I started working one month ago on a new stream processing engine heavily inspired by Riemann. The project (named Mirabelle) is still in alpha state (but it starts/works), but I would like to explain what I try to achieve with this tool.
Riemann
I discovered Riemann I think in 2015, and was immediately hooked (and contributed a lot to it at some point). The tool is amazing, well designed, and is full of good ideas:
-
Configuration as code: I’m not speaking about YAML, TOML… here, the Riemann configuration is real Clojure code. The DLS and the built it integrations (Pagerduty, InfluxDB, Graphite, Elasticsearch…) were enough for a lot of use cases, but it’s super easy to write real code to extend the project if needed.
After working with Riemann and its infinite possibilities, it’s hard to work with limited DSL in other monitoring tools. -
Good performances (JVM + Netty).
-
Easy to deploy
-
Super useful: using Riemann to route events to external systems while doing computations on the stream of events (real time computation of rates, percentiles, detecting patterns by correlating events between multiples hosts and systems, sending alerts…) is amazing.
If you are interested by Riemann, I encourage you to watch Aphyr’s talk about it at Monitorama 2015.
Clients are pushing events to Riemann. An event has some fields:
service: The measurement name, likecpu_percent,http_request_second…time: The event time.tags: A list of tags, for example["monitoring", "database"].ttl: A field indicating how long this event should be considered valid. It’s used internally to expire events in some computations.state: the event state (ok,warning, orcritical)- Additional keys, like
host, or custom ones, can be added.
All of these fields are optional.
This format is very flexible. Riemann clients use protobuf, so performances are also good.
Push has for me several advantages compared to pull for monitoring systems. First, I think push-based systems, especially combined with tools like Kafka, are open systems.
You can route events to various databases, cloud services… Want to try InfluxDB ? Deploy it, add a new rule to Riemann to forward events to it, and test it. Want to try Datadog ? Same. You want to send specific events in one tool and the others in another ? Easy ! Data are availables, even more with Kafka where everyone can write its own consumer.
It’s also simpler to operate: one firewalling rule to open between your hosts/services and your Riemann (or Kafka if you use it as a buffer for example) instance. Compared to today’s "best practices" where you have 10 HTTP servers exposing metrics per host scrapped periodically (and all the network configuration mess it involves), it’s refreshing.
I would like to thank all the people involved into Riemann (for example Kyle Kingsbury aka Aphyr, the original Riemann author, James Turnbull, another Riemann maintainer which also wrote a book about it) and its ecosystem.
It’s crazy how this tool evolved (the project itself but also the tooling: you can find Riemann integrations or Riemann clients a bit everywhere) without being backed by a company. I think it speaks about the tool quality, and shows that open source tools maintained by individuals can still have an impact.
For the anecdote, I started to work at Exoscale almost 3 years ago because Pierre-Yves Ritschard, another Riemann contributor, proposed me to join the company. Thinking about it, Riemann is probably the piece of software which had the biggest impact on my career (met a lot of cool people, learned a lot about monitoring, Clojure, stream processing engines…).
I do not contribute to Riemann anymore for a while. I still like the tool, but I had at some point the feeling that everything I could have done for the project was done, and that bringing Riemann to the next level would need a rewrite.
Let’s see what are currently the Riemann pain points for me.
What could be improved in Riemann
As I said, in Riemann the configuration is code. Real code. Your configuration file is a valid Clojure program which is evaluated at runtime by Riemann. It’s nice but it also brings several issues.
Streams states on reloads
When Riemann is reloaded (for example, you update its configuration and send a SIGHUP), the configuration is evaluated again but all existing states are lost.
For example, if you were working with time windows, doing computations on group of events… all of this would be lost, and new events (after the reload) would not have any knowledge of the old states.
In practice, it’s an issue if you reload your configuration often. For a lot of use cases it was not important, but for some of mine it was an issue. It would be nice to only reset streams which were updated.
I/O and stateful objects directly created in streams
As I said before, you can in Riemann forward events to timeseries databases, cloud services, send alerts to Pagerduty… In short, perform side effects. These clients usually have stuff like threadpools etc… which should be correctly initialized and stopped if needed.
