Ou comment gagner en efficacité en standardisant au maximum les choix techniques dans les équipes de développement.
Quand j’ai commencé la carrière, je détestais les frameworks. Bon, j’ai une excuse: quand la première exposition de quelqu’un à des frameworks c’est des bloatware à la Spring et companies (avec les bons vieux Hibernate, AspectJ etc) il y a de quoi être dégouté pendant quelques années.
J’ai par contre toujours vu l’intérêt d’avoir des libraries communes partagées entre projets, librairies qu’on peut ensuite assembler à son bon vouloir pour construire un service.
Mais depuis quelques années je commence à changer mon fusil d’épaule.
Une seule manière de faire
Quand je travaillais chez Exoscale, on a à un moment complètement repensé comment créer de nouveaux services backend. La manière de faire était hautement standardisée, que ce soit pour la partie HTTP serveur, cliente, ou pour la partie orchestration (qui est un peu le coeur de métier d’un cloud provider).
A partir de contrats (en EDN), on autogénérait les serveurs, les clients, la partie base de données (requêtes incluses), et on avait également la possibilité de décrire très facilement des workflows à base de machines à états avec des choses comme le retry ou la reconciliation automatique disponibles immédiatement.
Bref, lorsqu’un créait un nouveau service, où nous restait globalement qu’à écrire quelques contrats à et remplir des trous pour rajouter la logique métier. J’en rajoute un peu, mais clairement notre productivité était énorme (du moins c’était mon impression notamment comparé à ce que j’ai connu ailleurs) et chaque changement sur ce "framework" interne était immédiatement disponible partout, vu que tous les nouveaux projets l’utilisait. ° Passer d’un projet à un autre était aussi simplifié car on était pas dépaysé.
Et c’était je pense le bon choix. Et je pense que dans énormément de contextes, c’est ce qui doit être fait.
Le socle commun entre service
Si vous n’avez qu’un seul service, avec une seule équipe de développement, être libre de ses choix n’est pas trop un problème. Mais quand une entreprise grossit et qu’on commence à avoir 30, 50, 100, 150… développeurs, avec de nombreux services à maintenir (le microservice est quelque chose qui des devenu assez courant, pour le meilleur comme pour le pire), c’est différent.
Un nouveau service doit généralement respecter un certain nombre de standards. L’observability en est par exemple un. On veut les bonnes métriques aux bons endroits, on veut des traces, on veut un logger qui sait faire des logs structurés. On veut probablement avoir pour chaque service de l’authentification et de la gestion de permission également. Si vous faites de l’HTTP, vous voulez probablement avoir une spec OpenAPI autogénérée pour votre service.
Si une équipe maintient par exemple deux applications faisant de l’HTTP, en dehors de la logique business, le reste sera identique.
Le problème est la gestion de ce socle commun.
Si aucun outillage n’est mis en place, le premier reflexe des équipes lors de la création d’un nouveau service sera de copier/coller le code d’un service précédemment créé, généralement en y apportant quelques changements. Ceci est un énorme problème pour plusieurs raisons:
- Même si le code est copier/coller, il va peu à peu dériver par rapport à l’implémentation originelle. C’est un peu l’évolution de Darwin en fait: le second service créé sera un peu différent du premier, le troisième sera un peu différent du second, le quatrième un peu différent du troisième… répétez ça avec des dizaines de développeurs dans des dizaines d’équipes et à la fin vous n’avez plus aucune cohérence dans votre base de code. Pire, parfois le copier/coller inclut des bugs qui vont donc se diffuser peu à peu à l’ensemble des services (vécu).
- Les bonnes pratiques, les standards, ça évolue. Lorsque les services ne partagent aucun socle commun, il devient extrêmement compliqué de backport un changement ou une évolution dans l’ensemble des services. Vous vous retrouvez donc avec plusieurs "générations" de services dans votre SI, chacun implémentant plus ou moins bien certains standards. Cela arrivera d’ailleurs fréquemment que des équipes en oublient purement et simplement certains.
- Le temps perdu est immense. Si les équipes mettent deux jours à implémenter "from scratch" un nouveau service et que vous initialisez 80 services par an, vous avez perdu 160 jours. Le temps perdu à tenter de backport de nouveaux standards ou des bugfix (qui, si non corrigés, peuvent créer des incidents et faire perdre encore plus de temps) dans l’ensemble de vos services sera également gigantesque.
- Une réinvention de la roue (et donc encore une fois du temps perdu) entre équipes. Avoir plusieurs équipes qui implémentent la même chose en parallèle car il n’y aucun endroit défini pour partager du code (et que les canaux de communication sont mauvais) est assez triste.
