez retrouver toutes les options disponibles dans la documentation de l’outil.
---
http:
host: "0.0.0.0"
port: 9013
dns-checks:
- name: "dns-mcorbin.fr"
description: "dns healthcheck on mcorbin.fr"
domain: "mcorbin.fr"
interval: 5s
labels:
site: mcorbin.fr
http-checks:
- name: "http-mcorbin.fr"
description: "http healthcheck on mcorbin.fr"
valid-status:
- 200
- 201
target: "mcorbin.fr"
port: 443
protocol: "https"
path: "/"
timeout: 5s
interval: 5s
labels:
site: mcorbin.fr
- name: "http-error-example"
description: "This healthcheck should fail"
valid-status:
- 200
- 201
target: "doesnotexist.mcorbin.fr"
port: 443
protocol: "https"
path: "/"
timeout: 5s
interval: 5s
labels:
site: mcorbin.frNous configurons ici 3 healthchecks:
-
Un healthcheck de type DNS qui devrait s’exécuter correctement.
-
Un healthcheck de type HTTP qui là aussi est censé être réussi.
-
Un autre healthcheck de type HTTP ciblant
doesnotexist.mcorbin.fr. Ce domaine n’existant pas, ce healthcheck doit retourner des erreurs.
Démarrez maintenant le service:
sudo systemctl start cabourotteLe service doit démarrer correctement, et vous devez voir dans les logs (sudo journalctl -eu cabourotte --no-pager) quelque chose comme:
janv. 02 16:40:05 mathieu cabourotte[16652]: {"level":"info","ts":1609602005.3045712,"caller":"exporter/root.go:116","msg":"Healthcheck successful","name":"dns-mcorbin.fr","labels":{"site":"mcorbin.fr"},"date":"2021-01-02 16:40:05.304543995 +0100 CET m=+65.311308786"}
janv. 02 16:40:05 mathieu cabourotte[16652]: {"level":"error","ts":1609602005.3066423,"caller":"exporter/root.go:122","msg":"healthcheck failed","name":"http-error-example","labels":{"site":"mcorbin.fr"},"cause":"HTTP request failed: Get \"https://doesnotexist.mcorbin.fr:443/\": dial tcp: lookup doesnotexist.mcorbin.fr on 192.168.1.1:53: no such host","date":"2021-01-02 16:40:05.30661737 +0100 CET m=+65.313382168","stacktrace":"cabourotte/exporter.(*Component).Start.func2\n\t/home/mathieu/prog/go/cabourotte/exporter/root.go:122\ngopkg.in/tomb%2ev2.(*Tomb).run\n\t/home/mathieu/prog/go/cabourotte/vendor/gopkg.in/tomb.v2/tomb.go:163"}
janv. 02 16:40:05 mathieu cabourotte[16652]: {"level":"info","ts":1609602005.3296578,"caller":"exporter/root.go:116","msg":"Healthcheck successful","name":"http-mcorbin.fr","labels":{"site":"mcorbin.fr"},"date":"2021-01-02 16:40:05.329629923 +0100 CET m=+65.336394717"}Cela me fait d’ailleurs penser que je devrais changer ces logs pour montrer un timestamp plutôt qu’une date formattée à la Golang.
Vector
Téléchargez Vector sur le site officiel. Vector peut se configurer en YAML, TOML ou JSON. Dans cet exemple je le configurerai en YAML.
Toutes les options de configuration sont disponibles ici. L’outil est assez récent mais il est déjà possible de faire des tonnes de trucs avec.
Mon fichier vector.yaml contient:
data_dir: /home/mathieu/Documents/vector
sources:
cabourotte_prometheus:
type: prometheus_scrape
endpoints:
- http://127.0.0.1:9013/metrics
scrape_interval_secs: 15
cabourotte_logs:
type: journald
current_boot_only: true
exclude_units: []
include_units: ["cabourotte"]
transforms:
journald_json:
type: json_parser
inputs:
- cabourotte_logs
drop_field: true
drop_invalid: true
field: message
log_fields:
type: add_fields
inputs:
- journald_json
overwrite: true
fields:
environment: "prod"
location: "ch-gva-2"
metric_tags:
type: add_tags
inputs:
- cabourotte_prometheus
overwrite: true
tags:
environment: "prod"
location: "ch-gva-2"
sinks:
influxdb:
type: influxdb_metrics
inputs:
- metric_tags
bucket: mcorbin
default_namespace: service
endpoint: http://localhost:8086/
org: mcorbin
token: "wlJqadZ9yLdMHDpifDhSKzwej-neZ2mrF-vp955w7nZY1lJAGKP7dRiiZtYSOuh82e63zYN_IPodBWQ2XO29mw=="
healthcheck: true
file:
type: file
inputs:
- log_fields
compression: none
path: "/tmp/vector-%Y-%m-%d.log"
encoding:
codec: ndjson
healthcheck: trueLa configuration data_dir est un chemin vers un répertoire utilisé par Vector pour stocker des metadatas.
