SLO: c'est quoi, pourquoi, comment, pour qui ?
Les SLO, c’est mon sujet du moment. En plus, je suis dans le train pendant 3 heures, une durée parfaite pour écrire un article de blog avec une contrainte de temps qui me forcera à le sortir rapidement (sans ça les articles stagnent en brouillon).
J’expliquerai donc dans cet article pourquoi je pense que les SLO sont un excellent outil pour faire du suivi de qualité, aider à la priorisation, et détecter rapidement les problèmes en production, et pourquoi toutes les équipes (tech, produit, management…) peuvent en bénéficier.
L’approche traditionnelle de l’alerting
J’ai longtemps hésité sur comment commencer cet article. Mon lectorat étant majoritairement composé de tech, commencer à parler d’alerting et je pense intéressant.
Lorsqu’on déploie un service en production, on sait qu’il aura un jour des problèmes. Les incidents, ça arrive, pour toutes sortes de raisons, et on veut pouvoir les détecter (et donc les corriger) rapidement pour limiter leurs impacts sur les utilisateurs.
Traditionnellement, l’alerting détecte si un service fonctionne, ou ne fonctionne pas, sans vraiment de nuances. Voici par exemple des règles d’alerting que l’on retrouve souvent sur une majorité de projet:
-
Le service ne répond plus: par exemple, un service HTTP est monitoré par une sonde externe (blackbox monitoring) et le service timeout.
-
Le service a renvoyé 20 % de requêtes HTTP avec le code d’erreur 500 les 5 dernières minutes.
-
Une latence élevée est observée sur le service: par exemple, sur les 10 dernières minutes, plus de 5 % des requêtes se sont exécutées en plus de 2 secondes (on définit donc une alerte sur le p95).
Dans tous ces cas, le service est fortement dégradé.
Ce type d’alerte fonctionne assez bien et permet de détecter les gros problèmes de la plateforme, mais lorsque le nombre de fonctionnalités, de services, de développeurs… grossit on voit des limitations arriver.
Reprenons l’exemple d’une alerte se déclenchant si 5 % des requêtes s’exécutent en plus de deux secondes (qui est déjà une valeur très importante) et voyons ses limites.
Dégradation ponctuelle mais non suffisante pour déclencher l’alerting
Si votre service se dégrade par moment seulement, l’alerte ne sera pas déclenchée. Dans des outils comme Prometheus, couramment utilisés pour de l’alerting, une alerte du type 5 % des requêtes sont exécutées en plus de 2 secondes va être vérifiée sur des plages de temps données (10 minutes par exemple). Sauf que:
-
Si vous n’avez que 4 %, ou 3 % des requêtes qui s’exécutent en plus de 2 secondes, le service sera dégradé mais l’alerte non déclenchée. On peut bien sûr adapter l’alerte (la déclencher à 1 % des requêtes par exemple), mais définir le bon seuil de déclenchement peut être difficile (voir second point) et les faux positifs peuvent arriver.
-
Si vous avez très peu de requêtes à certains moments de la journée (la nuit), les faux positifs sont possibles. Si en journée vous recevez 100 requêtes par secondes, une alerte sur 1 % de requêtes invalides sur une tranche de 10 minutes se déclenchera au bout de 3000 requêtes invalides (5 % de 100*60*10). Si la nuit vous n’avez plus que 0.2 requête par seconde, elle se déclenchera pour 6 requêtes seulement en erreur (5 % de 0.2*60*10). Pourtant, 6 requêtes en erreur n’est peut être pas si grave. Faut-il appeler l’astreinte ? Cela peut être difficile à répondre.
J’insiste sur le problème des faux positifs: c’est la première raison qui pousse les équipes à définir des alertes avec des seuils un peu large (gros % d’error rate ou grosse latence avant d’appeler l’astreinte).
