Un exemple d'observability trace-first
Dans cet article, je présenterai une approche moderne et "trace-first" pour de l’observability applicatif.
J’ai déjà écrit un article sur les traces en 2023 (c’est là où je me rends compte que le temps passe vite) où j’expliquais le tracing en détail et où j’abordais déjà l’idée de remplacer une majorité de logs, et pourquoi pas les métriques, par des traces. Je vous conseille de lire cet article si vous n’êtes pas familier avec le tracing distribué.
L’approche que je vais présenter dans ce nouvel article est similaire à celle que j’applique en production aujourd’hui:
-
Il y a des spans configurées un peu partout dans l’application (fonctions, middlewares…)
-
Les spans ont des attributs associés, et notamment des attributs métiers (user/organization ID, ID des entités manipulées, paramètres de fonctions quand cela a du sens)
-
J’utilise les span events pour rajouter encore plus de contexte si besoin, et j’attache toutes les erreurs de l’application à des spans également via des events
-
J’ai très peu de log dans l’application: je ne garde que certains logs métier critiques (notamment d’audit), et les logs d’erreurs
J’ai codé une application de démo en Python pour cet article, implémentant du tracing de bout en bout. Cette application:
-
Utilise SQLite pour la partie base de données, avec deux tables:
userspour les utilisateurs (id, nom, mot de passe, et balance), etproductspour des produits (id, nom, quantité, prix). -
Expose une API HTTP, avec du simple Basic Auth (
user_id:password) pour l’authentification, et un endpoint APIPOST /product/<product id>permettant à un utilisateur d’acheter un produit, ce qui va modifier la balance de l’utilisateur en fonction du prix et modifier la quantité de produit disponible.
L’application a une architecture assez classique, avec une couche HTTP (FastAPI) gérant l’authentification et le routage HTTP, une couche service implémentant la logique business (acheter un produit), et une couche repository exposant des fonctions pour interagir avec la base de données (récupérer un utilisateur, mettre à jour un produit…).
DISCLAIMER: l’application est une application de demo, il y a des bugs (notamment sur l’aspect transactionnel), pas de tests, la gestion d’erreur n’est pas clean… Son but est de fournir une base pour l’article, c’est tout.
Vous pouvez maintenant lancer git clone git@github.com:mcorbin/python-tracing-example.git et lancer docker compose up pour:
-
Build et démarrer l’application sur le port
3000 -
Démarrer
Opentelemetry Collector(un outil pour processer les spans, pas la peine de s’attarder dessus),Grafana, etClickhouse.
Clickhouse est une base de données analytics énormément utilisée dans le monde de l’observability. Ici, on va l’utiliser pour stocker nos spans, et Grafana pour la requêter.
Vous pouvez faire ouvrir dans une nouvelle tab les screenshots de cet article pour les voir en plus grand si besoin.
Interagir avec l’application
L’application est automatiquement initialisée avec quelques produits et utilisateurs au démarrage (voir ce fichier pour la liste, notamment des UUID).
Vous pouvez par exemple "acheter" un produit pour un utilisateur en utilisant cette commande curl:
curl -X POST http://localhost:8000/product/3ef49b1c-877f-4931-a2e4-daf679db4f11 \
-u "a76afb96-191a-4bcb-a438-a366f886168d:password1" \
-H "Content-Type: application/json" \
-d '{"quantity": 1}'
{"message":"success"}Vous pourrez voir dans les logs de l’application un log d’audit pour cet achat que j’ai rajouté comme exemple. On retrouve un attribut audit=true, les informations du produit et de l’utilisateur, et surtout une trace et span ID pour associer ce log à sa trace Opentelemetry:
{
"product_id": "3ef49b1c-877f-4931-a2e4-daf679db4f11",
"user_id": "a76afb96-191a-4bcb-a438-a366f886168d",
"product_quantity": 1,
"audit": "true",
"event": "product bought",
"level": "info",
"logger": "app.service",
"pid": 41,
"trace_id": "271311edf96377c5a0d0f0a388a263b8",
"span_id": "1b17ebe567895a6f",
"timestamp": "2026-01-01T22:50:43.828857Z"
}C’est le seul log info que j’ai dans cette application.
