One of my focuses this year is AI. To learn more about this topic and also build agents, I built MaizAI, an AI agent toolbox.
When I started my AI journey, I quickly noticed that providing the right context to AI assistants is the key to get relevant answers. I also wanted to quickly be able to reach out to several AI providers (Anthropic, Mistral…) and to use several models for the same context in order to compare answers. I also read about RAG to enrich contexts with custom information.
The AI market is crowded at the moment (crewai, langchain…) but I still decided to build my own tool, MaizAI. It’s a good learning exercise and I wanted to explore new approaches.
MaizAI is an API-first software that abstract AI providers (currently Anthropic and Mistral are supported but more may be added soon), manages contexts when interacting with them, and supports basic RAG features. It’s written in Golang and uses PostgreSQL both to manage contexts and for RAG (using the pgvector extension).
As an SRE, I implemented advanced observability as you will later.
This article will deep dive about how LLM APIs and MaizAI works, and explain my vision about how to build AI-powered tools. I’ll show you how I started building my own coding assistant with MaizAI.
This article may show updated commands, see the project README for up-to-date doc.
API-first and AI "platformization"
I don’t like closed systems. For example, I think forcing people to use a specific IDE to get AI capabilities is not a good idea. I also never managed to find the Github copilot API description, it seems they only provide IDE plugins to interact with it. Why? Are we back to Windows DLL?
As a SRE, I care about platform engineering. I want to provide tools to users that can be used through API and standard tooling (CLI targeting the API for example). This is I think the direction that AI-related tools should take, similar to what happened in the infrastructure world years ago. We should build products that let users build on top of them, which is IMO often not the case today in the AI world.
That’s why MaizAI is API-first: it standardizes how to do a lot of things, and hide the complexity behind a simple API (see the OpenAPI spec for details) and simple tooling (a CLI at the moment).
Context management in MaizAI
One of the most common use case for AI is chatbots. Usually, chatbots are built by providing to each new message sent to the AI provider previous answers.
First, you’ll ask your question (and give additional context to guide the AI provider), for example: What’s the French population?. The provider will give you an answer: As of my last update in October 2023, the population of France is approximately 67.4 million people.
You then want to continue the conversation, for example asking Can you compare it with the population from 100 years ago?. What you’ll provide to the AI provider is not only the latest question but all the conversation, and all of this information (the context) will be used to compute the next answer. A conversation doesn’t exist per se, it’s just a brand new API call with all the previous inputs and outputs provided as context.
It means that to build a conversational AI assistant, you need to save all interactions (questions and answers) with the AI provider in order to be able to provide them again later.
But contexts are not only important for conversational agents. If you’re building a coding assistant, you will need to provide parts of the codebase you’re working on (for example, the file you’re currently editing). Without context, LLMs will only provide generic answers which are not really interesting for a lot of use cases.
Conversations with MaizAI
MaizAI stores and allows you to manipulate contexts. Let’s start a conversation using Mistral with it:
maizai conversation \
--provider mistral \
--model mistral-small-latest \
--system "you're a general purpose AI assistant" \
--interactive \
--context-name "my-context"
Hello, I'm your AI assistant. Ask me anything:
Why is the sky blue?
Answer (input tokens 18, output tokens 162):
The sky appears blue due to a particular type of scattering called Rayleigh scattering. As light from the sun reaches Earth's atmosphere, it is scattered in different directions by the gas molecules and tiny particles in the air. Blue light is scattered more than other colors because it travels in shorter, smaller waves. This is why we perceive the sky as blue most of the time. [...]
Anything else (write 'exit' to exit the program)?
This command interacts with the LLM provider and will automatically create a context (named my-context in this example). All inputs (your question) and outputs (LLMs responses) are automatically stored in the context database by MaizAI.