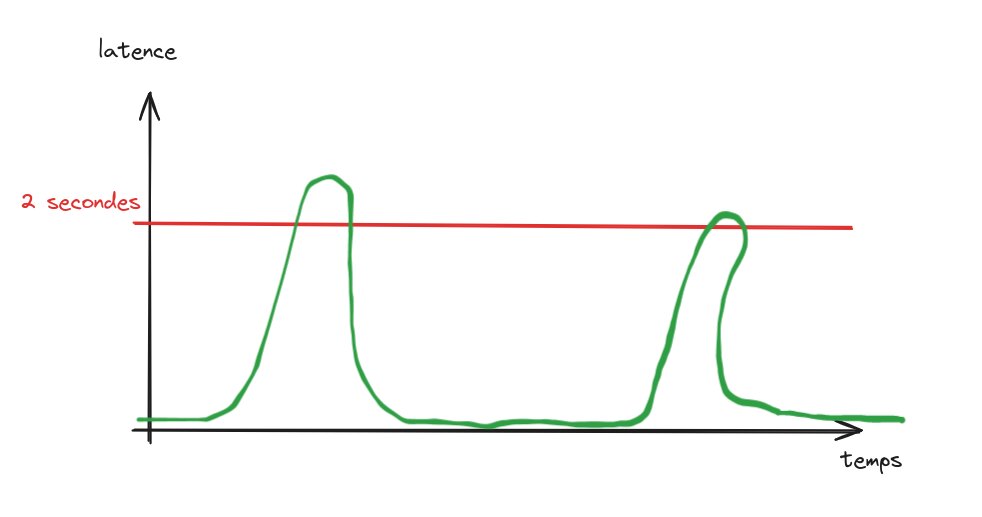
Sur ce graphe, le service est dégradé de temps en temps mais ce n’est pas suffisant pour déclencher l’alerting. Pourtant, on perd en qualité !
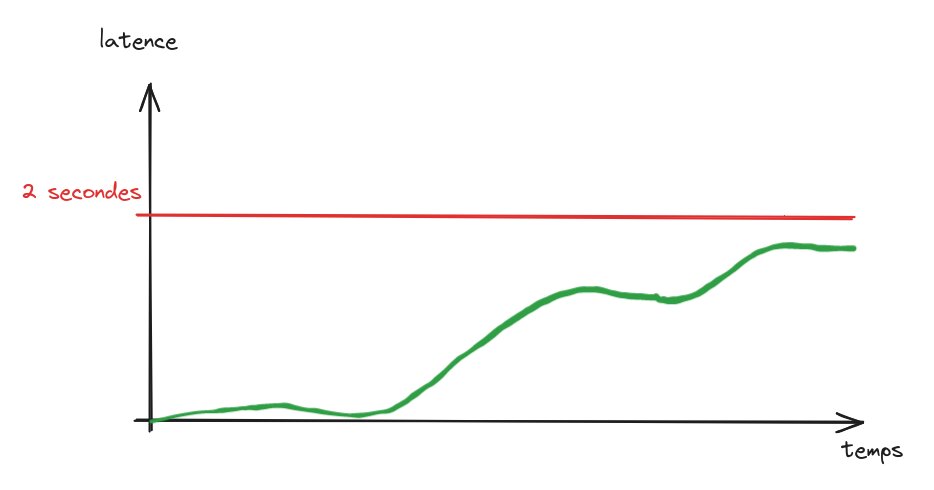
Ici, le service se dégrade peu à peu au fil du temps mais cela n’est pas détecté car la valeur de la métrique est toujours en dessous du seuil car ce dernier est élevé. Les utilisateurs ressentent déjà des problèmes mais l’alerte ne se déclenchera beaucoup trop tard.
Je pense qu’on a toujours besoin de ces alertes détectant une panne majeur du service. Mais il manque ici quelque chose: un suivi plus ambitieux de la qualité qui nous permettrait d’être alerté beaucoup plus rapidement quand une dégradation du service survient.
Le suivi de qualité
Comment vous suivez la qualité d’un service (HTTP par exemple) en production ? C’est quoi qui est acceptable en terme d’erreurs (le 100 % de succès n’existe pas) ou de latency pour votre produit ?
Par exemple, est ce que répondre 99.9 % du temps en moins de 100 millisecondes est acceptable ? Ou bien 200 millisecondes serait suffisant ? Le service répondait généralement en moins de 80 millisecondes il y a 2 mois, il y a un mois c’est passé à 140 millisecondes, et maintenant on est à 180 millisecondes. Est ce que c’est normal ? Comment je détecte ça ? Je ne vais quand même pas appeler mon équipe d’astreinte un dimanche à 2 heures du matin pour quelques dizaines de millisecondes en plus !
Et d’ailleurs, qui définit les objectifs de qualité d’un produit ? Les tech, qui vont toujours en premier lieu (testé IRL et approuvé) définir des objectifs "techniques" sur leurs services (error rate, latency…) ? Les gens du produit ? Peut être que d’un point de vue utilisateur, ce qui compte c’est que le produit fonctionne, peut être qu’on s’en fiche des métriques techniques, non ?
Voyons comment les SLO peuvent répondre à tout ça.
