Beaucoup d’admin système opposent des technologies mais oublient de parler du plus important: la plateforme.
Une histoire d’abstraction
J’ai déjà discuté de ce sujet dans mon article de décembre 2021 sur le métier d’ops en 2022. Mon article sur Kubernetes: pourquoi, pour qui, fiabilité, lock-in est lui aussi en lien avec ce sujet.
Pour résumer, on voit apparaître de grandes tendances depuis un moment maintenant dans les entreprises produisant du logiciel (qui sont de plus en plus nombreuses, software is eating the world), notamment:
- L’autonomie des développeurs jusqu’à la production, ces derniers ayant par exemple la main sur le déploiement et le monitoring de leurs applications en production.
- Le fait de pouvoir déployer souvent, rapidement, à tout moment, et de manière fiable. Une entreprise qui ne sait pas déployer souvent et rapidement est une entreprise qui perd de l’argent et finira par se faire dépasser par la concurrence.
- L’automatisation de nombreux aspects de l’infrastructure au sens large.
Ces points et et de nombreuses autres choses que l’on attend d’une infrastructure morderne sont rendus possible par une chose: du logiciel fournissant une abstraction de l’infrastructure. Pourquoi ? Car cela serait une énorme perte de temps et une grande source d’erreurs de laisser des humains gérer toutes les actions à réaliser en production. On laisse donc des logiciels s’en charger.
Prenons un exemple d’infrastructure classique: plusieurs instances d’une application derrière un load balancer.
Comme dit précédemment, les développeurs doivent êtres autonomes sur le déploiement de cette application: spécifier la version voulue en production, sa configuration (variables d’environnement, fichiers de configuration, ressources allouées, définition de health-checks pour vérifier sa santé, ports à ouvrir), le nombre d’instances de l’application, éventuellement des règles d’autoscaling pour automatiquement démarrer de nouvelles instances en cas de forte charge sur l’infrastructure…
Il découlera nécessairement lors du déploiement d’une nouvelle version de cette application plusieurs actions dont le but est de n’avoir pas de temps d’indisponibilité du service durant la mise à jour. Une procédure classique est par exemple de faire un rolling update des instances de l’application:
- On a par exemple 3 instances, on va en déployer une quatrième avec la nouvelle version.
- Une fois cette nouvelle version correctement démarrée, on va terminer de manière propre une instance de l’ancienne version: une stratégie classique est par exemple d’arrêter d’envoyer de nouvelles connexions à cette instance mais de continuer à traiter les existantes pour ne pas interrompre les requêtes en cours. L’application est ensuite arrêtée quand elle ne fait plus rien.
- On répète cette procédure jusqu’à ce que toutes les instances soient mises à jour.
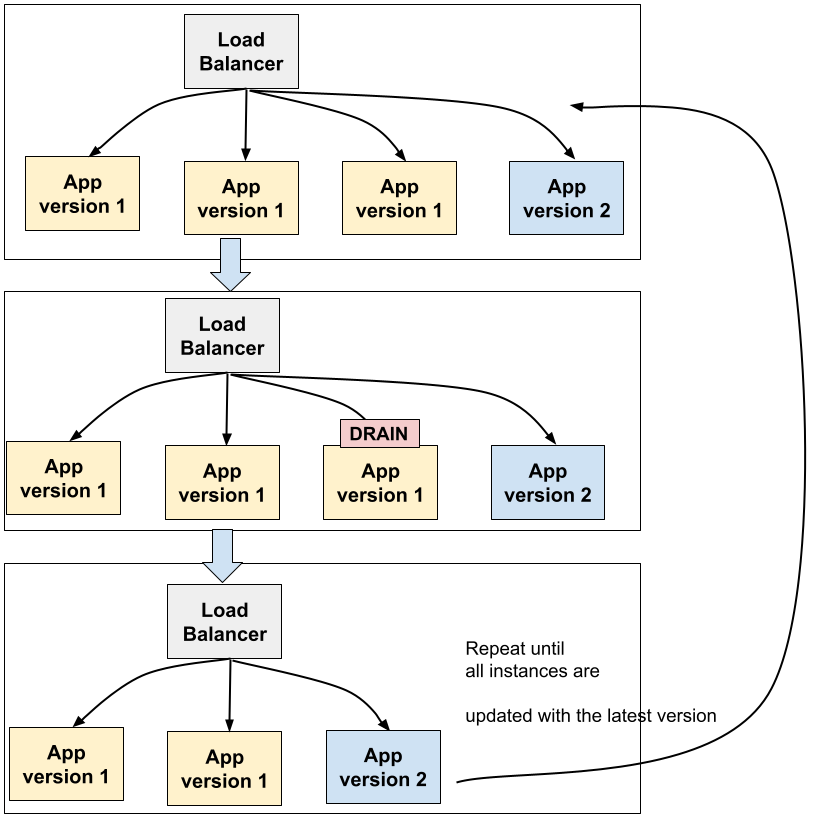
Il existe d’autres stratégies de déploiement (canary release par exemple) mais l’idée est toujours la même: on démarre et arrête des instances et on joue sur le réseau pour amener ou non du trafic vers ces instances.
