Dans cet article, j’expose 3 problèmes que j’ai rencontré dans ma carrière avec le DNS sur Kubernetes. Le 3eme est d’ailleurs un bug non corrigé à ce jour sur kube-proxy en mode iptables, et impacte notamment tous les clusters AWS EKS. Lisez bien jusqu’à la fin si vous êtes dans ce cas.
Bien que Kubernetes soit un super outil que je recommande dans énormément de contextes, il y a plusieurs mauvaises idées dans son implémentation et notamment dans la gestion du DNS.
ndots
Le problème
Ce sujet a déjà été traité en long, en large, et en travers.
Lorsqu’un pod démarre dans votre cluster, son fichier /etc/resolv.conf ressemble à un truc comme ça:
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
Chez les cloud providers comme AWS vous aurez même parfois quelques entrées supplémentaires. Voyons un peu ce que tout ça veut dire avec un man resolv.conf:
search Search list for host-name lookup.
By default, the search list contains one entry, the local domain name. It is determined from the local hostname returned by gethostname(2); the local domain name is taken to be everything after the first '.'. Finally, if the hostname does not contain a '.', the root domain is assumed as the local domain name.
This may be changed by listing the desired domain search path following the search keyword with spaces or tabs separating the names.
Resolver queries having fewer than ndots dots (default is 1) in them will be attempted using each component of the search path in turn until a match is found. For environments with multiple subdomains please read options ndots:n below to avoid man-in-the-middle attacks and unnecessary traffic for the root-dns-servers.
Note that this process may be slow and will generate a lot of network traffic if the servers for the listed domains are not local, and that queries will time out if no server is available for one of the domains.
ndots:n
Sets a threshold for the number of dots which must appear in a name given to res_query(3) (see resolver(3)) before an initial absolute query will be made. The default for n is 1, meaning that if there are any dots in a name, the name will be tried first as an absolute name before any search list elements are appended to it. The
value for this option is silently capped to 15.
Qu’est ce que ça veut dire exactement ? Prenons un exemple: si une application tente de faire une résolution DNS pour google.com sur Kubernetes, donc avec un ndots (nombre de points) < 5, ces resolutions seront réalisées:
- google.com.default.svc.cluster.local
- google.com.svc.cluster.local
- google.com.cluster.local
- google.com
Oui oui, 4 résolutions avec donc une charge accrue sur votre serveur DNS + une latence plus importante côté client.
Pourquoi ? Car Kubernetes essaye d’être intelligent pour que les gens puissent utiliser, pour cibler par exemple un service kubernetes interne, toto, toto.namespace, toto.namespace.svc sans trop avoir à se poser de questions sur au final comment le DNS fonctionne (l’objectif étant de finir d’une manière ou une autre sur toto.default.svc.cluster.local).
Bien sûr, ça marche très mal car personne fait attention. J’ai vu des clusters avec 4 fois plus de réponses NXDOMAIN que de succès côté DNS. Bref, c’est complètement nul, mais comment on corrige ça?
Le fix
Il y a 2 manières de changer ce comportement:
- Utiliser des FQDN: par exemple, au lieu de
google.com, utilisezgoogle.com., avec un point à la fin du domaine. Oui, c’est pas courant mais c’est valide. Pareil pour vos services Kubernetes, utilisez les noms longs typetoto.default.svc.cluster.local.partout. Cela évitera de passer par la liste de search de la mort. - Changer la valeur du ndots, à 1 par exemple. Cela permet de tenter d’abord une résolution sur le domaine utilisé avant d’aller parcourir les search.
Lameduck
Le problème
Les services Kubernetes permettent d’exposer plusieurs instances d’une application (pods) derrière un endpoint unique. Par défaut, cela est géré par kube-proxy, iptables et du NAT pour créer du simili load balancing entre les pods derrière un même service.
Un service Kubernetes a donc un domaine (toto.default.svc.cluster.local par exemple) et une IP pour ce domaine. Si vous avez 4 pods (replicas) pour une application derrière un service, vous aurez donc une règle iptables par pod sur vos noeuds pour gérer la redirection des connexions vers les vrais IPs des pods cibles.