SLO
SLO veut dire Service Level Objectives. Ce n’est pas un concept nouveau mais les SLO (et la théorie autour) n’est au final que peu utilisée en dehors de quelques grosses boîtes tech type GAFAM (quel dommage).
Cet outil permet de définir et suivre de manière claire et impartiale des objectifs de qualité d’un produit. Prenons le cas fictif d’une plateforme de e-commerce et imaginons quelques SLO intéressants pour ce produit.
SLO métiers
Les SLO les plus intéressants à définir sont les SLO métier. Ces SLO peuvent être définis directement par les équipes produits (donc des gens "non tech") au moment de la phase de conception du produit. Ces objectifs sont ensuite communiqués aux équipes et suivi dans le temps.
Ces SLO doivent être compréhensibles par tout le monde. Limite, vous prenez quelqu’un au hasard dans la rue il doit comprendre vos SLO métier.
Voici quelques exemples de SLO métiers pour notre plateforme d’e-commerce:
-
99.9 % des requêtes d’authentification doivent être en succès: ce serait en effet dommage que l’utilisateur ne puisse pas se connecter.
-
99.99 % des requêtes, lorsque l’utilisateur procède au paiement, doivent être en succès: rien de pire qu’un utilisateur prêt à acheter mais où le backend plante pour une mauvaise raison.
-
99 % des requêtes sur le moteur de recherche du site doivent s’exécuter en moins d’une seconde: quand c’est lent, les gens ferment la page.
Bref, comme vous le voyez ici ces objectifs sont compréhensibles par monsieur tout le monde.
L’avantage des SLO métier est qu’ils couvrent tous les détails d’implémentation d’une fonctionnalité. Si le système d’authentification ne fonctionne plus, ou que la recherche est lente, quelle que soit la cause technique l’utilisateur est impacté et donc le SLO est également impacté.
Néanmoins, définir des SLO techniques est également intéressant.
SLO techniques
On retrouve ici du suivi de métriques techniques classiques, comme en début d’article, mais en plus ambitieux. Là où l’alerting traditionnel se concentre sur des valeurs de latency ou d’error rate élevés, on va ici avoir un peu d’ambition. Par exemple, on pourrait avoir sur le service backend gérant l’authentification des SLO du type:
-
99.99 % des requêtes doivent être en succès
-
Le service doit répondre 99.99 % du temps en moins de 100 millisecondes.
Il est important de garder en tête ici les SLO métiers: en effet, le SLO métier couvre tout l’aspect technique d’une fonctionnalité (et donc tous les problèmes potentiels). Le SLO technique d’une brique individuelle doit donc être plus ambitieux que le SLO métier (cela permet aussi d’avoir un peu de marge de manoeuvre).
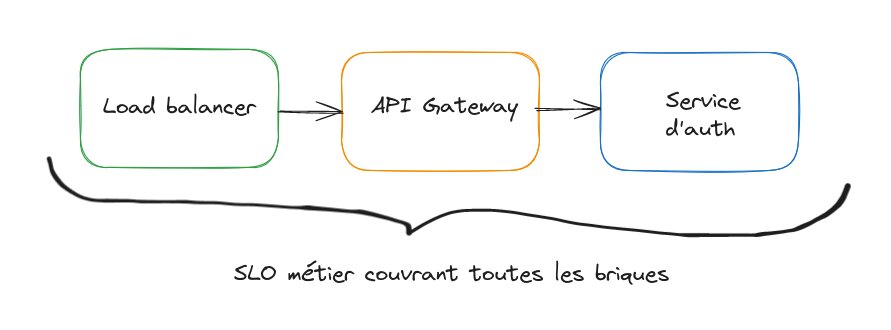
J’insiste ici sur l’aspect ambitieux des SLO: si vous mettez un objectif de latence à 2 secondes sur le service (surtout un service central comme l’authentification), ça ne sert à rien. Choisir les bonnes valeurs n’est pas facile, mais c’est un très bon exercise à faire à la conception d’un service.