In Riemann, these kind of clients are also directly initialized and used inside streams, and it was hard to manage them cleanly, especially on reloads.
Event time vs scheduler
In Riemann, some streams perform actions based on the events time, but some also use a scheduler to execute tasks periodically.
For example, some time windows streams use the events time to know when a window is closed. If you have a 60 seconds window, you could consider the window closed if an event arrives at start of the window + 60. But other streams would use the scheduler to periodically flush states (windows for example) every N seconds (flushing events every N seconds, no matter what is received).
Having two ways to manage the time was an issue. It was sometimes difficult to understand exactly the outputs of some streams because of that, and simulating the scheduler side effects complicated the unit test framework (yes, in Riemann, you can write unit tests to test your streams to me sure about your computations and alerting rules, which is super nice).
This and a couple of small issues motivated me to try to write a new tool heavily inspired by Riemann, using the same protocol/event format, which feels like Riemann but with more capabilities.
Mirabelle
My tool named Mirabelle is still a work in progress, but I will explain the ideas behind it and how it differs compared to Riemann. It should be noted that parts of the code were directly taken from Riemann, and that Mirabelle is also licensed under EPL, like Riemann. Again, I would like to thank all Riemann contributors.
An intermediate, serializable representation of streams
As I said, in Riemann, the configuration is a real Clojure program. Mirabelle mimics the Riemann DLS (I already reimplemented or backported tons of actions) but actually produces an edn representation of the streams. An example with a Mirabelle stream:
;; keep only events with service = "ram_percent"
(where [:= :service "ram_percent"]
;; split children actions by host, each children being independant
(by [:host]
;; check if the event metric is > 90 (so 90 %) during more than 30 sec
(above-dt 90 30
;; set the state to critical
(with :state "critical"
;; only send one event every 30 minutes to downstream systems
;; to avoid generating too many alerts for example
(throttle 1 1800
;; log the message (could be forwarded to pagerduty for example)
(error))))))
If you look at the Riemann howto, this configuration looks like Riemann. But actually, in Mirabelle, this code only produces an edn datastructure, it does not evaluates to a function like in Riemann. The edn generated is:
{:action :where,
:params [[:= :service "ram_percent"]],
:children
({:action :by,
:params [[:host]],
:children
({:action :above-dt,
:params [[:> :metric 90] 30],
:children
({:action :with,
:children
({:action :throttle,
:params [1],
:children (1800 {:action :error, :children nil})}),
:params [{:state "critical"}]})})})}
You can easily understand the structure while comparing it to the DSL. Each step contains an :action key, (optional) parameters, and (optional) children.
Another example:
;; imagine we gather events representing the duration of a job
(where [:= :service "job_execution_time"]
;; create a 120 second time window for all events
(fixed-time-window 120
;; compute quantiles about them (like that, you have quantiles for all of your hosts grouped together)
(percentiles [0.5 0.75 0.98 0.99]
;; log (could be forwarded to a TSDB for example)
(info)))
;; in another action, split everything by host
(by [:host]
;; for each host, create a 120 second time window
(fixed-time-window 120
;; compute the percentiles for each host independently on the windows results
(percentiles [0.5 0.75 0.98 0.99]
;; log
(info)))))
As you can see, like in Riemann, it’s OK to have various computations/actions running in parallel (in differents "branches") for the same event because of the amazing Clojure persistent datastructures. No side effects between actions, never, even between threads. You choose what should be forwarded to downstream systems, what should be computed, and for the same events several actions can be done.
The generated edn is:
{:action :where,
:params [[:= :service "job_execution_time"]],
:children
({:action :coalesce,
:children
({:action :percentiles,
:params [[0.5 0.75 0.98 0.99]],
:children ({:action :info, :children nil})}),
:params [60 [:host]]}
{:action :by,
:params [[:host]],
:children
({:action :fixed-time-window,
:params [120],
:children
({:action :percentiles,
:params [[0.5 0.75 0.98 0.99]],
:children ({:action :info, :children nil})})})})}
This edn can then be "compiled" into functions on which you can inject events (it’s done automatically for you when you send events to the Mirabelle TCP server).