Le tracing dans cette application
Grafana est disponible sur localhost:3000, et vous pouvez vous connecter avec admin/admin.
La datasource Clickhouse est déjà configurée.
Dans la couche service de mon application, ma fonction pour acheter un produit commence comme cela:
@tracer.start_as_current_span("service_buy_product")
async def buy_product(
self, *, product_id: UUID, user_id: UUID, quantity: int
) -> None:
span = trace.get_current_span()
span.set_attribute("user.id", str(user_id))
span.set_attribute("product.id", str(product_id))
span.set_attribute("product.quantity", quantity)L’annotation sur la fonction indique le démarrage d’une nouvelle span appelée service_buy_product. J’attache ensuite à cette span des attributs représentant les paramètres passés à cette fonction via span.set_attribute.
Allez dans la section Explore, sélectionnez la datasource Clickhouse et dans SQL Editor, executez cette requête:
SELECT
Timestamp,
TraceId,
SpanName,
Duration / 1000000 as duration_ms,
SpanAttributes['user.id'] as user_id,
SpanAttributes['product.id'] as product_id,
SpanAttributes['product.quantity'] as product_quantity
FROM otel.otel_traces
WHERE $__timeFilter(Timestamp) AND SpanName='service_buy_product'
ORDER BY Timestamp DESCRappelez-vous, Clickhouse stocke les spans composant une trace. Ici, je liste toutes les spans appelées service_buy_product dans l’intervalle sélectionné dans Grafana. Le span associé à la requête curl précédente est visible.
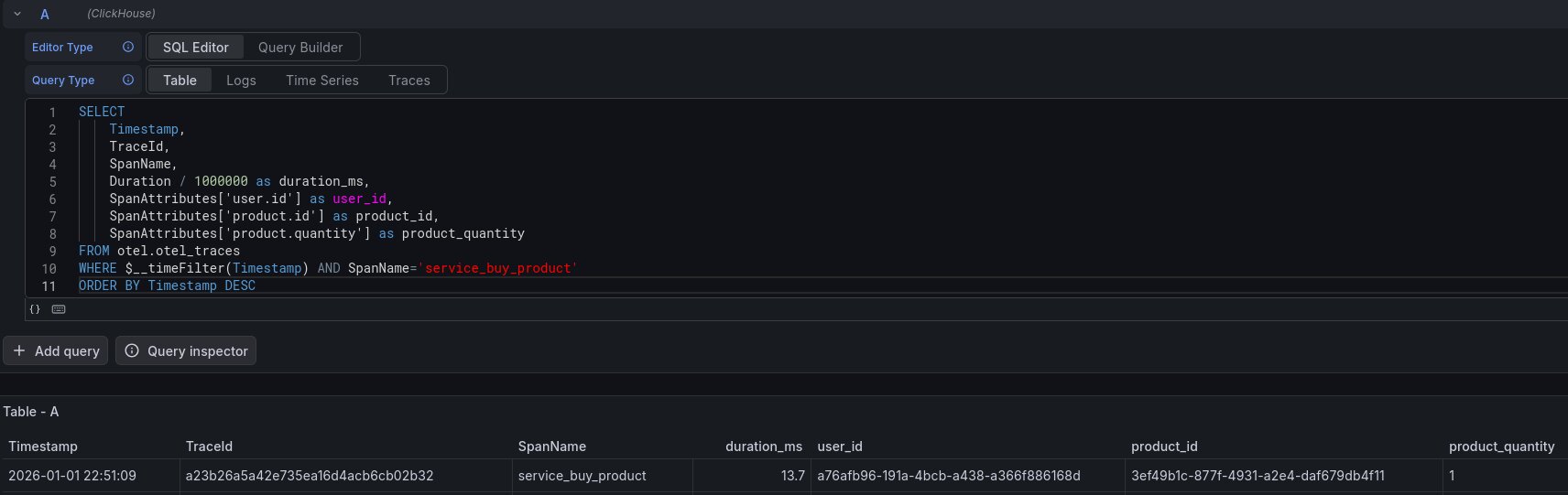
Cliquez sur l’ID dans TraceId, puis View trace pour voir la trace complète associée à cette span:
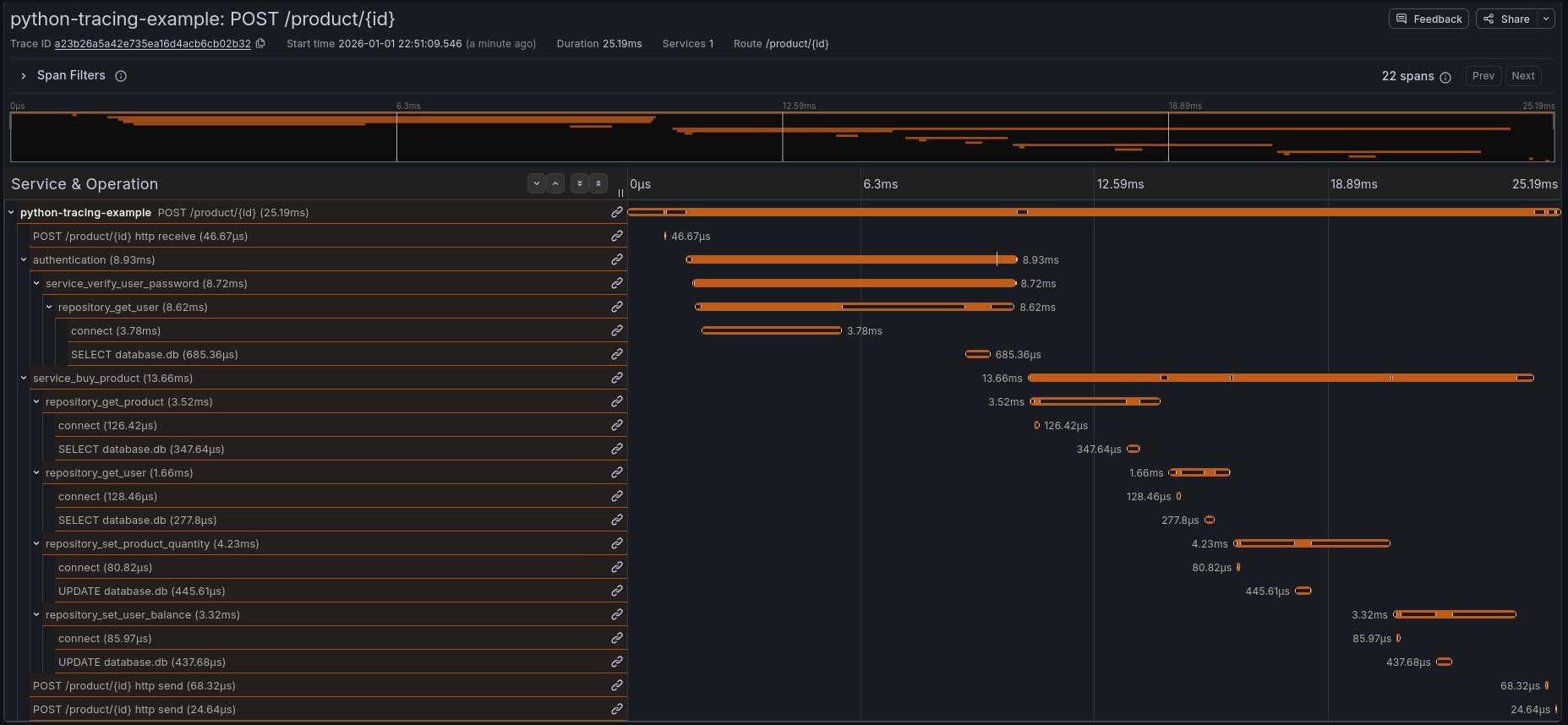
La trace de cette requête dans ce service est composée de 22 spans. On voit pour chaque span sa durée, et on comprend immédiatement comment le service fonctionne.
