"Kubernetes c’est bien que pour les grosses entreprises", "On est pas Netflix et Google", "Sans milliers de conteneurs ça sert à rien"… Vous avez déjà vu ces commentaires sur Kubernetes ? Ces gens ont tout faux. Voici pourquoi.
Mais d’abord, repartons 10-15 ans en arrière, avant 2015 et donc avant Kubernetes.

Docker vient tout juste d’apparaître, et on en voit nulle part en production sauf exception (un peu de Mesos vers 2015).
On voit déjà beaucoup d’outils d’infrastructure as code (Ansible, Puppet, Chef…) pour gérer la configuration des machines (bare metal ou virtuelles) et le déploiement des applications. Le cloud est bien sûr déjà très présent mais beaucoup de boîtes n’ont pas encore fait leur "move to cloud".
Ce qui est intéressant, c’est que les problématiques étaient similaires à aujourd’hui: on essayait d’avoir des infrastructures tolérantes aux pannes, faciles à administrer, reproductibles, avec des déploiements fréquents, une flexibilité sur la configuration des machines et des applications, autonomie des équipes de dev pour les déploiements…
Bref, comme aujourd’hui. Et tout ça, on en a besoin même si on ne s’appelle pas Netflix ou Google, dès qu’on a des équipes de développement qui maintiennent plusieurs applications en production on commence à travailler sur ces sujets.
Bref, comment on faisait pour gérer de manière fiable un certain nombre d’applications en production?
Réseau
On va commencer par décrire certains patterns en lien avec le réseau et le load balancing.
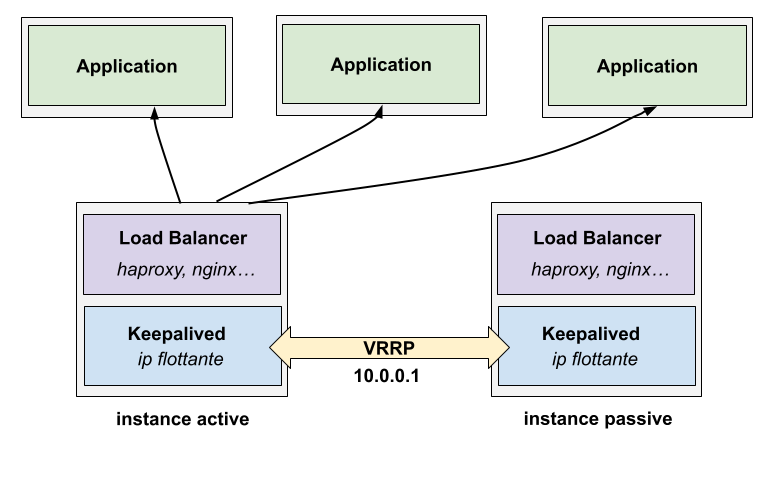
On avait souvent un étage de load balancing sur des machines virtuelles, avec HAProxy par exemple. Keepalived, un autre composant installé sur ces machines, permettait d’avoir de l’actif/passif sur les load balancers via une IP flottante qui pouvait se "déplacer" sur un autre noeud en cas de panne du noeud actif.
Ça marche, mais ça reste de l’actif/passif avec un peu de downtime pendant la bascule. Mais ce n’était pas pour moi le plus gros problème concernant le load balancing.
Les règles de load balancing entre plusieurs applications en fonction de préfixes, du nom de domaine (TLS SNI), ou autre en fonction des besoins se faisaient également dans les fichiers de configuration de manière spécifique à chaque outil de load balancing.
Service discovery et rollout
Dans l’exemple montré, on voit qu’il y a 3 instances de l’application derrière le load balancer. Les IP/port de ces backend devaient être dans la configuration du load balancer. Rajouter une nouvelle instance demande de mettre à jour le fichier de configuration.
De la même façon, enlever une instance (même temporairement: en cas de mise à jour de l’application par exemple) était pénible. Pour faire ça proprement, il faut:
- Drain les connexions vers l’instance qui va être supprimée au niveau du load balancer
- Mettre à jour l’instance
- Reconfigurer le load balancer pour la rajouter au pool
On faisait ça par exemple avec Ansible, qui allait faire cette orchestration en plusieurs machines à chaque modification de l’infrastructure. Un rollout complet en cas de nouvelle version d’une application pouvait se lancer, instance par instance, avec Ansible en serial: 1 par exemple, et c’était à nous (sysadmin) de concevoir toute cette logique de mise à jour.
D’ailleurs, comment fonctionnait le service discovery? Comment l’outillage savait quelle application était sur quelle machine, notamment en cas d’ajout ou suppression? On voyait généralement 2 patterns:
- L’utilisation de l’inventaire de l’outil d’infra as code (Ansible, Puppet…). L’outil avait la connaissance de toutes les machines et des rôles/applications associées. Cette liste pouvait être construite dynamiquement au démarrage, par exemple en récupérant la liste des instances sur un cloud en fonction de tags spécifiques.