Having this edn repsentation brings several things:
- Streams configurations can be compared. On a reload, Mirabelle will compare them and only reload streams which were changed. No more state loss between reloads like in Riemann.
- They can be used by Mirabelle to dynamically create streams instances. I will talk about it later, but Mirabelle has an API to dynamically create streams based on a configuration passed by an HTTP request for example.
- The configurations can be validated (I actually do it using Clojure spec), statically analyzed. For example, I will soon work on a tool to draw (using gnuplot for example) the streams graphes based on the configurations.
I think having this format between the DSL and Mirabelle is a huge win.
IO at clearly identified, and managed outside of streams
As I said before, in Riemann I/O are directly created inside streams, and can be difficult to manage.
In Mirabelle, I/O are clearly identified and have their own lifecycles. They are also defined as edn, and the I/O configurations should live in dedicated files. Here is an example I/0 which will write events into a file.
{:file-example {:config {:path "/tmp/events.edn"}
:type :file}}
You can then use it into a stream:
(where [:= :service "ram_percent"]
(push-io! :file-example))
;; this example would generate this edn configuration:
{:action :where,
:params [[:= :service "ram_percent"]],
:children ({:action :push-io!, :params [:file-example]})}
Here, my stream will write into the file "/tmp/events.edn" all events with service ram_percent. You see that I reference the I/O by name into push-io! in order to do that. The stateful I/O object (imagine a timeserie client using a threadpool, or more complex examples) are injected by Mirabelle when the stream is compiled.
Multiple streams can use the same I/O. In Mirabelle, I/O are easy to maintain (start, stop, share between streams).
Streams in Mirabelle always use the events time
As I said before, some streams in Riemann use a scheduler to periodically do action (flushing time windows for example).
In Mirabelle, all streams use the events time as a source of truth. It means streams will always produce the same output for a given list of input events.
It has several advantages:
- Easier to unit test and to reason about (yes, you can test everything in Mirabelle, by writing tests which create your stream, and then you inject events into it, and check the outputs).
- Easier to maintain (no global side effects in streams).
- You can in Mirabelle have various streams, each one advancing at its own pace (each one will advance depending of the time of the received events).
Let’s develop the third point a bit more, and discuss a bit about stream processing in general.
In stream processing engines, events can arrive out of order, especially if you aggregate and do computations on events arriving from multiple sources.
If you have a host pushing every 10 seconds events, and if you write a stream which will for example create time windows only for this host, most of the time events will arrive in order (or else it means someone modified the host clock :D).
In Mirabelle/Riemann, you can even use the by action to create computation per host (you can check the previous example in this article), and so compute things for each host (or other label) in isolation.
But sometimes, you want to aggregate data from multiple hosts. In that case, you don’t have any guarantee on the events order (because even if the hosts clocks are synchronized, some events from some hosts will arrive first).
The Riemann philosophy is mostly correct information right now is more useful, than totally correct information only available once the failure is over.
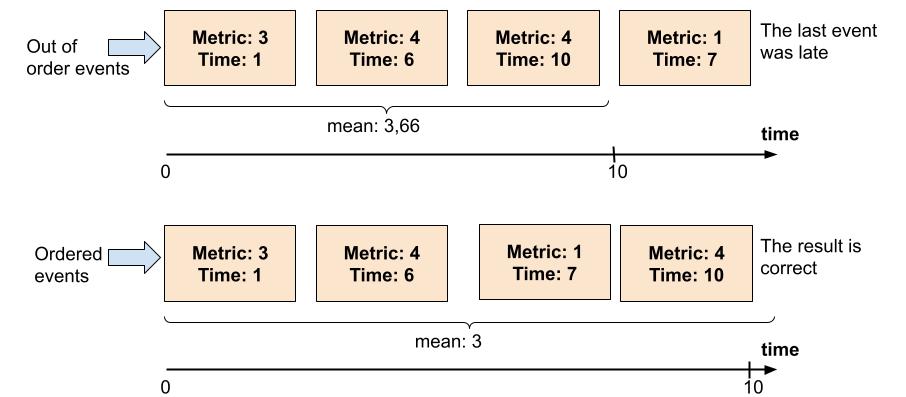
Of course, these issues can be mitigated by having moving time windows for example, in order to allow events to arrive a bit late (a bit depending of the stream configuration). But at some point, old events are lost.