Commençons notre analyse:
-
Le serveur Python reçoit la requête (span
POST /product/{id}) -
L’authentification est déclenchée (span
authentication) -
La fonction d’authentification appelle la couche service (
service_verify_user_password), qui lui même appelle la partie repository de l’application (repository_get_user) -
On voit ensuite les détails sur la connexion à la base de données:
connect, puisSELECT database.db.
Il est très intéressant de regarder ensuite les attributs de chaque span, en cliquant dessus pour voir le détail.
En effet, et c’est très important quand on fait du tracing, j’ai fait l’effort ici de rajouter du contexte dès que je le pouvais, notamment en utilisant span.set_attribute ou en utilisant des librariries permettant de tracer certaines parties spécifiques de l’application (comme la partie SQL).
On voit par exemple sur la span HTTP tous les détails de la requête: route, method, status code, IP/port source…
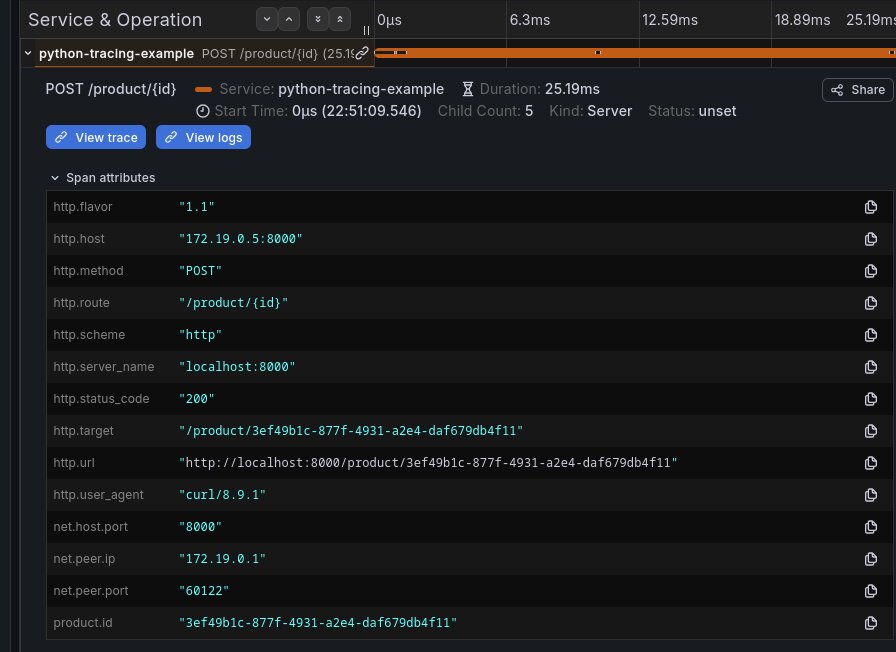
Sur ma span d’authentification, j’ai un attribut user.id avec l’ID de l’utilisateur. J’ai également un event (je parlerai plus loin des events) avec un message indiquant que l’utilisateur s’est connecté avec succès:
Voici la span exécutant la requête SQL, On voit ici le statement (la requête SQL exécutée sans ses paramètres) ainsi que des informations sur la base de données:

La trace continue. Une fois l’utilisateur connecté, on appelle notre couche service (span service_buy_product).
On voit les attributs attachés à la span, ce qui permet immédiatement de comprendre "l’utilisateur 3ef49b1c-877f-4931-a2e4-daf679db4f11 a acheté 1 produit a76afb96-191a-4bcb-a438-a366f886168d)", tout en connaissant la durée d’exécution de la fonction (13.66ms):
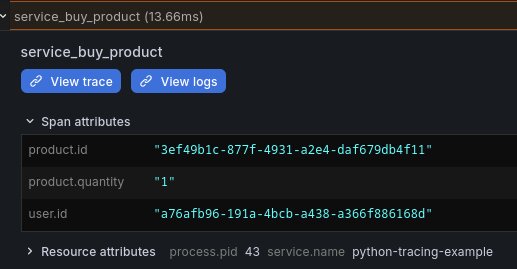
Le reste de la span décrit les appels au repository (qui lui même appelle la base de données) pour réaliser l’achat: récupérer les détails du produit et de l’utilisateur, modifie la quantité de produit en stock et la balance de l’utilisateur.