Maintenant, lancez Vector avec sudo ./vector --config ~/vector.yaml (j’utilise sudo pour que la source journald fonctionne).
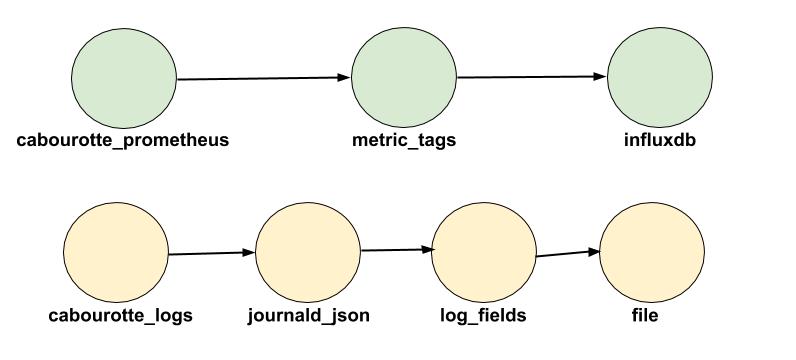
Sources
-
La partie
sourcescontient les différentes sources pour les logs et métriques. Nous avons ici deux sources.
Une va récupérer les métriques exposées par Cabourotte au format Prometheus. Vector ira donc récupérer ces métriques toutes les 15 secondes.
Une autre source va récupérer les logs de Cabourotte depuisjournald. Vous pourriez modifier cette source pour récupérer automatiquement les logs toutes les units de votre système.
Transforms
Une fois que les sources sont configurées, Vector peut réaliser des transformations dessus.
Une première transformation appelée journald_json se charge de transformer en json les logs de journald. En effet, voici ce qu’on obtiendrait sans cette transformation:
{
"PRIORITY": "6",
"SYSLOG_FACILITY": "3",
"SYSLOG_IDENTIFIER": "cabourotte",
"_BOOT_ID": "051a2c4dc6f74a238d257030efa2b3f1",
"_CAP_EFFECTIVE": "0",
"_CMDLINE": "/usr/local/cabourotte/cabourotte daemon --config /etc/cabourotte/cabourotte.yml",
"_COMM": "cabourotte",
"_EXE": "/usr/local/cabourotte/cabourotte",
"_GID": "64171",
"_MACHINE_ID": "f8de18ca659543f08aa82967a944fde0",
"_PID": "16652",
"_SELINUX_CONTEXT": "unconfined\n",
"_STREAM_ID": "4f4bbd77076b464799455c1fd9d634dd",
"_SYSTEMD_CGROUP": "/system.slice/cabourotte.service",
"_SYSTEMD_INVOCATION_ID": "869cef96790a4fc99cbe81f54bc7b986",
"_SYSTEMD_SLICE": "system.slice",
"_SYSTEMD_UNIT": "cabourotte.service",
"_TRANSPORT": "stdout",
"_UID": "64171",
"__MONOTONIC_TIMESTAMP": "92565244358",
"__REALTIME_TIMESTAMP": "1609607085328622",
"host": "mathieu",
"message": "{\"level\":\"info\",\"ts\":1609607085.3284657,\"caller\":\"exporter/root.go:116\",\"msg\":\"Healthcheck successful\",\"name\":\"http-mcorbin.fr\",\"labels\":{\"site\":\"mcorbin.fr\"},\"date\":\"2021-01-02 18:04:45.328370895 +0100 CET m=+5145.335135914\"}",
"source_type": "journald",
"timestamp": "2021-01-02T17:04:45.328622Z"
}Grâce à la transformation précédente, le json présent dans le champ "message" sera transformé. Nous verrons ce que ça donne un peu plus loin.
Note: Les champs autres que message sont automatiquement ajoutés par Vector.
Nous avons ensuite deux autres transformations: log_fields et metric_tags.
Ces deux transformations réalisent la même action mais sur deux types de données différentes (logs et métriques).