What could we do to solve this issue ? Unfortunately, we have to live with this trade-off in real time stream processing engines. We could try to "wait", buffer events for a while, sort them by timestamp, and then perform the computations. You could easily write a stream to do that in Mirabelle.
But what if we could replay all events, in order, and on demand ? Mirabelle allows that.
In Mirabelle, some streams from the configuration are used by default for events received by the TCP server. But you can also create streams (from the configuration, or dynamically using the API, remember, streams are just edn), and add a label to events to push them into these dedicated streams.
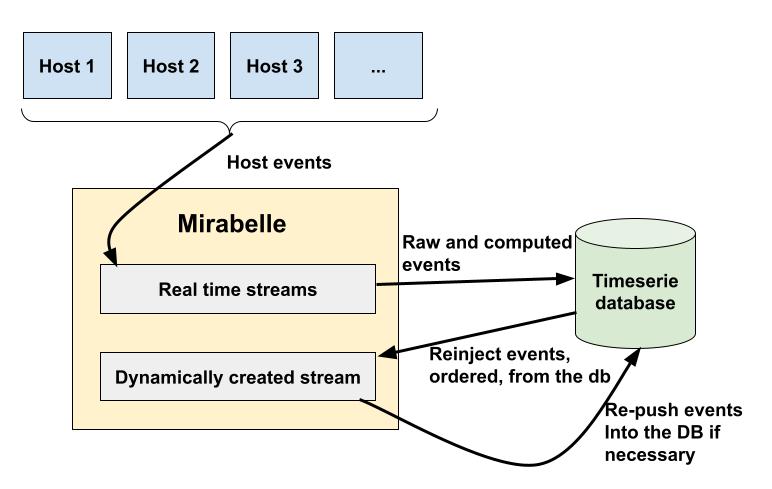
In this schema, events arrive into Mirabelle and are then pushed into a timeserie database. You could already perform real-time computations on the events in order to quickly alert on some patterns.
Then, you can at any time create (or use an existing one) a stream into Mirabelle, do a query on your timeserie database (like, give me the events for these series from yesterday between 5AM and 9AM, in order), and inject these events into the stream.
Remember, in Mirabelle, each streams has its own view of the time. It’s OK to have one stream working on real time events, and another working on events from yesterday for example. Streams work in isolation.
That way, you can if needed perform new computations on your events, do tests (for example, if you want to define a threshold for alerting, you could replay last week events to see how many alerts would be triggered), or even move data between systems.
An example using the API:
{"config": "ezphY3Rpb25zIHs6YWN0aW9uIDpzZG8sCiAgICAgICAgICAgOmNoaWxkcmVuCiAgICAgICAgICAgKHs6YWN0aW9uIDp3aGVyZSwKICAgICAgICAgICAgIDpwYXJhbXMgW1s6PiA6bWV0cmljIDMwXV0sCiAgICAgICAgICAgICA6Y2hpbGRyZW4KICAgICAgICAgICAgICh7OmFjdGlvbiA6aW5jcmVtZW50LAogICAgICAgICAgICAgICA6Y2hpbGRyZW4KICAgICAgICAgICAgICAgKHs6YWN0aW9uIDplcnJvcgogICAgICAgICAgICAgICAgIDpwYXJhbXMgW10sCiAgICAgICAgICAgICAgICAgOmNoaWxkcmVuIG5pbH0pfSl9KX19Cg=="}
The config key contains the base64 representation of a stream. I can then create dynamically a stream named bar into Mirabelle:
curl -X POST --header "Content-Type: application/json" localhost:5666/api/v1/stream/bar --data @payload.json
Now, I can send events to this stream by setting the stream attribute to bar on a Riemann client:
riemann-client send --host my-host --service bar --metric-d 35 --attribute=stream=bar 127.0.0.1 5555
This event will only be received by the stream named bar, not by other streams. As I said before, you could do the same thing with streams configured in the configuration file. Some could be used for real-time stream processing, others for another use case. You could even have multiple Mirabelle instances, some focused on real-time computations, and the other ones on old data.