Pour chaque requête SQL, on a son détail comme précédemment.
Résumé
Cette trace permet de comprendre comment la requête a été gérée par le service de manière extrêmement précise: chaque appel de fonction est tracé et chaque span a un contexte extrêmement détaillé.
On a le temps d’exécution globale de notre requête sur notre API et le temps d’exécution détaillé pour chaque sous fonction.
Un second exemple: une erreur d’authentification:
Générons une erreur d’authentification:
curl -X POST http://localhost:8000/product/3ef49b1c-877f-4931-a2e4-daf679db4f11 \
-u "a76afb96-191a-4bcb-a438-a366f886168d:invalid_password" \
-H "Content-Type: application/json" \
-d '{"quantity": 1}'
{"detail":"Invalid credentials"}%Récupérons ensuite avec Clickhouse toutes les spans authentication en erreur:
SELECT
Timestamp,
TraceId,
SpanName,
Duration / 1000000 as duration_ms
FROM otel.otel_traces
WHERE SpanName='authentication' AND StatusCode='Error'
ORDER BY Timestamp DESCCliquez sur View trace comme précédemment. On voit ici encore le détail de l’exécution de la requête, et notamment l’erreur d’authentification:
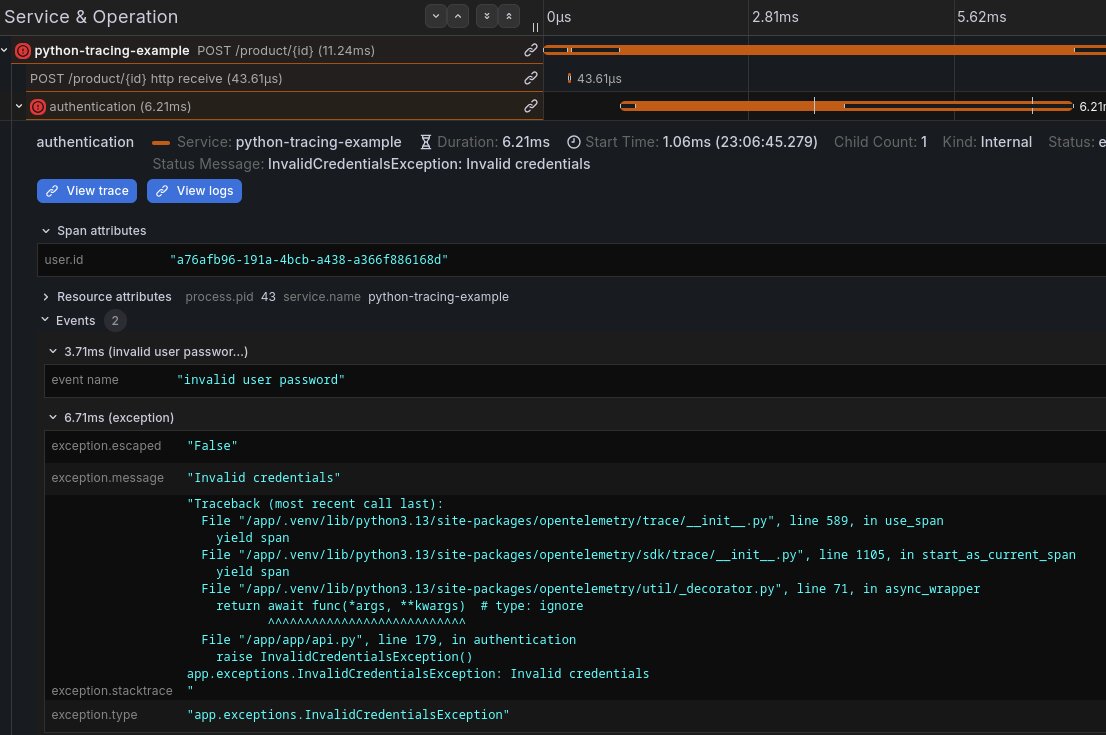
Bref, vous avez compris, Clickhouse permet de facilement récupérer des spans grâce à de multiples critères.