-
log_fieldsva récupérer la sortie de la transformationjournald_jsonet rajouter les clésenvironmentetlocationau message. Le choix de ces clés sont totalement libres. -
metric_tagsfait la même chose mais pour les métriques venant de Cabourotte. Les tagsenvironmentetlocationsont ajoutés aux métriques.
Sinks
Il est maintenant temps de transférer tout ça à des systèmes externes.
Le sink influxdb récupèrera la sortie de metric_tags et enverra les métriques dans l’instance InfluxDB configurée précédemment.
Le sink file récupérera les logs de log_fields et les ajoutera dans un fichier (le nom du fichier sera en fonction de la date du log).
En résumé, voici ce que nous faisons:
Résultat
Métriques
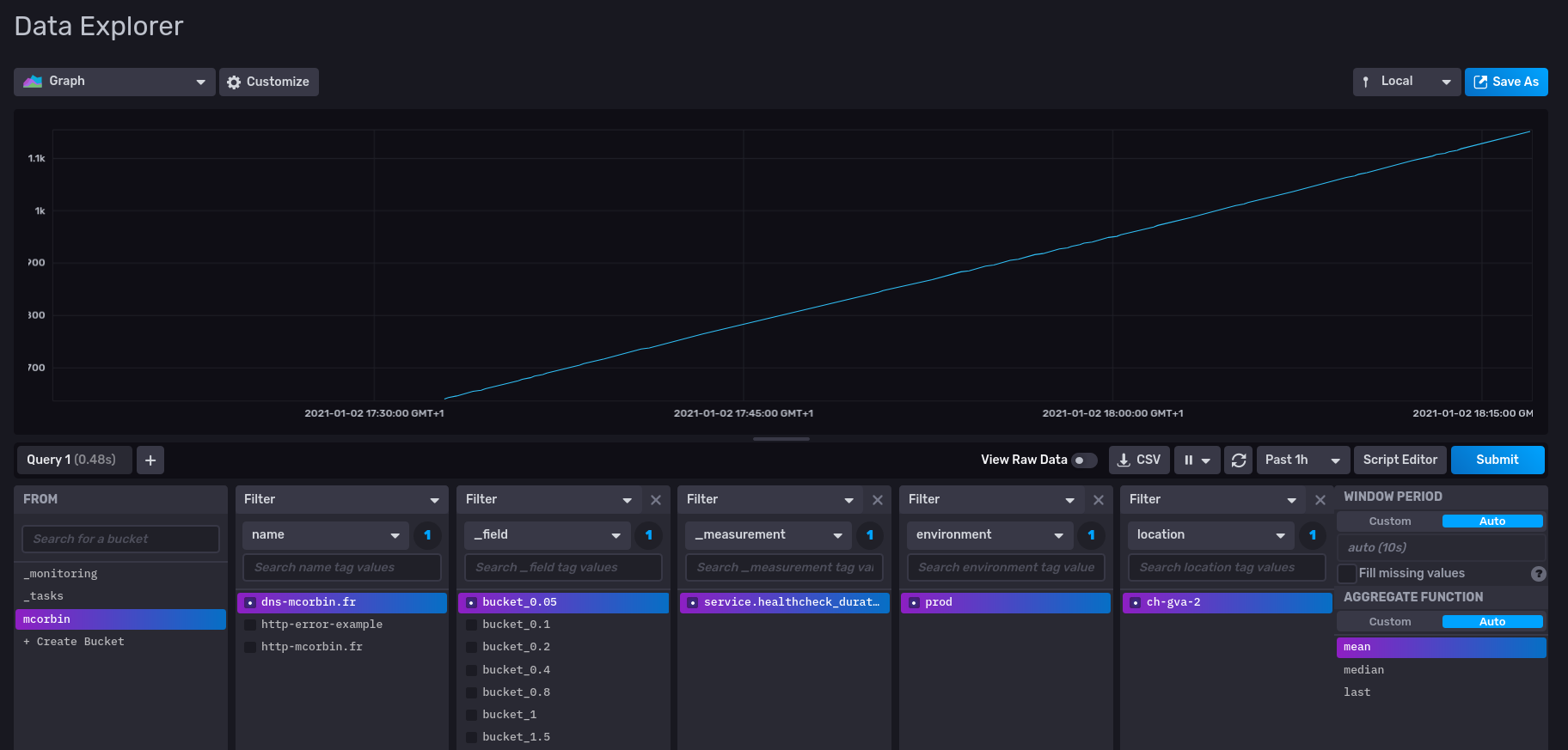
Mes métriques (ici la valeur d’un bucket, d’où l’augmentation perpétuelle) sont bien visibles dans InfluxDB. On voit que mes tags environment et location ont été ajoutés aux métriques.