Being able to do it thought the API is nice. You can create a stream, compute stuff, and then delete it once the computation is over. And by sending ordered events, you know the stream result will be 100 % correct.
Now, let’s talk a bit more about Mirabelle internal states.
Replaying events
As I said, Mirabelle will not lose its states (time windows for example) during a restart. But what if the process crashes ? If you bufferize events for 5 minutes and that the process crashes after 4 minutes, you will lose 4 minutes of events.
The first answer is (and it’s the Riemann one): we don’t care. New events will rebuild the state, but the old window is lost.
You could also have this approach in Mirabelle, and for example rerun the raw events (from your TSDB) in a dynamically created stream in order to recompute the result for this window.
A third solution could be to save the Mirabelle streams states somewhere (on disk, on a database…). It’s possible (and could be implemented if needed for some streams), but performances will not be good if you have to persist tons of states for every event. You could only save the internal states periodically (every 5, 10, or 30 sec for example) to limit the impact of the crash, but in that case you will also lose events (the last N seconds) during a crash.
A last solution, which I just implemented in Mirabelle, is to replay the last N minutes of events when the process starts, discarding I/O, in order to rebuild the internal states.
In Mirabelle streams, you can call (write!) in order to persist your events on disk, into a Chronicle queue.
A chronicle queue is a bit like a Kafka topic but stored on your local disk. You can write data on it, or re-read it from the beginning or from a specific offset. Chronicle queue are also periodically rotated (it’s configurable, it could be every minute, every hour, every two hours…). You could even back them up somewhere to keep your events history.
When Mirabelle starts, it will re-read automatically all the data from the queue configured in its configuration, but will also add to the events a discard tag. Events tagged discard will be automatically removed from I/O actions in Mirabelle. It means these events will just be reinjected (in the order they are in the queue) into the streams to rebuild their internal states.
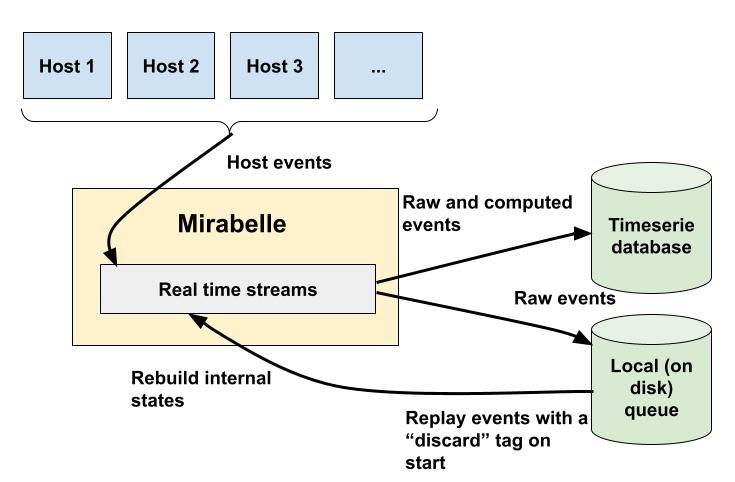
I’m still playing with this mechanism, because for huge queues re-reading everything can take a while. But I’m confident reinjecting the last 5, 10, or 20 minutes of events will be enough for 99 % of the use cases and should have good performances.
High availability
For now, Mirabelle is only a mono-node project. It could indeed be an issue, but history (and Prometheus) shows us that people do not actually care about HA setup, and that running the thing in two machines in parallel may be enough for a lot of use cases.
You could indeed forward events to two Mirabelle instances (like that, if one fails, the other will continue to compute things on your events).
A lot of people were also using Kafka with Riemann, you could also do that with Mirabelle. By using Kafka and the Mirabelle queue feature to rebuild streams states, you can really have a solid solution.