Vous pourriez par exemple récupérer toutes les erreurs d’authentification pour un utilisateur dédié en rajoutant par exemple AND SpanAttributes['user.id']='a76afb96-191a-4bcb-a438-a366f886168d' à votre requête.
Ou bien, filtrer par durée (AND duration_ms > 10) pour récupérer des spans lentes sur un service. Mais on peut aller beaucoup plus loin avec.
Les traces pour remplacer les logs?
J’aurais très bien pu générer un log d’erreur en cas d’échec sur l’authentification, du type {"message": "login failed", "user_id": "<uuid>"}.
Mais en fait, j’ai déjà toutes ces informations dans les traces! Et je peux déjà très facilement construire des requêtes du type "liste-moi toutes les requêtes où l’authentification a échoué", que ce soit en filtrant sur ma span authentication comme précédemment, ou en filtrant sur mes spans HTTP pour toutes celles ayant http.status_code=401.
Et mes spans sont liées à leurs trace, donc une fois la span identifiée j’ai accès à l’ensemble de ma trace, ce qui a beaucoup plus de valeur qu’un log isolé.
De plus, sur un déploiement multi-service en production, j’aurai accès sur la trace aux services en amont et en aval (dépendances) avec le même niveau de détail.
J’ai également mentionné les events attachés aux spans précédemment.
Regardez par exemple ma fonction authentication où j’ajoute parfois des events:
# Verify credentials using the service
is_valid = await service.verify_user_password(user_uuid, password)
if not is_valid:
span.add_event("invalid user password")
span.set_status(StatusCode.ERROR)
raise InvalidCredentialsException()
span.add_event("user successfully logged")Les events sont des messages arbitraires (avec optionnellement des attributs clé/valeur) que l’on peut attacher aux spans. Chaque event a un timestamp associé (le moment exact où il est ajouté, comme un log). Ces events vous permettent donc d’ajouter encore plus de contextes à vos spans, à la manière de logs, pour aider au debugging.
Les erreurs (exceptions en Python) sont également automatiquement ajoutées comme events aux spans, c’est ce que vous voyez dans le screenshot précédent de la span d’authentification en erreur. C’est également possible de le faire manuellement via par exemple span.record_exception(exc) en Python.
Les spans ont également un status (Ok, Error ou Unset qui est le défaut). Vous pouvez donc filtrer toutes les spans en erreur via StatusCode='Error' dans Clickhouse pour créer des dashboards montrant vos erreurs.
Clickhouse permet également de requêter sur le contenu des events si besoin.
On a donc les mêmes informations qu’un log, mais dans le contexte d’une trace.
Aujourd’hui, je n’utilise quasi jamais les logs pour du debugging ou pour suivre un parcours utilisateur, je trouve les traces beaucoup plus intéressantes:
-
Requêtage puissant
-
Format structuré, standardisé (voir les conventions semconv d’OpenTelemetry), et extensible avec vos propres attributs métier (via un
semconvinterne). C’est beaucoup plus simple de standardiser des traces que des logs entre services. -
Contexte complet (attributs, détail de l’ensemble du cycle de vie de la requête, events, erreurs…).
Générer des métriques depuis les traces
Générons un peu de traffic sur notre application, par exemple quelques requêtes en erreur en cas d’achats sans avoir l’argent pour:
curl -X POST http://localhost:8000/product/3ef49b1c-877f-4931-a2e4-daf679db4f11 \
-u "a76afb96-191a-4bcb-a438-a366f886168d:password1" \
-H "Content-Type: application/json" \
-d '{"quantity": 1000}'
{"detail":"Insufficient quantity for product 3ef49b1c-877f-4931-a2e4-daf679db4f11"}J’ai également fait d’autres requêtes avec d’autres produits et d’autres utilisateurs.