Je suis persuadé que "scale" un département tech demande une cohérence très forte entre l’ensemble des services, avec une réduction extrême du boilerplate. Bref, que le socle commun soit considéré comme un produit à part entière. Cela devrait être la priorité dans toutes les boîtes à forte croissance car le gain est énorme.
On entend souvent parler de platform engineering, mais généralement seulement pour la partie CI/CD, déploiement et actions en production, bref pour l’exploitation. Mais on en parle assez peu pour la partie développement alors que c’est quelque chose d’essentiel.
Quelques exemples
Comme dit précédemment, si vous faites de l’HTTP, vous allez probablement faire de l’OpenAPI. On veut sûrement que cette spec soit autogénérée depuis le code. Vous allez vouloir sur votre serveur HTTP du tracing, des métriques (au format Prometheus par exemple, avec les bons types de métriques et les bons labels), de l’authentification, une gestion correcte des erreurs, un endpoint de health… Si vos équipes doivent configurer tout ça "à la main" pour chaque service c’est qu’il y a un problème.
Je m’attends personnellement à quelque chose comme (code sorti du chapeau mais l’idée est là):
server := http.NewServer()
server.POST("/foo", my-handler)
server.Start()
Et voilà, ce serveur devra avoir tout ce dont j’ai besoin, built-in. Quelques options pourraient être acceptées par le constructeur, mais ça s’arrête là.
Vous faites du Kafka ? Pareil, on pourrait s’amuser à écrire 80 lignes de code pour écrire un consumer depuis zéro, mais là aussi on veut des métriques, des traces, de la gestion de désérialisation, de la gestion d’erreur… Bref probablement quelque chose comme ça:
consumer := kafka.NewConsumer("topic", "group-name", handler)
consumer.Start()
Comment ?
La manière la plus simple de permettre cela est d’avoir des librairies internes fournissant un très haut niveau d’abstraction sur l’ensemble des détails techniques des services. Une lib pour de l’HTTP (client ou serveur) avec des middlewares tout prêts pour tous les besoins classiques, une lib pour faire du Kafka, une lib pour du SQS…
Au fur et à mesure des besoins, on peut en créer de nouvelles. Une problématique survient dans une équipe, on teste une solution, on la généralise, et on la rend disponible sur étagère et de manière la plus simple possible au reste de la boite.
Une équipe implémente un circuit breaker permettant d’activer ou désactiver un feature flag en fonction d’une métrique (big up aux copains), et ça marche ? Très bien, maintenant comment on fait que pour le projet suivant puisse implémenter le même pattern en maximum 5 minutes ? Et comment on fait pour qu’en cas de bug sur cette partie du code, il puisse être corrigé simplement globalement ?
A Exoscale on était allé assez loin sur cette standardisation (notamment via la lib de machine à état), et c’était très bien.
Certes, on est un peu restreint dans ce qu’on fait car il faut utiliser le socle commun mais pour être honnête j’ai passé l’âge de vouloir tout réécrire moi même parce que c’est fun. Si le socle commun est bien fait (plus facile à dire qu’à faire, TL:DR mettez pas le stagiaire en solo dessus) c’est largement plus confortable de pouvoir se focus sur le code métier plutôt que sur des détails techniques, ou de se questionner en permanence à base de "est ce que j’ai vraiment bien implémenté l’ensemble des standards de la boite ?" ou bien de se rendre compte en incident qu’en en a oublié.
On peut même dire qu’un standard non disponible sur étagère est un mauvais standard. Avoir juste de la documentation n’est pas suffisant pour avoir de l’adoption.
Qui maintient
Mais vient également la question de maintenir ce socle commun, ce "framework" interne. Il y a ici plusieurs écoles. Je suis tombé récemment sur ce message très intéressant sur Linkedin où la personne se posait également ce genre de questions:
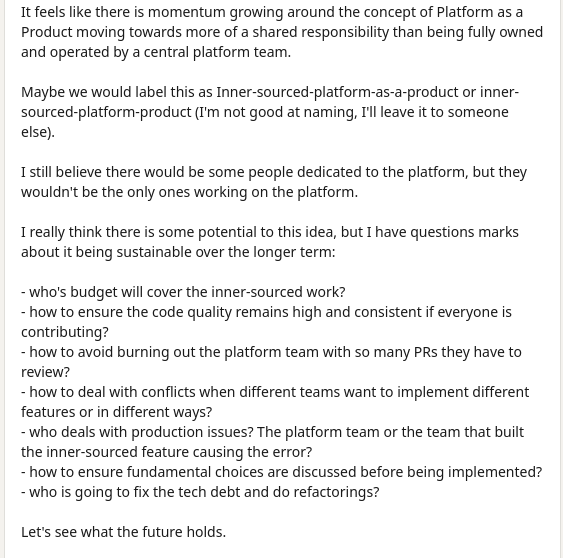
Je suis tout à faire pour l’inner source de mon côté mais la question de qui maintient quoi se pose.
