Je présenterai dans cet article "techno-agnostic" (aucune techno citée) les différents types de métriques que vous pouvez retrouver dans une application, et expliquerai comment les utiliser.
Cet article est le premier d’une j’espère longue série sur l’observability qui traitera en profondeur du sujet. Attendez vous prochainement à d’autres articles sur les logs, les traces, les SLO/error budget/burn rate, l’alerting, le monitoring "blackbox" et toutes les bonnes pratiques associées.
Retrouvez l’article sur Opentelemetry et le tracing ici.
Qu’est ce qu’une métrique ?
Une métrique est une mesure et des informations associés à une date précise (un timestamp). Prenons l’exemple d’une métrique représentant le nombre de requêtes HTTP reçu par un serveur web. Je l’appellerai http_requests_total.
Cette métrique sera donc incrémentée à chaque fois que le serveur HTTP reçoit une nouvelle requête. Imaginons maintenant que nous puissons regarder et noter de manière régulière la valeur de cette métrique. Cela donnerait peut être (Pour plus de simplicité, je ferai toujours commencer le temps à la valeur 0 dans mes exemples) :
| timestamp | valeur |
|---|---|
| 1 | 10 |
| 11 | 70 |
| 21 | 90 |
Valeurs de http_requests_total
Au temps 1, la valeur de la métrique est 10. Au temps 11, elle est de 70 et au temps 21 elle est de 90.
On en déduit donc que notre serveur HTTP a reçu 60 requêtes (70 - 10) entre les temps 1 et 11, et 20 requêtes (90 - 70) entre les temps 11 et 21.
Prenons un autre exemple: une métrique pourrait par exemple remonter la consommation mémoire (RAM) d’un serveur. Elle s’appellera ici memory_used et sa valeur sera en mégabyte:
| timestamp | valeur |
|---|---|
| 1 | 1500 |
| 11 | 3000 |
| 21 | 2900 |
Valeurs de memory_used
Notre serveur utilisait donc 1500 MB de mémoire au temps 1, 30000 MB au temps 11, et 2900 au temps 21.
Nos métriques peuvent donc représenter plusieurs choses mais l’idée est toujours la même: une mesure associée à un temps.
Labels
Tout cela est bien pratique, mais il est très souvent nécessaires d’avoir plus de détails sur les métriques. Reprenons notre métrique http_requests_total : comment faire si je souhaite compter le nombre de requêtes par url cible ou par méthode HTTP par exemple ? Si mon serveur web héberge un blog, j’aimerai bien avoir le nombre de de requêtes par article de blog dans le but de connaître mes articles les plus populaires.
Cela est possible en rajoutant des labels à la métrique. Les labels sont des dimensions supplémentaires attachées à une métrique. Je vais ici en ajouter trois:
url: l’adresse de la page demandée à mon serveur webmethod: la méthode HTTP de la requête
Voici à quoi pourraient ressembler des observations de cette métrique pour par exemple un blog culinaire présentant des recettes de pâtisseries:
| timestamp | url | method | valeur |
|---|---|---|---|
| 1 | /paris-brest | GET | 40 |
| 3 | /eclair | GET | 10 |
| 11 | /paris-brest | GET | 60 |
| 13 | /eclair | GET | 15 |
Valeurs de http_requests_total avec des labels
Ces valeurs nous montrent qu’au temps 1, la page paris-brest avait eu 40 visites, puis 60 au temps 11. La page eclair avait elle 10 visites au temps 3, puis 15 au temps 13.
La méthode HTTP ici est toujours GET. Nous verrons des exemples plus complexes dans la suite de cet article.
On appelle généralement série une combinaison possible des valeurs des labels pour une métrique donnée. Nous avons dans cet exemple deux séries pour la métrique http_requests_total:
url="/paris-brest",method="GET"url="/eclair",method="GET"
Cela nous amène à la notion de cardinalité et du choix des labels.
Cardinalité
On appelle cardinalité le nombre de série pour une métrique. La cardinalité était donc de deux dans notre exemple précédent.
Imaginons le même site web mais avec ce coup ci 50 recettes différentes, et que l’on autorise en plus les utilisateurs à voter pour une recette (dans le but de pouvoir classer les recettes par popularité par exemple) en exécutant une requête de type POST sur l’url de la page. GET /paris-brest permettrait par exemple aux utilisateurs de récupérer la recette du Paris Brest, et POST /paris-brest de voter pour cette recette.