Une application fait partie d’un écosystème: chaque nouvelle instance de votre application doit être monitorée, vous avez besoin d’injecter des secrets dans vos fichiers de configuration, ou encore vous devez être certain que le firewalling entre votre nouvelle instance et des services tiers (base de données, autres applications) est correctement configuré dès le démarrage de la nouvelle instance…
De la même manière, l’infrastructure doit réagir en cas de panne d’une application, on doit pouvoir facilement rollback un changement. Et je pourrai continuer encore longtemps comme ça en donnant d’autres exemples de choses importantes. Bref, je pense que vous voyez où je veux en venir.
Une action qui peut sembler simpliste est au final plus compliquée de prévu lorsqu’on veut la réaliser correctement. On voit que plusieurs services somt impliqués et doivent se coordonner. Et cette action doit pouvoir être réalisée autant de fois par jour que nécessaire.
J’entends souvent dire "je n’ai pas besoin de tout ça". Je veux bien l’entendre dans une certaine mesure mais la grande majorité des choses citées précédemment sont personnellement la base de ce que j’attends en 2022 dans une entreprise produisant du logiciel. Il est impensable pour de nombreuses entreprises d’avoir son site internet inaccessible pendant un déploiement. De ma même manière qu’il est impensable de se passer de monitoring, ou encore d’un pipeline de déploiement fiable.
Ce n’est également pas parce qu’une équipe est petite qu’elle doit travailler en mode dégradé.
Comme dit précédemment nous devons automatiser ces changements. On voit également que l’on est plus du tout dans une vision statique d’une infrastructure mais au contraire dans un monde où les choses changent en permanence (d’où l’intérêt de choses comme du service discovery par exemple).
Là aussi j’en vois certains me dire "mais moi je n’ai pas envie que les choses changent, j’aime le statique !". On en revient aux sources de DevOps avec des développeurs souhaitant déployer souvent et demandant un certain nombre de services et des admin système voulant la stabilité.
Il y aura de toute façon toujours des changements sur une infrastructure, que vous le vouliez ou non (les pannes).
Cette abstraction existe toujours
Vous avez besoin de cette abstraction. D’ailleurs, vous l’avez toujours. On m’a déjà dit peu ou prou par exemple "je n’ai pas besoin d’abstraire mon infrastructure, j’ai du Ansible et des scripts shell qui font tout pour moi". L’abstraction est bien là ! Elle est juste encodée dans un script ou dans un rôle Ansible et non dans une API.
Statique vs dynamique
Faire du Ansible ou autre outil de configuration pour certains besoins peut suffire. Quelques serveurs, des rôles Ansible permettant d’abstraire le déploiement d’applications, et on dit aux développeurs "si tu veux déployer tel application avec tel version, tu mets le numéro de version ici et tu cliques sur le bouton" ce qui déclenchera le déploiement.
Ce que je décris ici est comme dit précédemment une abstraction "statique". Vous exécutez des actions et cela change l’infrastructure. Le reste du temps, il ne se passe rien. Et pour certains besoins, c’est peut être suffisant: vous perdez un serveur dans la nuit, vous en avez deux autres qui continuent de tourner et qui peuvent accueillir la charge du troisième jusqu’au matin où quelqu’un va intervenir pour régler le problème.
Mais quand une infrastructure grossit on a besoin de réactivité: les problèmes arrivent statistiquement plus souvent, il y a de plus en plus d’actions sur la production et de plus en plus de choses à faire. On change ici de paradigme pour rentrer dans une infrastructure dynamique qui réagira aux événements. Il est encore une fois ici important de penser de manière globale et de réfléchir à abstraire l’ensemble des dépendances des applications.
Un déploiement ? Comme dit précédemment l’infrastructure se charge de réaliser cela correctement. Une panne ? Le service est automatiquement redéployé, sur une autre machine si besoin. Trop de charge ? De nouvelles instances sont automatiquement créées… Comment réaliser cela ? Via une infrastructure déclarative.
Dans le mode "statique" on lançait une action (script, rôle Ansible…) qui allait ensuite avoir un impact sur l’infrastructure. Dans le mode "dynamique" vous allez déclarer l’état voulu et l’infrastructure se chargera elle même de converger vers cet état: "Je veux entre 3 et 10 instances de cette application selon la charge, jamais plus, moins" par exemple. Quand un événement se produira l’infrastructure se chargera si besoin de changer de changer son état pour arriver au résultat voulu (on parle généralement de réconciliations). Le réseau, le monitoring, et les autres applications s’adaptent aux changements.