I’m still thinking about how Mirabelle can be distributed (sharding events between instances or stuff like that), but for now I prefer to not go down the distributed system rabbit hole. I know it’s a trap. IMO, Kafka or duplicating the stream of events is a good solution.
In Memory database
EDIT 05/09/2021: Actually, I was not satisfied of the design of the in memory DB. I decided to remove it for now, and reimplemented the Riemann Index. I will rework on that later.
Riemann provides an index to keep in memory the latest event for each host and service pair. This was not ported to Mirabelle.
Indeed, I think users should be able to put in memory the last N minutes (or hours) of events, on demand, and then do computations (combined with dynamic streams for example) on them. I actually already implemented quickly something:
(where [:= :service "ram_percent"]
(index! [:host]))
In this example, I will save in memory all events for the service ram_percent, indexed by host. It means I will have a new serie in memory per host for the service ram_percent. I can then query these data using the API.
These data are stored in memory in a dedicated datastructure per serie, in order. The implementation is not that good for now but it seems to work.
Storing data in order allows me to asks for data between two times for example, without performance issues. It will also offer the guarantee that the data are ordered if reinjected into a stream. This in-memory database is also rebuilt using the queue, exactly like internal streams states, accross restarts.
Data in memory are automatically removed after a while. For example, you could say "keep only the last 2 hours of data", and old data will be removed once expired. Having hot data, in memory, always availables (and rebuildable after a crash thanks to the queue), with (in the future) a nice way of querying/executing actions on them will be super useful.
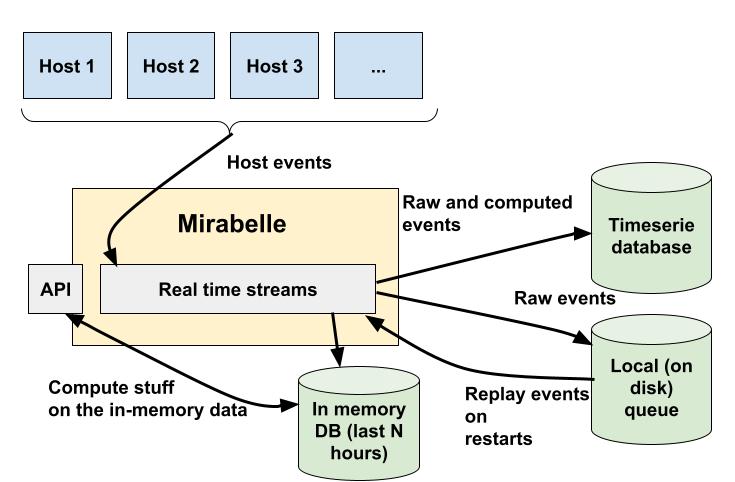
You could for example do real-time actions on your events (relabelling, clean them, perform small computations…), forward them to a TSDB for long term storage, but also put them in memory in order to execute alerting queries on the last N hours of data for example.
I could even integrate a Clojure REPL on the project, to let you explore the in-memory data, create dynamic streams, and compute stuff from it !
The only thing I have to check is how many events I can store in memory before running ouf of RAM ;)
Future work
So, I have on disk a queue where events are persisted in the order they arrived on the system, sorted data per series in memory, and a way to rebuild the Mirabelle states (including the in-memory data) from the queue.
The queue could be considered like a Write-ahead log, the sorted in-memory datastructures could be a poorly-implemented memtable… Am I writing a database ?
it’s not my goal for the moment (I will focus on the stream processing engine and I don’t have all the knowledges needed to write a database), but it can actually be a fun exercice in the future.
Conclusion
This article is way longer than expected. I hope at least a couple of people will read everything, if it’s the case for you, well done ;)
In the next few weeks, I will try to publish an usable version of the project, with some doc to get started. I will also add some basic integrations (Graphite, InfluxDB, Pagerduty…), and work more on the in-memory database. I would like to do also some benchmarks on real use cases.
I spoke a lot about metrics and events in this article, but logs could also be handled by the tool I think.
Currently, users cannot provide custom actions. I will allow that in a near future, so you will be able to code everything you want and integrate it into Mirabelle.
Stay tuned !