Mais comme partout, les pods Kubernetes ont un cycle de vie, donc sont parfois supprimés: downscaling, mise à jour de l’application… les raisons ne manquent pas.
Quand on pod est supprimé de Kubernetes, en simplifiant (voir la doc pour plus de détails), il se passe ceci:
- Le pod passe en état terminating.
- Toutes les connexions vers ce pod continuent de fonctionner mais les nouvelles vont aller ailleurs (sur des pods en état running).
- Les connexions existantes se terminent (l’application cible doit avoir du graceful shutdown et les terminer de manière correcte), le pod s’éteint, proprement drain.
Tout le monde est content: on a perdu 0 requête durant le rollout.
Sauf que… en réalité, Kubernetes maintient deux choses pour permettre cela:
- Des ressources de type EndpointSlice, qui définissent pour chaque IP derrière un service (donc chaque pod) un status:
ready,terminating… - kube-proxy qui va faire sa sauce côté iptables (ou autre) en fonction des EndpointSlices et notamment de leurs mises à jour (par exemple, l’une passant de
readyàterminatingva demander une mise à jour des règles sur l’ensemble des noeuds).
Et le problème ici est le temps de convergence de tout ça. De kubectl delete pod toto-1 à kube-proxy a mis à jour toutes les règles sur les noeuds pour ne plus envoyer de nouvelles connexions au pod, il peut se passer du temps: une ou deux secondes par exemple.
Prenons l’exemple d’une application en Go, qui sur un SIGTERM s’éteint très rapidement, comme par exemple…CoreDNS, notre serveur DNS sur Kubernetes.
Quand on demande la suppression d’un pod, il est quasi immédiatement supprimé pour de vrai (l’application s’éteint). Sauf que si kube-proxy n’a pas encore convergé, les applications continueront d’envoyer leurs requêtes DNS à un pod (enfin, à une IP) qui n’existe plus, ce qui causera des erreurs.
Le fix
La configuration de CoreDNS contient un paramètre lameduck, par défaut non configuré. Par exemple lameduck 5s ajoutera un délai de 5 secondes côté CoreDNS avant qu’il s’éteigne, permettant à kube-proxy d’avoir le temps de réconcilier.
Pour la petite histoire, AWS a rajouté cette option par défaut sur son offre EKS à ma demande en 2023, j’aime à pensé que j’ai amélioré les SLI de milliers d’entreprises ;)
Le problème existe sur toutes les applications. Un conseil, mettez un preStop: sleep 5 sur tous vos pods applicatifs. C’est dégueu mais malheureusement nécessaire.
Le clou du spectacle: conntrack
Le problème
Accrochez vous car on est sur un bug kube-proxy qui n’a à ce jour aucun fix.
J’ai la chance de travailler sur une infrastructure très dynamique et où les noeuds Kubernetes passent leur temps à être recréés, notamment via l’utilisation de Karpenter. Sa façon d’optimiser l’infrastructure (instances spot, consolidation…) combinés à des TTL faibles sur les noeuds (24 à 48H) font que l’infrastructure se reconstruit plusieurs fois par jour. Gardez ça en tête c’est important pour la suite.
En parallèle, on est en 100 % tracing (opentelemetry) sans sampling, donc on a un énorme niveau de détails sur ce qu’il se passe dans l’infrastructure. Et un jour un dev vient nous voir car il voit des lenteurs DNS.