- Via des systèmes un peu plus évolués comme Consul (2014) ou autre, et ensuite du DNS SRV ou templating de configuration par exemple.
Bien sûr, ça ne s’arrêtait pas là. Quand vous aviez 5, 10, 15… applications qui parlaient ensemble, il fallait bien gérer le truc. On peut aussi parler d’iptables qui devait se configurer également sur chaque machine et être mis à jour à chaque changement de topologie.
Tolérance aux pannes
On voyait assez peu d’auto-rémédiation en cas de panne. J’ai déjà montré l’exemple de Keepalived avant, quand ça plantait d’un côté, on allait debug, et on relançait. De la même manière, si on perdait une machine, généralement on allait voir ce qu’il se passait, éventuellement on en démarrait rapidement une autre et voilà.
On voyait déjà certains patterns plus avancés, sur le cloud par exemple, avec des autoscaling group pilotant un pool de machines virtuelles avec mise à jour automatique des load balancers en cas de changement, mais globalement les infrastructures étaient assez statiques, avec peu voire pas du tout de boucles de réconciliation.
Ce point sera important pour la suite.
Gestion des ressources
On avait donc des machines virtuelles ou serveurs physiques pour les applications: 4 CPU et 8GB de mémoire, 16 GB et 32GB… et c’était à nous d’aller déclarer dans l’infra as code "on veut cette application sur cette machine".
Je trouve que ça créait beaucoup de gaspillage car réaliser ce travail d’allocation à la main était pénible et pouvait être source de problèmes (voire de sécurité en cas de non isolation des applications). Un pattern courant était de mettre une application par machine, et voilà: ça simplifiait aussi les maintenances car sinon mettre à jour un noeud pouvait vite devenir complexe.
Gérer de l’affinity/anti affinity était aussi très pénible, et passait aussi généralement via les inventaires des outils d’infrastructure as code.
Sécurité
La gestion et distribution de certificats TLS pouvait aussi être pénible (là aussi, très statique et à intégrer dans le cycle de vie de l’application). J’ai déjà mentionné iptables avant qui était un enfer à gérer.
Côté secrets/credentials, on voyait un peu de tout mais souvent ça faisait de l’ansible vault ou l’équivalent dans d’autres outils (Puppet etc).
Gestion des logs
Configuration via logrotate, systemd et journald pour les plus chanceux qui avaient accès à des distributions récentes… c’était pénible à gérer car à configurer pour chaque application.
Packaging
Chaque "stack" (Java, Python, Ruby…) ou chaque application d’infrastructure (Kafka, Logstash…) avait sa façon de se déployer. On avait pas la standardisation de Docker donc on voyait de tout:
- Des gens qui créaient des fichier
.rpmou.debpour leurs applications (je l’ai fait, un enfer à maintenir) - Des gens qui shippaient des .tar.gz, .jar ou autre sur les machines (dans du
/optou autre, en faisant attention de ne pas planter la version de l’application qui était encore en train de tourner)
Il fallait ensuite se farcir la configuration des services (systemd quand on avait de la chance, ou du script shell degueu avec init pour les autres).
Et je n’ai même pas parlé de cronjobs et autres joyeusetés.
Stockage
Là aussi, si votre application avait besoin de configuration de stockage spécifique (volumes, nfs…), c’était par machine. L’application devait se déplacer sur une autre machine? Enjoy ton petit playbook pour détacher d’un côté/rattacher de l’autre tout comme il faut.
Boucles de réconciliations
Comme dit précédemment dans la partie Tolérance aux pannes, on n’était pas vraiment sur de l’infrastructure dynamique. Quand un truc plantait, on faisait en sorte que ça ne cause pas de downtime mais on n’était pas vraiment dans une logique d’automatisation de la remédiation (même si on tentait d’éviter les drifts via l’infrastructure as code en faisant tourner les outils régulièrement).
Standardisation
Je pourrais continuer encore longtemps, mais je pense que vous commencez à comprendre l’idée derrière cet article: on devait tout faire "à la main", et pire, on réinventait en permanence la roue!
Chaque entreprise avait sa "stack" pour faire tout ça sous la forme d’une grosse collection de scripts shell, playbooks, cookbooks chef/puppet… Je me rappelle avoir maintenu plus de 100 rôles Ansible à un moment, chacun gérant les détails présentés précédemment.
La charge de travail et la maintenance était importante.