On a donc 50 pages (50 recettes), et 2 méthodes (GET et POST) par recette. Notre cardinalité est donc de 50 * 2 soit égale à 100.
Rajoutons un label à notre métrique: le nom de la machine (host) hébergeant le serveur web. Il est en effet courant d’avoir une application hébergée sur plusieurs serveurs pour par exemple avoir de la tolérance aux pannes. Voici par exemple deux séries ayant les mêmes labels à part celui nommé host:
| timestamp | url | method | host ̀ | valeur |
|---|---|---|---|---|
| 1 | /paris-brest | GET | server_1 | 40 |
| 1 | /paris-brest | GET | server_2 | 10 |
Exemples de séries
Quelle serait la cardinalité de la métrique si l’on hébergeait le blog culinaire sur 4 serveurs différents ? Elle serait de 50 * 2 * 4 soit 400 (50 pages, méthodes HTTP GET ou POST, et les 4 serveurs).
choix des labels et explosion de la cardinalité
Il est important de choisir correctement les labels d’une métrique:
- Les labels doivent être pertinents et avoir du sens pour la métrique. Comme nous le verrons plus loin dans cet article la majorité des bases de données pour stocker des séries temporelles permettent de requêter les métriques en fonction de leurs labels. Avoir un label
urlsur une métrique HTTP est donc logique car il sera très utile de pouvoir filter les métriques sur ce label. - Il faut éviter d’avoir une cardinalité trop importante. Une erreur classique faite par de nombreux développeurs est de stocker l’ID aléatoire (
uuidgénéralement) généralement associé à une requête HTTP dans un label: cela veut dire que chaque requêtes HTTP sur le serveur web créera une nouvelle série. Cette série n’aura qu’une mesure, car une nouvelle requête en créera une nouvelle.
Il y a d’autres pièges à éviter sur les labels. Reprenons notre label url sur notre serveur HTTP. Certaines URL peuvent être variables, par exemple une API web pourrait contenir un ID d’utilisateur comme par exemple /user/:id, la partie :id étant variable et contenant un ID associé à chaque utilisateur.
Il est important dans ce cas d’utiliser comme label pour url la valeur /user/:id sans remplacer l’ID à chaque requête, et non par exemple /user/1, /user/2… ce qui créerait une série pour chaque utilisateur de la plateforme. Utiliser l’url avec la variable non remplacée ne créera qu’une série quel que soit la valeur de la variable.
Certains labels peuvent être identiques à de nombreuses séries.
Les organisations ont très souvent plusieurs environnements: production, pré-production (staging), développement… Il est très intéressant d’ajouter ce label aux métriques pour pouvoir facilement les distinguer, comme pour par exemple avoir des politiques d’alertes différentes entre un environnement de production et de développement. Toutes les métriques de production pourraient par exemple avoir un label environment=production. D’autres labels génériques de ce type peuvent aider à classifier les séries.
Il est également important d’avoir une cohérence sur le nommage des labels. Il serait dommage d’avoir la moitié des métriques avec env=production et l’autre moitié avec environment=production par exemple. Certains outils permettent de faire du relabeling (renommer les labels de certaines métriques) mais se poser ce genre de questions dès la mise en place du monitoring reste important.
Types de métriques
Il existe différents types de métriques. Il vous faudra choisir le bon type selon ce que vous voulez mesurer et calculer.
Compteurs
Un compteur (counter) est tout simplement une métrique comptant quelque chose. C’était par exemple le cas de la métrique http_requests_total présentée précédemment.
Cela veut dire dans le cas de cette métrique que mon serveur web va incrémenter la série correspondante (en fonction des labels) à chaque requête HTTP reçue. Ces compteurs par série vont donc seulement s’incrémenter en permanence.
Compter des choses est utile mais il est souvent plus intéressant de calculer un taux (rate) par seconde. Voici par exemples 3 valeurs pour une même série avec le calcul du rate pour chaque valeur.
| timestamp | url | method | compteur | rate (req/sec) |
|---|---|---|---|---|
| 1 | /paris-brest | GET | 40 | |
| 11 | /paris-brest | GET | 80 | (80-40)/10 = 4 |
| 21 | /paris-brest | GET | 180 | (180-100)/10 = 8 |
| 31 | /paris-brest | GET | 210 | (210-180)/10 = 3 |
Calcul du rate http_requests_total
On voit que le rate est calculé en soustrayant la valeur actuelle du compteur par sa valeur précédente, le tout divisé par l’interval de temps.