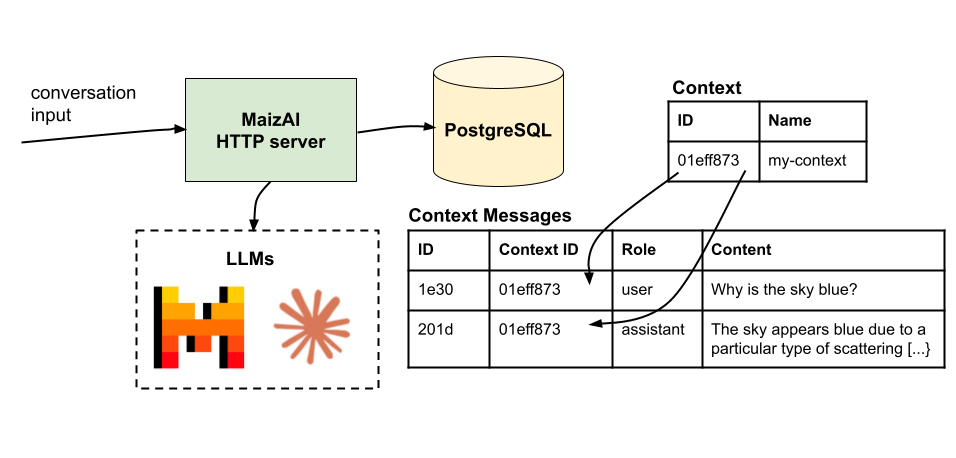
As you can see, MaizAI abstracts LLM providers: you just have to select the one you want to use, and the model to use. All interactions will be saved in its database (in a context and context_message table.
You can for example list contexts:
maizai context list
{
"contexts": [
{
"id": "01eff873-1e30-65de-8980-a6567a017827",
"name": "my-context",
"created-at": "2025-03-03T21:04:38.320688Z",
"sources": {}
}
]
}
But also get details about a given context: see how the messages are stored:
maizai context get --id 01eff873-1e30-65de-8980-a6567a017827 | jq
{
"id": "01eff873-1e30-65de-8980-a6567a017827",
"name": "my-context",
"sources": {},
"messages": [
{
"id": "01eff873-1e30-6b20-8980-a6567a017827",
"role": "user",
"content": "Why is the sky blue?\n",
"created-at": "2025-03-03T21:04:38.320683Z"
},
{
"id": "01eff873-201d&-6c7b-8980-a6567a017827",
"role": "assistant",
"content": "The sky appears blue due to a particular type of scattering called Rayleigh scattering. As the sun's light reaches Earth's atmosphere,[...]",
"created-at": "2025-03-03T21:04:41.553832Z"
}
],
"created-at": "2025-03-03T21:04:38.320688Z"
}
You can start again a conversation with a LLM provider at any time by providing an existing context ID to the maizai conversation command, or start a fresh one by providing a context name that will be used to create a new context. And for each interaction, you can target a different LLM provider and model.
Managing contexts
We saw earlier how to create a conversation and retrieve contexts. But MaizAI is way more powerful.
You can for example add a message to an existing context without having to go through a LLM provider:
maizai context message add --id 01eff873-1e30-65de-8980-a6567a017827 --message "user:Is Mars sky blue?"
{"messages":["messages added to context"]}
This new message will be added to the context and passed to the LLM provider next time you use it. In the same way, you can update or delete existing messages by using the message delete and message update subcommands, or even create brand new contexts using maizai context create.
This is interesting: it means you can carefully craft your context before interacting with a LLM provider, and if needed edit it afterward. You didn’t like your prompt and the associated LLM answer for a given conversation? Just delete it.
Context Forking
What I described before has one drawback: every time you use a context, it’s modified because new messages are appened to it. Yes, you can modify it afterward but sometimes it can be tedious. That’s why MaizAI supports "forking" a context by creating context sources.
Let’s create a new context with one message, that will use our previous conversation about the sky color as a source:
maizai context create --name "new-context" --message "user:give me more details about why the sky is blue" --source-context 01eff873-1e30-65de-8980-a6567a017827
{"messages":["context created"]}
This command creates a new context named "new-context", with one message and with the context ID 01eff873-1e30-65de-8980-a6567a017827 as a source. Adding existing messages or a source to a new context is optional.