Et en effet, il se passe un truc bizarre: regardez moi ces durées de résolution et notamment comment ça décroit de 5s vers 0s en fonction du timestamp:
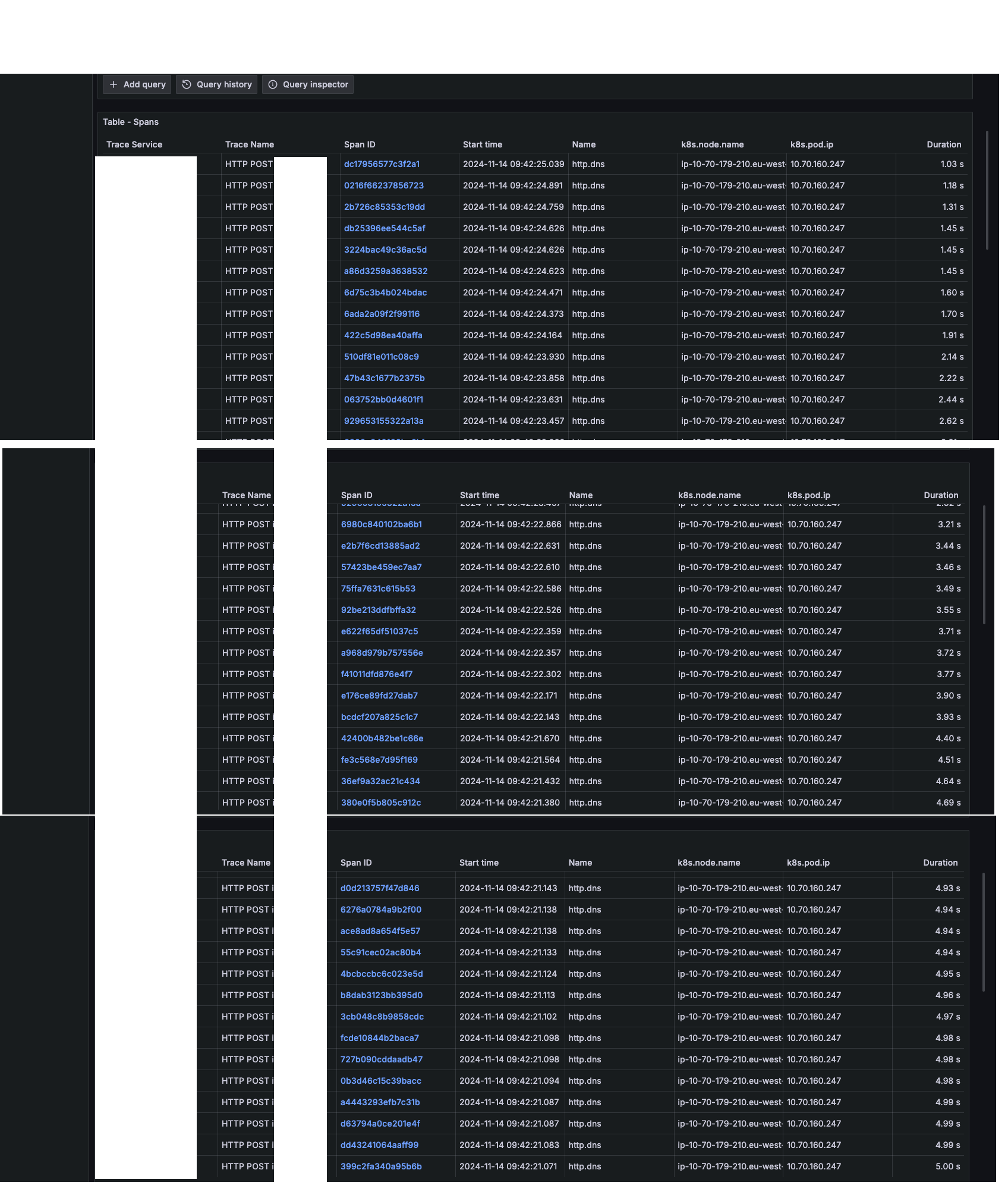
W.T.F.