En effet, entre ma métrique au temps 1 et celle au temps 11, 10 secondes se sont écoulées. La valeur de la métrique au temps 1 était de 40, et celle au temps 11 était de 80. Il y a donc eu 40 requêtes (80 - 40) entre ces deux valeurs.
On en déduit donc que l’application a reçue en moyenne 4 requêtes par seconde pendant cet interval de temps.
Appliquer cette méthode à chaque nouvelle valeur reçue permet de calculer le rate au fil du temps.
Réinitialisation du compteur
Les applications gardent généralement leurs métriques en mémoire. Cela veut dire que les métriques sont réinitialisées en cas de redémarrage de l’application par exemple. Il est possible dans ce cas d’obtenir un rate négatif.
| timestamp | url | method | compteur | rate (req/sec) |
|---|---|---|---|---|
| 1 | /paris-brest | GET | 40 | |
| 11 | /paris-brest | GET | 80 | (80-40)/10 = 4 |
| 21 | /paris-brest | GET | 10 | (10-80)/10 = -7 |
Calcul du rate http_requests_total
On voit dans cet exemple que la valeur de la métrique est de 80 au temps 11, et -7 au temps 21. En effet, la valeur de la métrique est passée de 80 à 10, ce qui peut arriver si l’application a redémarrée pendant cet interval de temps.
Une solution peut être par exemple de filtrer les valeurs négatives, ces dernières étant de toute façon incorrectes.
Jauge
Un autre type de métrique est la Jauge (Gauge). Cette métrique représente tout simplement une valeur arbitraire.
On peut s’en servir pour compter le nombre d’éléments dans une queue de message par exemple. Notre programme pourrait générer une métrique toutes les 10 secondes contenant le nombre d’éléments dans la liste à cet instant.
| timestamp | valeur |
|---|---|
| 1 | 10 |
| 11 | 8 |
| 21 | 15 |
Valeur de ma jauge
C’est sur ce genre de besoins (nombre d’éléments dans une liste, une queue, une table d’une base de données…) que l’on rencontrera le plus souvent ce type de métriques.
Quantiles et histogrammes
Les quantiles (souvent appelés également percentiles) sont très courants dans le monde du monitoring lorsqu’on souhaite monitorer les performances d’une application.
Reprenons notre exemple de blog culinaire. Nous pourrions avoir envie de mesurer le temps de chargement des pages de notre site. Nous allons donc devoir mesurer le temps des requêtes côté serveur et utiliser ces mesures pour avoir une aperçu des performances de notre serveur HTTP.
C’est ici que les quantiles entrent en jeux. Les quantiles vont s’appliquer sur nos mesures et servent à découper en deux partie cet ensemble de mesures, par exemple:
q50(quantile 50, souvent appelé50également): ceci est la médiane. Ici, 50 % des requêtes HTTP ont un temps d’exécution inférieur à la valeur associée à mon quantile, et 50 % ont un temps d’exécution supérieur.q75: 75 % des requêtes HTTP on un temps d’exécution inférieur à la valeur associée à mon quantile, et 25 % ont un temps d’exécution supérieur.q99: 99 % des requêtes HTTP on un temps d’exécution inférieur à la valeur associée à mon quantile, et 1 % ont un temps d’exécution supérieur.q1: ceci sera tout simplement la valeur maximale (la requête la plus lente) de mon serveur HTTP.
Prenons par exemple ce jeu de données représentant les durées d’exécution des requêtes sur mon serveur HTTP en millisecondes:
550, 300, 1000, 2000, 450, 1300, 1400, 200, 300, 400, 900, 1200, 800, 350, 500
Nous n’avons dans cet exemple que 15 valeurs pour faciliter l’exemple mais en réalité vous pourriez réaliser ce calcul sur plusieurs milliers si nécessaire.
Une des premières choses que l’on pourrait faire est de trier ces valeurs:
200, 300, 300, 350, 400, 450, 500, 550, 800, 900, 1000, 1200, 1300, 1400, 2000
Calculons maintenant le q50 sur ces valeurs (la médiane): nous voulons donc trouver la valeur au centre de notre distribution et donc avant le même nombre de valeurs avant et après cette valeur.
Ceci est assez simple dans notre cas: nous avons 15 valeurs, donc la médiane sera la 7eme valeur de notre liste triée. Nous aurons en effet 6 valeurs inférieures, et 6 valeurs supérieures.
La valeur du q50 est donc de 500.