Toutes les équipes techniques peuvent définir des SLO. Si vous êtes côté infrastructure, vous pouvez aussi ! Voici quelques exemples de SLO que je trouve très intéressants pour des équipes infras (rappelez vous que l’infra est également un produit, sauf que c’est pour des clients internes):
-
99.99 % des requêtes reçues par les load balancers doivent être correctement transmises aux services suivants (les load balancers AWS ont une métrique cloudwatch parfaite pour cela par exemple)
-
Le serveur DNS doit pouvoir répondre aux requêtes en moins de 2 millisecondes
-
Ajouter de la capacité à votre cluster Kubernetes (des noeuds donc, en cas d’autoscaling des applications) doit prendre moins d’une minute pour ne pas impacter les services ayant besoin de scale (= comptez le temps que passent des pods en "pending" sur le cluster)
-
La plateforme d’intégration et de déploiement continu doit être capable d’exécuter 99.99 % des jobs
-
Les logs ingérés applicatifs doivent être traités en moins de 30 secondes avant d’être visible dans la plateforme de centralisation de logs
-
Le "replication lag" de votre base de données (pour un read replica) doit être 99.9 % du temps en dessous de 20 secondes
En conclusion, les SLO c’est pour tout le monde. Cela force aussi les équipes à réfléchir sur des métriques de qualité, car ce n’est pas forcément quelque chose qui se fait naturellement.
SLO et métriques
Bref, on a nos SLO, et après ?
La première chose à faire et de pouvoir les suivre dans le temps. Je ne vais pas m’attarder sur cette partie mais globalement, c’est aux équipes techniques de bosser pour pouvoir exposer des métriques correspondants aux SLO. On parle ici de SLI (service level indicator).
Sur les SLO techniques, c’est généralement assez facile: compter le nombre de requêtes en erreur ou la latency d’un service HTTP, on sait faire depuis longtemps par exemple. Définir un SLO métier, c’est déjà un peu plus compliqué notamment quand plusieurs services sont impliqués. Quelques idées en vrac:
-
Peut être que la mesure peut être prise au niveau de votre API Gateway ?
-
Si vous avez un service orchestrant d’autres services (avec des workflows asynchrones exécutant des appels entre plusieurs services), peut être que le mesurer ici est une solution
-
Les SLO peuvent être dérivés du contenu de votre base de données: si vous avez par exemple des états du type "pending", "success", "error"… sur certaines entités, les compter régulièrement peut permettre de dériver un SLO (avoir plein d’entités en "pending" voudrait dire que le système n’arrive plus à les processer)
-
Pourrions-nous dériver des métriques depuis les traces (par exemple avec Opentelemetry), ce qui permettrait de couvrir le chemin complet d’une requête entre plusieurs services ?
Définir des SLO métier est toujours compliqué et je pense qu’il est impossible de tout couvrir, malheureusement. Mais tenter de couvrir un maximum de services est déjà un très bon point et c’est mieux que rien, faut bien commencer à un endroit.
Je bosse actuellement sur un outil (qui sera open source) pour simplifier la définition et le suivi des SLO, stay tuned ;)
Error budget
On a maintenant nos métriques (SLI) et nos objectifs (SLO). Reprenons l’exemple d’un SLO technique du type "99.9 % des requêtes d’un service HTTP doivent être en succès, donc avec un status code != 5XX".
Cela veut dire que si vous recevez en 1 mois 10 millions de requêtes sur ce service, pour rentrer dans votre SLO vous devez en avoir 9 990 000 (99.9 % de 10 millions) en succès au minimum, et donc 10 000 000 - 9 990 000 = 10 000 en erreur au maximum (0.1 % de 10 millions)
Ce chiffre (10 000) est votre error budget (budget d’erreur): chaque mois, votre service tolère 10 000 requêtes en erreur.
Cela change complètement la donne pour le suivi de qualité par rapport a de l’alerting traditionnel comme présenté en début d’article. Ici, pas de problèmes de faux positif si vous avez du traffic variable entre la journée ou la nuit. Pas de problèmes si vous avez parfois des pics d’erreurs non détectés par de l’alerting classique… dans tous les cas, cela va entamer votre budget et sera donc mesurable.
Rien que calculer périodiquement le nombre de requêtes des 30 derniers jours, le nombre d’erreur, et calculer et suivre votre budget vous apportera des informations qui n’étaient pas disponibles avant. Vous savez exactement si votre service répond à ses objectifs de qualité, ou non, de manière très simple.
En appliquant ceci aux autres SLO (notamment ceux métiers), on sait si les produits respectent leurs contrats de qualité ou non.
Réagir en cas de SLO non respecté
Que faire si vous avez cramé tout votre error budget pour un SLO ? C’est là que l’aspect "aide à la décision" est intéressant. Sans SLO, savoir quand réagir lorsqu’un produit se dégrade se fait au doigt mouillé et en se basant sur des éléments plus ou moins fiables: nombre et criticité des incidents sur le produit, retours des utilisateurs qui se plaignent…
Les SLO apportent des faits. C’est compréhensible pour tout le monde, c’est neutre, ça mesure la réalité. On peut donc les utiliser pour savoir quoi prioriser car on sait quelles fonctionnalités (ou quelles services) ont une dégradation de qualité.