Vous trouvez cela intéressant ? C’est exactement le fonctionnement du Cloud ou de Kubernetes.
Construire ou acheter
C’est là que certaines technologies entrent en jeux. Il est important de garder en tête ce que l’on souhaite obtenir. La technologie n’est qu’un outil pour arriver à nos objectifs.
Un choix technologique dépend de nombreuses choses: vos besoins (taille de l’entreprise, taille des équipes, besoin des équipes..), vos compétences internes, d’obligations légales… Il y a toutes sortes de raisons pour choisir une technologie mais restons concentré sur l’objectif à atteindre.
J’ai eu récemment de nombreux débats où était impossible de faire comprendre que c’est l’abstraction de l’infrastructure et du pipeline de déploiement (une plateforme) qui est le vrai sujet d’infrastructure dans la majorité des boîtes faisant du logiciel, et que c’est ce qui est attendu aujourd’hui même pour de petites équipes.
L’objectif est aussi de pouvoir rajouter des équipes de développeurs ou de nouveaux services sans à avoir à embaucher de nouveaux admin système (ou très peu): une croissance linéaire du nombre de développeurs ne doit pas provoquer la même croissance côté plateforme.
Reparlons de Kubernetes: je pense personnellement que Kubernetes (avec des outils additionnels) est une solution possible pour construire une plateforme interne à une entreprise. Certaines personnes pensent d’ailleurs que l’intérêt de Kubernetes n’est que dans le scaling: grave erreur, la majorité des utilisateurs (petites équipes inclues) veulent d’abord l’abstraction qu’il apporte (et qui est en grande partie portable). Beaucoup de personnes répètent malheureusement des choses entendues à droite à gauche sans réelles expériences sur la technologie. Donc non, Kubernetes n’est pas réservé qu’aux besoins avec des centaines ou milliers de machines ou dans des cas de scaling extrême.
Et le Cloud ? Vous pouvez acheter cette abstraction, ou du moins en partie:
- De l’Infrastructure as a service (IaaS) vous fournira des briques (machines virtuelles, réseau, stockage…) sur lesquelles vous allez pouvoir construire. L’IaaS a souvent peu d’intérêt sans quelque chose au dessus, car trop bas niveau pour être exposé directement aux développeurs.
- Du Platform as a Service (PaaS) peut parfois offrir une grande partie (voir la totalité pour des besoins simples) de ce que vous avez besoin.
- Un mixte des deux (IaaS, base de données as a service, services de types PaaS ou offre Kubernetes managé) est souvent très intéressant.
Il est important lorsque vous choisissez des cloud providers de vraiment creuser leurs produits et leurs catalogues: est ce que tout ce dont j’ai besoin est disponible, et si non, puis-je construire ce qu’il me manque ? Est ce que la plateforme est sécurisée ? Nous avons quelques experts nationaux qui adorent comparer des produits ou plateformes de manière dirons nous approximative (ce que je trouve encore pour gênant quand il y a des intérêts financiers derrière).
Les besoins d’une entreprise évoluent également souvent avec le temps. Commencer avec un PaaS quand on a une application simple avec une base de données puis migrer sur des outils plus intéressants et permettant notamment des architectures orientées service est commun.
Vous voulez faire de l’on premise ? Aucun problème. Je le répète, je n’oppose pas les technologies. Avoir ses propres datacenters peut être très bien mais là aussi il faut réfléchissez à l’abstraction à proposer. Cloud privé avec surcouche maison ? Offre Kubernetes interne ? Produits propriétaires à installer on premise ? Faites votre choix.
Mais on premise ou non, le service demandé par les utilisateurs (les développeurs en premier lieu) est généralement le même. C’est d’ailleurs pour ça que j’ai du mal à comprendre les administrateurs système anti-cloud ou anti-plateforme: est-il vraiment possible de travailler efficacement on premise sans y appliquer les concepts du cloud (et donc d’avoir un cloud privé) ? Est-il surprenant que les équipes demandent ensuite à migrer sur le Cloud ou sur des plateformes type Kubernetes si le service rendu n’est pas au niveau ?
Conclusion
J’adorerai qu’on parle d’abord lorsqu’on compare des technologies du service rendu pour ensuite descendre vers les choix techniques, et non l’inverse.
Partir de besoins comme ceux que je cite précédemment (déploiement, autonomie des développeurs, service discovery, gestion du réseau, tolérance aux pannes, déploiement continu, monitoring, API first…) pour ensuite discuter des solutions.
Une fois que l’on a le besoin on peut discuter de l’implémentation. Et les besoins cités dans cet article sont courants aujourd’hui et c’est une erreur de les ignorer.