De la même façon, nous voulons pour le q75 trouver la valeur ayant 75 % de valeurs inférieures (soit 15 * 75/100 = 11,25 que l’on arrondira à 11), et 25 % supérieures (donc 4)
La 11eme valeur de notre liste est 1000, et donc notre q75 sera égal à cette valeur.
Notre jeu de données est petit donc la même procédure appliquée au q99 nous donnera la valeur 2000 qui est aussi la valeur maximale.
Les quantiles sont donc bien utiles car ils permettant d’avoir rapidement une information pertinente sur par exemple des performances d’applications. Cela permet également d’énoncer des objectifs de performances clairs, comme par exemple 99 % de mes requêtes doivent s’exécuter dans un temps inférieur à une seconde.
Dans des cas réels avec de grands jeux de données (des milliers de requêtes par exemple) on peut même aller jusqu’à calculer le q99.9 ou q99,99 si besoin.
Histogrammes
La méthode précédente pour calculer des quantiles est intéressante car elle permet de calculer exactement la valeur du quantile. Elle a également un défault: l’ensemble des valeurs doivent être disponibles pour réaliser le calcul.
Cela peut être problématique lorsqu’on veut calculer des quantiles sur un grand nombre de valeurs qui devront donc être stockées de façon unitaire.
Une autre solution pour calculer les quantiles est d’utiliser un histogramme dans le but de calculer une valeur approchée du quantile mais sans avoir à stocker l’ensemble des données.
La première chose à faire est de choisir les intervalles (aussi appelés bucket) de notre histogramme.
Nous reprendrons comme exemple ici le temps de traitement de requêtes par un serveur HTTP, avec ce temps en millisecondes. Une pratique courante dans le monde du monitoring serait d’utiliser des intervalles démarrant tous à 0 et de compter le nombre de requêtes ayant un temps d’exécution inférieur à une valeur donnée.
La liste de nos mesures est dans cet exemple la même que précédemment:
200, 300, 300, 350, 400, 450, 500, 550, 800, 900, 1000, 1200, 1300, 1400, 2000
Comptons maintenant le nombre de valeurs dans différents intervalles, par exemple combien de requêtes ont un temps d’exécution dans l’intervalle 0-100, 0-200, 0-400…
| Minimum (toujours 0) | Maximum (inclus) | Total (nombre) |
|---|---|---|
| 0 | 100 | 0 |
| 0 | 200 | 1 |
| 0 | 400 | 5 |
| 0 | 600 | 8 |
| 0 | 1000 | 11 |
| 0 | 1400 | 14 |
| 0 | 2200 | 15 |
| 0 | Infini | 15 |
Intervalles de l’histogramme
On a donc 0 requête ayant un temps d’exécution entre 0 et 100 millisecondes, 1 entre 0 et 200 millisecondes, 5 entre 0 et 400 millisecondes etc.
On remarque que cette manière de faire permet de ne pas avoir à garder l’ensemble des mesures: il suffit lorsqu’une nouvelle mesure est réalisée d’incrémenter tous les intervalles nécessaires.
On remarque également que le nombre de valeur dans chaque intervalle est en augmentation constante, ce qui est logique car les valeurs précédentes sont inclus dans chaque intervalle vu que l’on recompte à chaque fois le nombre de valeurs dans l’intervalle depuis 0.
Le dernier intervalle est intéressant: il compte le nombre de valeurs de 0 à Infini, et contiendra donc toujours le total des valeurs.
Ces informations permettent de calculer simplement une valeur approximative d’un quantile, comme par exemple le q50:
-
Il y a 8 intervalles différents, et 15 mesures dans ces intervalles.
-
Nous savons que nous recherchons la métrique au centre de notre distribution, et que nous voulons calculer la médiane: Nous commençons donc par réaliser le calcul suivant:
0.5 * 15=7.5. Nous recherchons donc où se trouve cette valeur (7.5) dans notre histogramme. -
On recherche l’intervalle juste après cette valeur: dans notre cas, c’est dans l’intervalle
[0, 600]car sa valeur est de 8. La valeur de l’intervalle précédent étant de 5 nous pouvons en déduire que le quantile se trouve dans cet intervalle (car5 < 7.5 < 8). -
Nous calculons maintenant le nombre de valeurs présentes entre cette intervalle (
[0, 600]) et le précédent ([0, 400]. Nous souhaitons donc répondre à la question combien de mesures ayant une valeur entre 400 et 600 avons nous ?