Logs
Mes logs sont bien visibles dans /tmp/vector-2021-01-02.log. Par exemple:
{
"PRIORITY": "6",
"SYSLOG_FACILITY": "3",
"SYSLOG_IDENTIFIER": "cabourotte",
"_BOOT_ID": "051a2c4dc6f74a238d257030efa2b3f1",
"_CAP_EFFECTIVE": "0",
"_CMDLINE": "/usr/local/cabourotte/cabourotte daemon --config /etc/cabourotte/cabourotte.yml",
"_COMM": "cabourotte",
"_EXE": "/usr/local/cabourotte/cabourotte",
"_GID": "64171",
"_MACHINE_ID": "f8de18ca659543f08aa82967a944fde0",
"_PID": "16652",
"_SELINUX_CONTEXT": "unconfined\n",
"_STREAM_ID": "4f4bbd77076b464799455c1fd9d634dd",
"_SYSTEMD_CGROUP": "/system.slice/cabourotte.service",
"_SYSTEMD_INVOCATION_ID": "869cef96790a4fc99cbe81f54bc7b986",
"_SYSTEMD_SLICE": "system.slice",
"_SYSTEMD_UNIT": "cabourotte.service",
"_TRANSPORT": "stdout",
"_UID": "64171",
"__MONOTONIC_TIMESTAMP": "93010244891",
"__REALTIME_TIMESTAMP": "1609607530329156",
"caller": "exporter/root.go:116",
"date": "2021-01-02 18:12:10.329118217 +0100 CET m=+5590.335882993",
"environment": "prod",
"host": "mathieu",
"labels": {
"site": "mcorbin.fr"
},
"level": "info",
"location": "ch-gva-2",
"msg": "Healthcheck successful",
"name": "http-mcorbin.fr",
"source_type": "journald",
"timestamp": "2021-01-02T17:12:10.329156Z",
"ts": 1609607530.3291318
}On voit que mon champ message a disparu (les clés et valeurs ont été fusionnées au json principal), et environment et location ont bien été ajoutés à mon log.
Tester sa configuration.
Fait intéressant, il est possible de tester sa configuration. Ajoutez par exemple à la fin de votre configuration:
tests:
- name: "test-logs"
inputs:
- insert_at: journald_json
type: log
log_fields:
message: "{\"foo\": \"bar\"}"
outputs:
- extract_from: "log_fields"
conditions:
- environment.equals: "prod"
location.equals: "ch-gva-2"
foo.equals: "bar"Ici, on définit un test qui injectera le message "{\"foo\": \"bar\"}" à l’étape journald_json.
On vérifie ensuite qu’à la sortie de l’étape log_fields les clés environment et location ont été ajoutées, et on vérifie également que la clé foo du message en json a été insérée.
Vous pouvez maintenant lancer les tests:
./vector test ~/vector.yaml
Running /home/mathieu/vector.yaml tests
test /home/mathieu/vector.yaml: test-logs ... passedConclusion
Vector permet de faire beaucoup plus, mais je ne voulais pas que cet introduction à l’outil soit trop lourde. Il est même possible d’exécuter du lua ou bien d’utiliser la fonction remap pour réaliser des transformations complexes.
Le fait de pouvoir tester sa configuration est un gros plus, à voir ensuite à l’usage jusqu’à quel niveau les choses sont testables (je n’ai pas poussé le système dans ses retranchements).
Je n’ai par contre pas trouvé si il était possible d’inclure un fichier de configuration dans un autre. Cela serait très utile car je pense que les configurations peuvent vite devenir plus verbeuses. Cela permettrait aussi d’avoir des fichiers consacrés aux logs et d’autres aux métriques par exemple.
Je n’ai pas également trouvé si il était possible de générer le graphe des différentes transformations. Ce serait également intéressant sur des configurations complexes (un peu comme terraform graph).
Il existe également une intégration Kubernetes pour notamment récupérer les logs de conteneurs, mais je testerai cela dans un article dédié.
Vector est vraiment un outil intéressant. Le fait de pouvoir manipuler mes logs et métriques dans le même outil est un gros plus. Et avec lua de disponible, je sais que je pourrai répondre même à des besoins complexes non prévus par la configuration de base.
Etant en train de réfléchir à reconstuire complètement mon infrastructure personnelle hébergeant plusieurs sites web et applications, cela me donnera une excuse pour le tester dans un vrai contexte (notamment avec du Kubernetes).