Assez rapidement, je vois que cela apparaît quand un pod CoreDNS est supprimé. Je vérifie les suspects habituels (lameduck, performance du serveur DNS etc), tout est bon, et les métriques sont bonnes (aucune latence côté serveur). Et je vois toujours le même comportement:
- Un pod CoreDNS est supprimé (un
kubectl delete po -n kube-system <pod>) - Au moment de l’arrêt final du pod (donc après la durée du lameduck, après la réconciliation kube-proxy qui a bien mis à jour les règles iptables pour enlever l’entrée…), j’ai pourtant une perte de trafic
Allez, on sort tcpdump sur une application cliente et on regarde ce qu’il se passe:
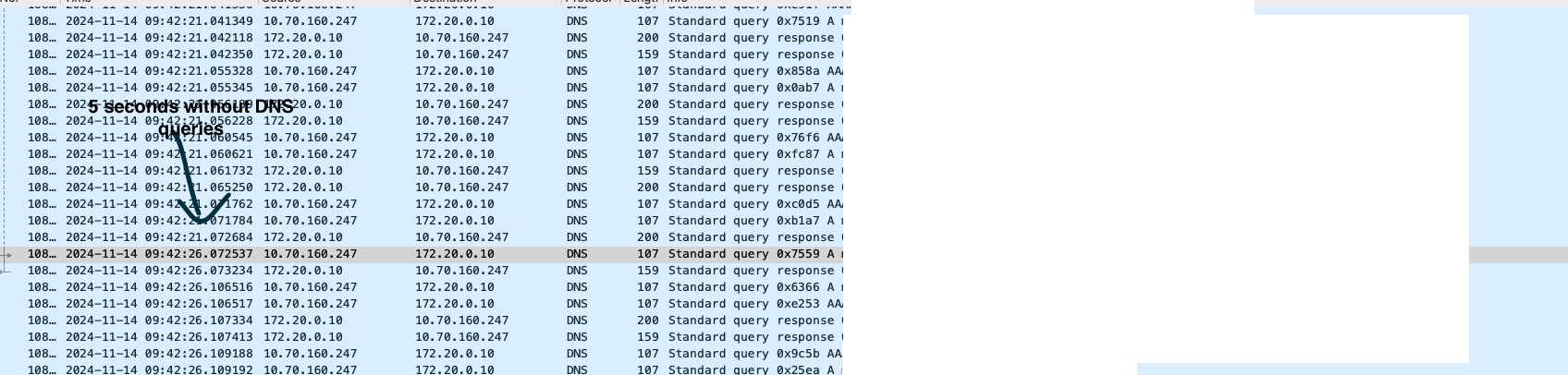
On voit bien un trou de 5 secondes où aucune requête n’est visible puis à un moment ça se "débloque". Et ça explique l’aspect "décroissant" dans mes traces: vu que l’application reçoit des requêtes (et donc emet des requêtes DNS) en continu, à t=0s, elles sont bloquées pendant 5 seconde. A t=1s, 4 secondes. A t=2s, 3 secondes… jusqu’à ce que ça débloque et que ça remarche correctement.
Mais la latence ajoutée pendant ces 5 secondes est intolérable notamment si vous redémarrez vos pods 20 fois par jour.
Je découvre aussi que rajouter un timeout 3 dans /etc/resolv.conf montre un trou de 3 secondes.
On récapitule: les règles iptables (et les endpointslices coredns) sont bonnes et convergent rapidement, les perfs du serveur DNS sont bonnes, je n’ai qu’une explication: la conntrack.
En effet, sans connaître les détails d’implémentation, je sais que kube-proxy nettoie la conntrack lorsqu’un pod est définitivement supprimé. Et c’est exactement à ce moment là que je vois le problème.
Après quelques investigations et une issue sur le Github de Kubernetes, c’est bien ça: il y a une race condition dans le process de cleanup de la conntrack qui fait perdre du trafic UDP quand un pod est supprimé (ce problème n’existe pas en TCP), et donc ça impacte le DNS.
Tout vient bien d’un bug dans Kubernetes.
Le fix
En kube-proxy en mode iptables, il n’y a aujourd’hui pas de fix (et pas sûr qu’il y en aura un selon la rumeur). Je n’ai pas testé de reproduire sur les implémentations à base de cilium/ebpf (où kube-proxy est remplacé) mais il y a des chances qu’elles n’aient pas ce problème.
Malheureusement, certains cloud, dont AWS, ne proposent que kube-proxy en iptables aujourd’hui.

Il y a par contre 2 moyens de régler partiellement le problème:
- Ajouter à vos pods un block dnsConfig et passer un timeout à 2 ou 3 secondes: c’est toujours mieux que 5.
- Limiter le redémarrage de vos pods CoreDNS: isolez les sur des noeuds que vous ne mettez à jour qu’une fois toutes les 2 semaines par exemple, à une heure de faible activité. Cela limitera énormément l’apparition du problème.
Il paraît que NodeLocal DNSCache permet aussi de régler (totalement ? Je ne sais pas) le problème mais je n’ai pas testé et ça me saoule profondément d’avoir à maintenir une brique en plus à cause d’un bug.