Le résultat est8 - 5et est donc égal à3. -
Comme dit au début de cet article, nous allons calculer une valeur approximative pour notre quantile.
Nous savons que notre quantile se trouve quelque part dans l’intervalle [400, 600] (qui couvre une durée d’exécution de200millisecondes), et que nous avons3valeurs dans cet intervalle. Rappelez vous que l’on recherche la durée théorique pour la valeur7.5calculée précédemment. -
Nous réalisons l’opération
(7.5 - 5) / 3 = 0.833. Nous soustrayons ici la valeur recherchée à la valeur associée à la borne inférieure (400) de notre intervalle, que nous divisons ensuite par le nombre de valeurs dans l’intervalle (3). -
Nous multiplions le résultat précédent par la durée de l’intervalle:
200 * 0.833 = 166.6. Nous pouvons décrire ce calcul de la façon suivante: j’ai un intervalle de taille 200 le point recherché se trouve au pourcentage 0.833. -
Nous ajoutons la borne inférieure de notre intervalle à ce résultat:
400 + 166.6 = 566.6. Ceci est le résultat final et la valeur approximative de notre quantile (et la médiane dans cet exemple).
Ce calcul peut aussi se résumer au fait de tracer une droite entre les coordonnées [400, 5] et [600, 8] et de rechercher la valeur associée à 7.5 sur cette droite.
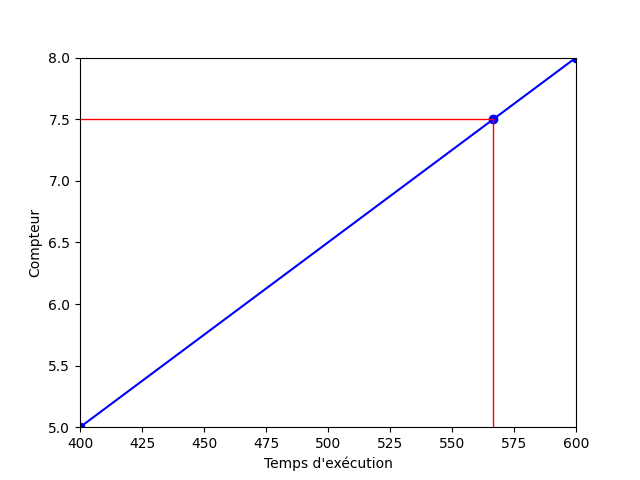
Notre résultat approximatif est différent du résultat réel (qui est de 500). Il faut garder en tête que ce type de calculs fonctionne mieux sur de plus gros jeux de données.
Mais ce résultat nous donne dans tous les cas une idée de la performance de notre application, et c’est ce qui est le plus important. Connaître la performance de notre application à la milliseconde près n’est pas utile dans de nombreux contextes.
Il vaut mieux pouvoir obtenir rapidement et simplement (en utilisant peu de capacités de stockage et de calcul) une valeur approximative mais proche de la réalité que de toujours vouloir une valeur exacte mais qui peut se révéler difficile à calculer.
Pull vs Push et stockage
Nos systèmes émettent donc des métriques. Pour les exploirer, il faut pouvoir les requêter et donc les stocker.
Il existe deux mondes lorsqu’il s’agit pour une application de diffuser ses métriques dans le but de les stocker: le mode push et le mode pull.
Le push
Dans ce mode, l’application pousse les métriques vers une base de données temporelle (ou vers tout autre système de stream processing pouvant éventuellement servir à filtrer, modifier, enrichir la métrique, ou faire backpressure).

Ce mode a un certain nombre d’avantages:
- Un endpoint unique à connaître pour les applications pour pousser les métriques: cela permet une énorme facilité en terme de configuration applicative et réseau (règles de firewalling en sortie seulement vers une destination unique).
- Possibilité d’ajouter facilement des composants intermédiaires comme dit précédemment pour faire du stream processing ou absorber des pics de charge en ayant un composant "buffer" entre l’application et la base de données temporelle.