C’est également un très bon outil pour voir l’impact de nouveaux choix techniques ou organisationnels, par exemple:
-
Vous être en train de découper votre monolithe en microservices, est ce que cela impacte votre SLO ? Est ce qu’en faisant cela vous perdez en qualité ?
-
Vous venez de changer complètement la façon de faire de la QA dans l’entreprise: est ce que là aussi, cela à un impact sur vos SLO, dans un sens ou un autre ?
Sans SLO, répondre à ce genre de questions est quasiment impossible. Et comment savoir qu’on va dans la bonne direction dans ce cas ?
Les SLO ne sont donc pas qu’un outil "tech": on a vu avant qu’il faut aussi impliquer les équipes produits pour les SLO métiers (et donc leur suivi ?), mais le management doit également les suivre pour ensuite apporter une réponse (prioriser) lorsqu’ils ne sont pas respectés. Si casser un SLO n’a aucune conséquence, cela ne sert pas à grand chose.
Burn rate et alerting
On a donc vu comment calculer notre error budget. Sauf qu’il serait dommage de n’être alerté que quand 100 % de l’error budget est consommé. Reprenons l’exemple précédent avec un SLO de 99.9 %: (Cela veut dire que si vous recevez en 1 mois 10 millions de requêtes sur ce service, pour rentrer dans votre SLO vous devez en avoir 9 990 000 (99.9 % de 10 millions) en succès au minimum, et donc 10 000 000 - 9990000 = 10 000 en erreur au maximum).
Vous avez donc chaque mois un budget de 10 000 requêtes en erreur. Si vous êtes le 5 du mois et que vous en avez déjà 9000, c’est mal barré ! Il reste 25 jours mais vous avez déjà cramé 90 % du budget, aïe !
C’est là où le burn rate intervient. On va calculer à quelle vitesse notre budget est consommé. Si il est consommé trop vite, vous pouvez détecter très rapidement que votre SLO va être très prochainement cassé.
Le burn rate se calcule de cette façon: ( [durée de calcul de l’error budget] * [un % d’error budget] ) / [période])
Dit comme ça c’est pas très clair, donc voici quelques exemples, pour un SLO/budget calculé sur 30 jours
-
Le burn rate si 10 % de votre error budget est consommé par jour, est de (30 * 10/100) / 1 = 3.
-
Le burn rate si 3 % de votre error budget est consommé par jour, est de (30 * 3/100) / 1 = 0.9.
-
Le burn rate si 1 % de votre error budget est consommé par heure, est de (30*24 * 1/100) / 1 = 7.2.
-
Le burn rate si 1 % de votre error budget est consommé en deux heures, est de (30*24 * 1/100) / 2 = 3.6.
Un burn rate < 1 montre que vous allez respecter votre SLO. Si > 1, si vous continuez dans cette voie vous allez le casser. On remarque en effet qu’utiliser 3 % d’une son error budget par jour pendant 30 jours (mon second exemple) fait qu’on l’utilisera à 90 %, donc c’est tout bon et on a même 10 % de marge. Par exemple, 1 % par heure veut dire qu’on va utiliser 24 % par jour, et donc 720 % du budget par mois. On explose notre SLO ici !
Calculer (et grapher) le burn rate est très intéressant pour détecter en amont les problèmes, avant d’avoir épuisé son SLO.
Comment alerter avec tout ça ? Si vous voulez alerter quand 1 % de votre error budget est consommé en une heure, on peut alerter si 10 000 * 1/100 = 100 requêtes sont en erreur la dernière heure (pour rappel, 10 000 étant la valeur total de notre error budget).
Vous pouvez combiner plusieurs alertes sur plusieurs périodes: 1 heure, 10 minutes, 5 minutes… en ajustant les valeurs. Vous pouvez également combiner les alertes (sur 10 minutes et une heure par exemple) pour être alerté seulement si plusieurs conditions sont valides sur plusieurs fenêtres de temps. En effet, si vous ne recevez vos alertes qu’une heure après le déploiement d’un problème, ce n’est pas idéal. Rajouter des alertes à déclenchement rapide sur la consommation du budget sur quelques minutes sera quasiment obligatoire. On évite également comme cela les faux positifs.
Conclusion
Mon train arrive bientôt en gare, la relecture sera pour plus tard. Je termine par une note personnelle: je suis triste de n’avoir pas poussé une définition et un suivi strict des SLO dès le début de ma carrière.