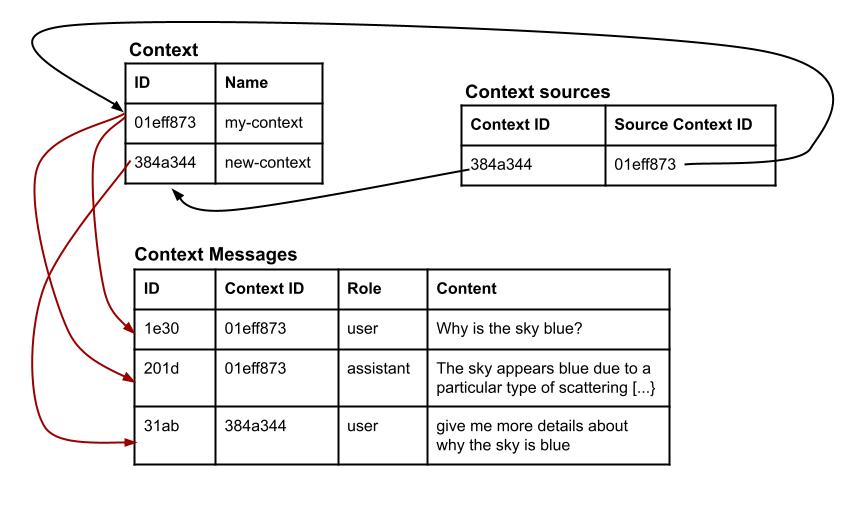
When you use this context, MaizAI will:
- Fetches all messages from the source contexts
- Fetches all messages from the current context
- Reach out to the LLM provider by providing all messages, in the right order, plus your prompt.
This feature is really cool because it allows you to fork a conversation at any time. It also allows you to build generic contexts for your organization or for specific use cases/products, and then reference them every time you interact with a LLM provider without modifying them. If a context source is modified (for example a message is added or deleted), all existing contexts using it as source will use the new version when used.
Context sources are recursive: you can have several layers of contexts referencing themselves and MaizAI will fetch all of this (but I haven’t implemented cycles detection then :D).
You can also manage sources for an existing context with the context source add-context and context source delete-context subcommands.
RAG
We saw before the importance of providing a good context when interacting with LLMs, and how MaizAI helps you managing contexts. Today’s LLM supports large contexts, with sometimes hundreds of thousands of tokens that can be passed as input. But it can be costly and may not work well for large datasets where only a subset is relevant for a given conversation.
RAG (Retrieval Augmented Generation) is a technique that helps extract relevant information from a dataset and provide them when interacting with a LLM. A large dataset will be split into "chunks" (sentences, paragraphs…), converted into a vector embedding (an array of float64) and stored in a database.
You can then search this vector database when interacting with an LLM and provide as context the relevant chunks.
MaizAI has basic support for RAG by using pgvector on top of PostgreSQL.
First, create a document in MaizAI. It will be used to group text chunks for a given source (for example a book):
maizai document create --name "my-doc" --description "description"
{"messages":["document created"]}
You can now embed texts for this document:
maizai document embed
--document-id 01eff9c9-a727-6b94-8dc4-a6567a017827
--input "Mathieu Corbin is the author of the mcorbin.fr blog"
{"messages":["document chunk created"]}
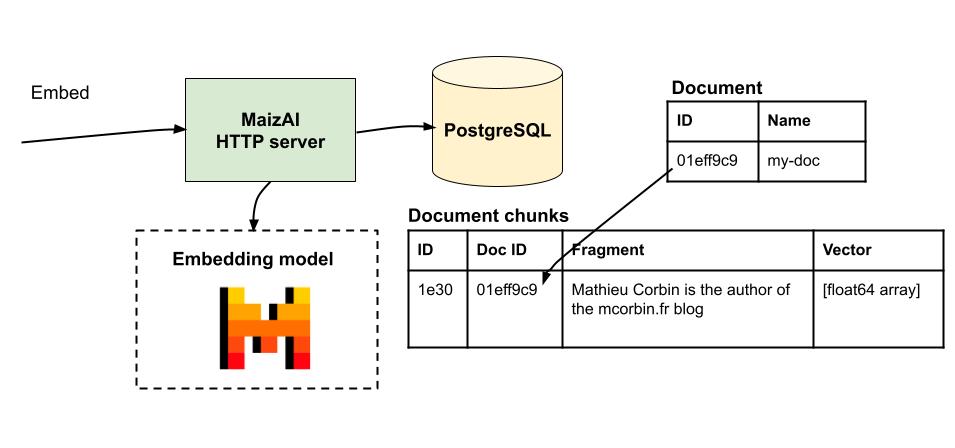
What MaizAI does is:
- Reaching out to an embedding API/model to generate a vector from the input (at the moment only
mistral-embedis supported) - Storing the vector alongside the input (fragment) in its database.
- Allowing users to enrich contexts using the text fragments.