- Haute disponibilité et scaling très facile (load balancing, déduplication du traffic entre plusieurs base de données/services cloud par exemple)
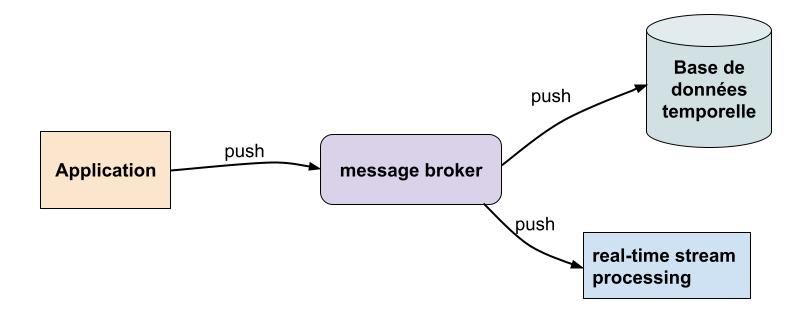
Le push est plus facile à scale et beaucoup plus flexible en ajoutant un système intermédiaire de type "message broker" entre l’application et les systèmes externes. N’importe qui peut comme ça consommer les métriques sans impacter les autres.
Bref, le push, c’est bon, mangez en, malheureusement c’est plus forcément "à la mode" pour la gestion de métriques.
Le pull
Une technologie apparue il y a quelques années a proposé une approche différente et été vite adoptée pour différentes raisons: le pull.
Dans ce mode, c’est l’outil stockant les métriques qui va aller chercher (pull) les métriques en envoyant directement des requêtes à l’application. Cela veut dire que l’application doit les exposer, via HTTP dans notre cas.

Une application pourrait par exemple exposer un endpoint HTTP /metrics retournant dnas cet exemple la valeur associée à l’instant T de la requête aux différentes métriques configurées (ici des compteurs):
healthcheck_total{id="f7b4dba8-9626-436e-a0d2-670e862c650a", name="appclacks-website", status="failure", zone="fr-par-1"} 1
healthcheck_total{id="f7b4dba8-9626-436e-a0d2-670e862c650a", name="appclacks-website", status="success", zone="fr-par-1"} 2789
healthcheck_total{id="f7b4dba8-9626-436e-a0d2-670e862c650a", name="appclacks-website", status="failure", zone="pl-waw-1"} 1
healthcheck_total{id="f7b4dba8-9626-436e-a0d2-670e862c650a", name="appclacks-website", status="success", zone="pl-waw-1"} 2789
La base de données temporelle fera périodiquement (toutes les 30 secondes par exemple) une requête, associera à la valeur des métriques le timestamp de la requête, et stockera ça dans sa base.
L’approche pull demande une énorme logique en service discovery et a une plus grosse complexité réseau que le push. Cela force également toutes vos applications à exposer un endpoint HTTP servant les métriques.
Au final, les deux approches fonctionnent. Je vous recommande un autre de mes articles sur le sujet si vous voulez avoir plus de retours sur le pull vs push.
Calculs côté client ou côté serveur
Dernière partie de cette article, le calcul côté client ou côté serveur.
J’ai expliqué précédemment comment calculer par exemple des rate, quantiles… à partir de métriques brutes.
Il faut savoir que parfois, certaines librairies applicatives de gestion de métriques calculent ces valeurs pour vous. Cela veut dire que votre application ne va pas exposer à la base de données temporelle les données brutes (par exemple, la valeur d’un compteur ou les buckets d’un histogramme) mais directement un nombre de requête par seconde, es quantiles (p99, p75…).
Cela peut sembler intéressant de prime abord car il n’y a aucun calcul à réaliser côté base de données temporelle, mais il y a beaucoup d’inconvénients à ne pas avoir accès aux métriques brutes:
-
Si les données sont pré-calculées côté application, il n’est plus possible d’aggréger ensemble les métriques de plusieurs instances (replicas) d’une même application.
Il est en effet commun de calculer des quantiles pour une instance d’une application, mais aussi pour toutes les instances d’une application ensemble. Cela permet de visualiser la latence par instance de l’application (utile pour voir si une instance a des caractéristiques de performances étranges par rapport aux autres) mais aussi de voir la latence globale pour toutes les instances de l’application. Ce dernier calcul ne peut se faire que en ayant accès aux métriques brutes et en faisant la somme de chaque bucket de chaque instance de l’application. -
Je n’ai présenté dans cet article que quelques exemples de calculs à réaliser sur les métriques. En réalité, il y en a de nombreux autres que vous retrouverez dans vos base de données temporelles et qui sont également indispensables pour monitorer vos applications. Si vous n’avez pas accès aux données brutes, ces calculs seront irréalisables.
Conclusion
Les métriques sont indispensables pour monitorer correctement des composants applicatifs ou d’infrastructure. Bien choisir ses métriques (type, labels…) est important et est la clé pour construire une solide plateforme d’observability.