Ownership partagé
Je peux déjà dire une chose: l’ownership partagé ne marche pas, et ne marchera jamais. Si tout le monde est officiellement mainteneur d’un système, personne ne l’est et les problèmes de ce système ne seront les problèmes de personne. Il faut un mainteneur officiel identifié.
Equipe platform
Vient ensuite l’école du "une équipe dédiée pour maintenir le socle commun". Appelons là l’équipe Platform.
Cette équipe se chargera du maintient du socle de libs communes (et pourquoi pas d’autres outils communs: CI/CD, templates de projets, images Docker…) de la boite. Cette équipe se chargera exclusivement du maintient de ce socle. Vu que c’est sa seule mission, elle peut s’y consacrer à 100 %. C’est cette équipe qui pourra également trancher en cas de divergence de vision sur ce qui doit être réalisé. C’est également elle qui sera responsable des potentiels problèmes (bugs) sur ces outils.
Avoir une équipe dédiée sur ce sujet officialise aussi selon moi le fait que le management ait pris conscience de l’importance d’avoir cette cohérence forte entre services.
Le risque ici est que cette équipe s’éloigne des équipes utilisatrices et ne construise pas la bonne abstraction. C’est en effet toujours possible et c’est pour ça qu’une vraie vision produit, notamment en terme d’organisation (accompagnement, retours du terrain, immersion dans les équipes, pair programming…), est nécessaire.
L’autre risque est que cette équipe se retrouve noyée sous les demandes, et si ça arrive il est intéressant de se demander pourquoi. Est ce que ce qui est produit n’est au final pas ce qui était attendu ? Trop difficile à utiliser ? Mal documenté ? Mauvais staffing ? Mais ce sont au final des problèmes classiques et similaires à des équipes de développement produit.
Ownership de chaque sous système par des équipes différentes
Imaginons que vous ayez 10 librairies (ou autres outils partagés entre équipes), et 10 équipes de développement. On pourrait très bien dire que chaque librairie se retrouve assignée à une équipe pour sa maintenance. Chaque librairie aura donc des mainteneurs officiels chargés des évolution, mais cela se fera en parallèle du travail "classique" de l’équipe de développement (délivrer de la feature).
D’un côté, on peut dire qu’ici ce sera souvent une équipe directement utilisatrice d’une solution qui se chargera de la maintenir. De l’autre, je ne suis pas sûr que cette équipe fera mieux qu’une équipe platform car la tentation sera grande ici aussi d’implémenter quelque chose pour son besoin personnel sans réussir à généraliser.
L’autre soucis ici est le temps alloué au travail sur le socle commun. On sait tous ici quel choix sera fait la majorité du temps entre délivrer une nouvelle fonctionnalité ou faire un travail sur un socle technique commun dont l’impact ne sera pas forcément immédiatement visible.
C’est toujours le même problème de priorisation de chantiers techniques par rapport au produit. L’ownership au sein des équipes peut marcher, mais cela demande une organisation difficile et des gens capables de faire contrepoids aux demandes du produit pour pouvoir prioriser ces chantiers tech. Sinon, les équipes travailleront seulement sur ce socle de temps en temps, quelques heures par-ci par-là, avec peu de vision et en n’ayant pas la capacité d’en faire un produit interne, et le résultat sera mitigé.
L’excellence technique, le nerf de la guerre
C’est l’excellence de ce socle technique, de ces fondations sur lesquelles vont reposer la tech de l’entreprise, qui permettent de décrocher la lune et d’augmenter la productivité. La tech est un asset, et une bonne tech, c’est ce qui décuple l’efficacité et permet d’écraser la concurrence en terme de delivery. Et plus vous attendez à construire ces fondations, plus vous allez vous rajouter de la dette, et plus vous allez au final ralentir. Vous payez au centuple le "on a pas le temps pour ça".
Il faut je pense avoir vécu ce genre de contexte, vécu l’énorme impact positif sur la productivité d’un socle commun avancé (ou l’inverse), pour comprendre son intérêt. "Product-first" est devenu synonyme dans notre industie de "la tech n’est pas importante, ce n’est qu’un outil pour construire le produit". Pourtant, en dehors des phases de bootstrapping/PoC jetables, la tech est essentielle car c’est elle qui permet au produit d’atteindre des sommets.