This is how you can query chunks with MaizAI:
maizai conversation
--provider mistral \
--model mistral-small-latest \
--system "you're a general purpose AI assistant" \
--context-name "context-with-rag" \
--rag-model mistral-embed \
--rag-provider mistral \
--rag-limit 1 \
--rag-input "Information about Mathieu Corbin" \
--prompt "Who is Mathieu Corbin? Use this context to help you: {maizai_rag_data}"
{
"result": [
{
"text": "Based on the context provided, Mathieu Corbin is the author of the mcorbin.fr blog. However, without additional information, I can't provide more details about his background, expertise, or the content of his blog. If you have more context or specific questions about Mathieu Corbin or his blog, feel free to share!"
}
],
"input-tokens": 38,
"output-tokens": 66,
"context": "01eff9cb-2fa3-6bae-8dc4-a6567a017827"
}
In this example, we ask the RAG information about Mathieu Corbin, and limit the number of chunks returned to 1. The data retrieved will replace the {maizai_rag_data} placeholder in the prompt.
You can also query MaizAI’s RAG by using the embedding match command. This can be helpful to validate that your RAG is returning proper information:
maizai embedding match --input "Information about Mathieu Corbin" --limit 1 --model mistral-embed --provider mistral | jq
{
"chunks": [
{
"id": "01eff9ca-bc61-694f-8dc4-a6567a017827",
"document-id": "01eff9c9-a727-6b94-8dc4-a6567a017827",
"fragment": "Mathieu Corbin is the author of the mcorbin.fr blog",
"created-at": "2025-03-05T14:04:21.096893Z"
}
]
}
Quite nice, no?
Building a coding assistant
Recently I started building a coding assistant based on MaizAI, and used it in my editor (Emacs).
Thanks to MaizAI flexibility, it’s quite easy. Remember what I said before about API-first/platforms? I really think the approaches taken by MaizAI are what should be done.
For example, I implemented this emacs function that reads the current opened file (buffer), asks for a prompt, reaches out to MaizAI to generate content based on the existing code and the prompt, and then puts it in the file. The conversation.sh script is just a script calling the maizai conversation command with a system prompt tailored to my needs:
(defun maizai-chat-buffer ()
"generates content based on the current buffer and a prompt"
(interactive)
(let ((buffer-content (buffer-string))
(prompt (read-string "prompt: ")))
(let ((command (concat "prompt=$(cat <<EOF\n"
buffer-content
"\n"
prompt
"\nEOF\n"
")\n"
"/home/mcorbin/.local/conversation.sh $prompt")))
(progn
(insert (shell-command-to-string command))
(message "buffer completed")
))))
Does it work? HELL YES.
I asked for this prompt in my IDE:

A few seconds after I got this output:
And it compiles, while reusing some patterns I used elsewhere in the file.
As you can see, thanks to MaizAI capabilities and the fact that it’s an "open" tool (CLI, API, so easy to iterate on when building on top of it), integrating it with Emacs took me literally a few minutes.
Observability
MaizAI provides a /metrics endpoint exposing metrics about the Golang runtime and the HTTP API (requests rate, latency… with the right labels).
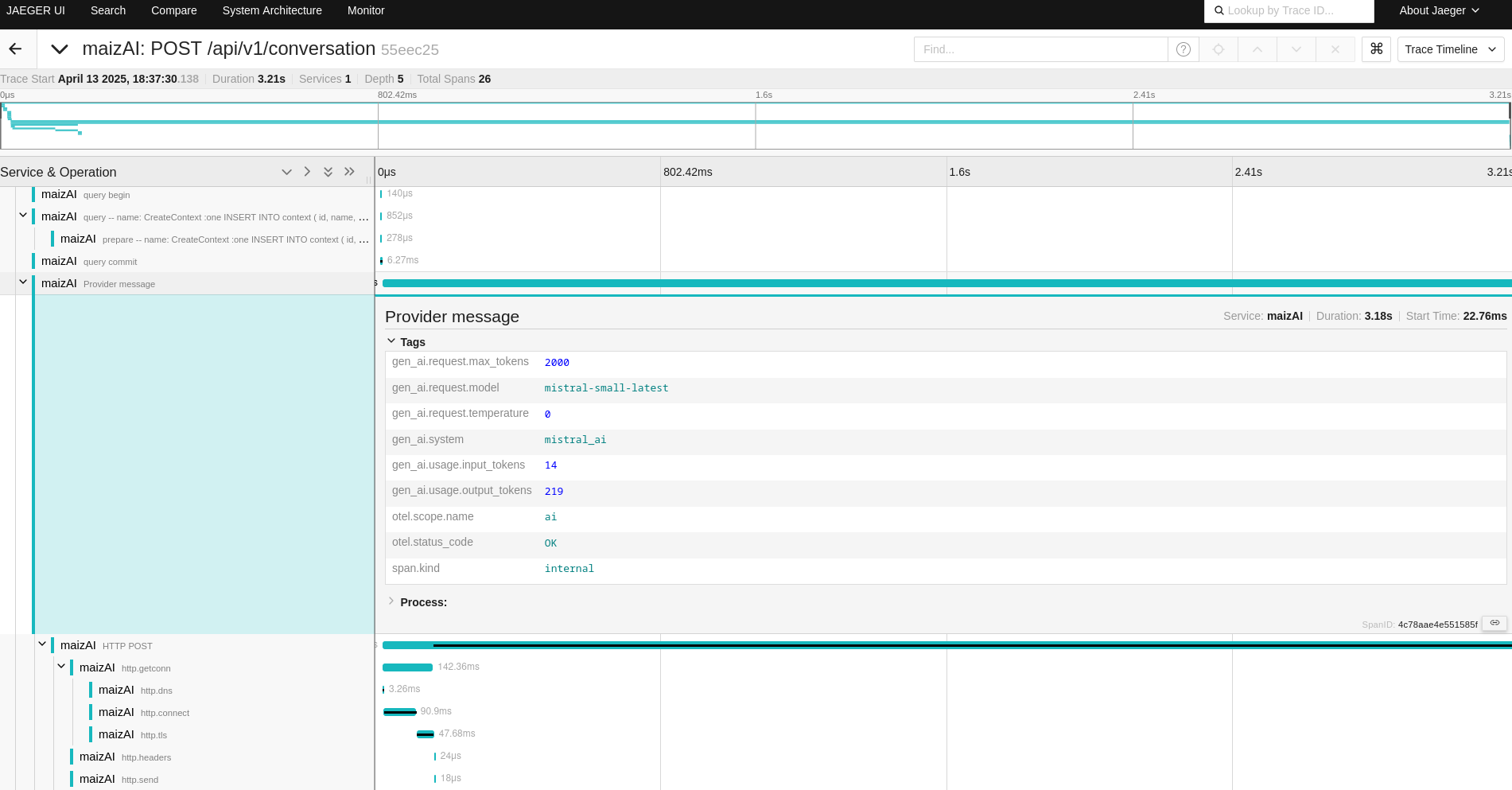
More interestingly, it implements end-to-end tracing using Opentelemetry, with proper attributes like the Gen AI semantic conventions. Thanks to this you can see precisely how any request behaves while getting information like the number of input or output tokens that were used. All the HTTP and SQL layer is also traced:
What’s next
I’ll continue to use MaizAI to build an awesome assistant for my day to day work. I’m sure I can build something awesome (If I can find the time for) by relying on MaizAI core features (like: building new contexts based on some files, easily switching between contexts and LLM providers/models, build best-practices contexts that can be used as source, indexing external documentation in MaizAI RAG…).
For MaizAI itself, there are several features I would like to add short-term:
-
Better documentation: I know all of this may be a bit blurry if you just discover the project so I want to make it really easy to get started with it.
-
Categories/Labels for contexts and documents, to organize them but also filter on them when during RAG queries. For example, I could have some documents labeled as "Golang" and only use them when working on a Golang codebase, which may greatly reduce the number of chunks to process when doing vector queries.
-
Prompt caching: it should be easy to add (probably an optional "caching" boolean parameter attached to messages and stored in the database)
-
MCP support: I really want MaizAI to be able to call tools. The idea behind MCP is nice (a standard to interact with tools etc) but I find the current implementation terrible: using SSE was I think a terrible idea, especially in a modern/immutable/ephemeral infrastructure world where applications instances or the underlying infrastructure (like virtual machines) comes and goes. Managing long-living connections is difficult (pings, reconnection mechanisms)…
It’s just complexiying a lot the implementation and at the end it will be half buggy for production use cases. Hopefully it seems that SSE will be optional soon so I’m waiting for this to support it. -
Maybe a user interface but I really don’t like frontend development: don’t hesitate to build one if you want to ;)
Want to try the project? Check the project README and don’t hesitate to give me feedbacks!