Il fallait ensuite essayer de simplifier tout ça pour le rendre digeste par les équipes, que ce soit ops (pour nous simplifier la vie), ou dev (on voulait qu’ils soient autonomes pour configurer une application), et donc construire une interface fournissant une expérience utilisateur correcte.
Je me rappelle avoir conçu des rôles Ansible génériques où les équipes n’avaient qu’à remplir un YAML avec les informations de l’application pour pouvoir la déployer (tiens, ça me rappelle quelque chose…).
Complexité
Kelsey Hightower, qui a beaucoup travaillé sur Kubernetes, a je pense tout résumé dans ce message:
Franchement, comment peut-on penser que les usines à gaz qu’on (je m’inclus dedans) gérait avant étaient plus simples que Kubernetes?
C’était d’une lourdeur extrême, construit petit à petit en empilant des scripts pour que ça marche, et où chaque nouvel arrivant dans l’entreprise devait réapprendre l’intégralité du système.
C’est sûr, la personne qui avait roulé sous ses aisselles Ansible/Puppet/Chef pendant 3 ans pouvait trouver ça "simple", mais ça ne l’était pas. C’est une fausse idée de la simplicité ("c’est plus simple car je l’ai construis moi même").
Et très peu de boîtes géraient les edge cases correctement, notamment sur la partie réseau, déploiement, rollout…
Kubernetes
Puis Kubernetes est arrivé. Tout ce que je décris précédemment, vous le remplacez par quelques ressources YAML ayant un format prédéfini: deployment, service, ingress, configmap, secret.
Vous faites kubectl apply, ça déploie. Une nouvelle version ou changement de configuration? Vous mettez à jour votre YAML, vous appliquez, ça rollout proprement: drain, health checks, configuration fine du rollout si besoin, health checks…
- Service discovery et load balancing? Built in (
ServiceetIngress), avec tous les cas pénibles gérés automatiquement - Configuration et secrets? Built-in (
ConfigmapetSecret) - Scaling? Built-in (
HorizontalPodAutoscaler) - Stockage? Built-in (
PersistentVolumeClaim) - Firewalling? Built-in (
NetworkPolicy, où vous exprimez "ouvre tel port entre ce groupe d’applications", fin) - Logging? Built-in (
kubectl logset centralisation facilitée) - Tolérance aux pannes? Built-in: vous perdez un pod, ça redémarre. Vous perdez un noeud, ce qu’il y a dessus redémarre ailleurs.
- Gestion des mises à jour: Built-in:
kubectl drain, vous butez le noeud, terminé. Avec Karpenter, c’est encore plus simple - Scheduling? built-in, avec gestion et suivi des ressources utilisées, anti affinity/toleration dispo nativement, et avec des outils comme Karpenter votre infrastructure s’optimise toute seule (sizing des machines, scheduling intelligent…)
- Cronjobs? Built-in (
Cronjob), avec retry automatique (restart policy, backoff..), rescheduling si besoin… - Sécurité? Built-in (RBAC, gestion des capabilities, security context, configuration de scheduling spécifique pour l’isolation si besoin…)
Le tout dans un format simple et déclaratif que n’importe qui peut écrire même sans être expert Linux.
Et tout ça vient avec littéralement quelques binaires statiques à démarrer (voir un seul avec k3s), et si vous avez la flemme c’est dispo sur 100 % des cloud de la planète (donc simplifiant énormément son administration) pour entre 20 et 100 euros par mois par cluster.
Et ça c’est que les fonctionnalités de base, mais qui remplacent déjà à quasi 100 % les trucs pénibles qu’on avait à gérer avant. Tout un écosystème a été construit au dessus pour déployer toute sorte d’outils additionnels selon les besoins.
Conclusion
Kubernetes n’est pas fait que pour le scaling. Il devient pertinent dès qu’on commence à le reconstruire "à la main", et cela arrive très rapidement. Kubernetes offre sur étagère ce que vous allez passer des années à reconstruire vous même (et ce sera moins bien et avec plus de bugs).
De plus, Kubernetes est très flexible. Vous avez un legacy degueu qui supporte mal le redémarrage? Mettez le sur des noeuds fixes via de l’affinity, et vous aurez un comportement similaire à des machines virtuelles classiques, mais dans un environnement ultra standardisé.
Donc non, ce n’est pas non plus que pour des stacks ultra modernes dans le cloud: monolithes, applications stateful… c’est très bien aussi.
La techno n’est pas parfaite, ce n’est pas une solution magique, mais c’est un énorme bond en avant par rapport à l’époque dans énormément de cas.
Certes, ça demande un effort d’apprentissage, mais quid de de la courbe d’apprentissage de tous les outils/scripts qu’on maintenait aux petits oignons? Elle était supérieure à celle de Kubernetes, et l’expérience Kubernetes est transférable entre cloud et entreprises.