Métriques techniques
J’ai décidé ici de créer un dashboard Grafana, toujours en utilisant la datasource Clickhouse.
Vous pouvez vraiment faire tout ce que vous voulez avec Clickhouse en terme d’aggregation et donc d’utilisation de visualisations Grafana.
Par exemple, calculer le HTTP rate (nombre de requêtes par seconde) par status code de notre API. Vous pourriez d’ailleurs changer l’aggregation en modifiant la clause group by (par path, HTTP method…):
SELECT
$__timeInterval(Timestamp) AS time,
SpanAttributes['http.status_code'] AS status_code,
count() / $__interval_s AS rps
FROM otel_traces
WHERE $__timeFilter(Timestamp)
AND ServiceName = 'python-tracing-example'
AND SpanKind = 'Server'
GROUP BY time, status_code
ORDER BY time, status_code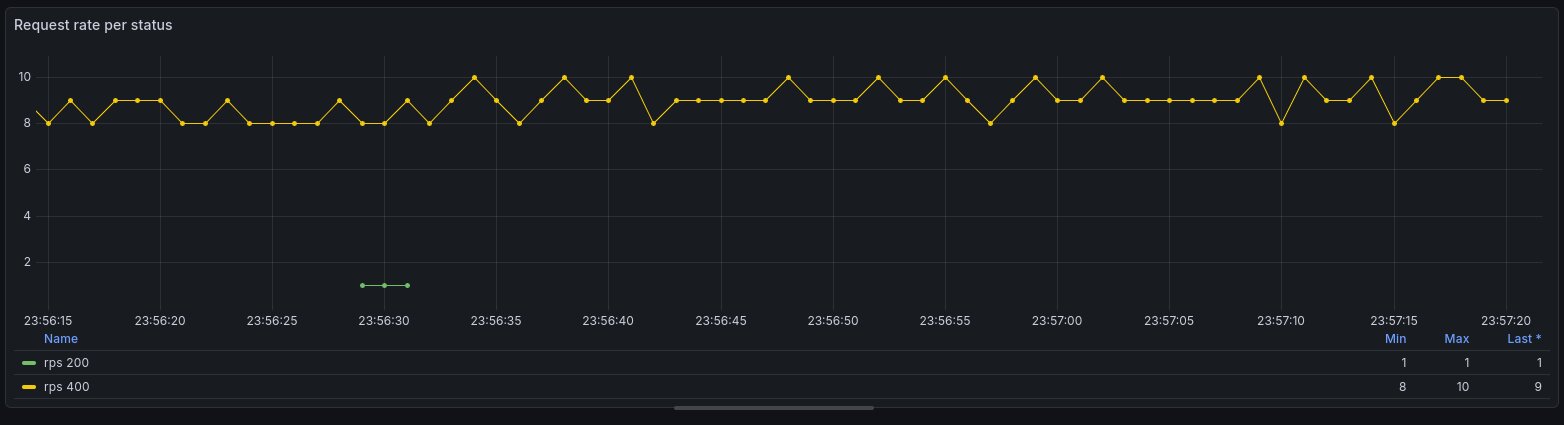
Et pourquoi pas la latence de mon application en calculant ses quantiles (p99, p95…) maintenant? Là aussi, on pourrait très bien avoir des vues globales et par route HTTP par exemple:
SELECT
$__timeInterval(Timestamp) AS time,
quantile(0.50)(Duration) / 1000000 AS p50_ms,
quantile(0.95)(Duration) / 1000000 AS p95_ms,
quantile(0.99)(Duration) / 1000000 AS p99_ms
FROM otel_traces
WHERE $__timeFilter(Timestamp)
AND ServiceName = 'python-tracing-example'
AND SpanKind = 'Server'
GROUP BY time
ORDER BY time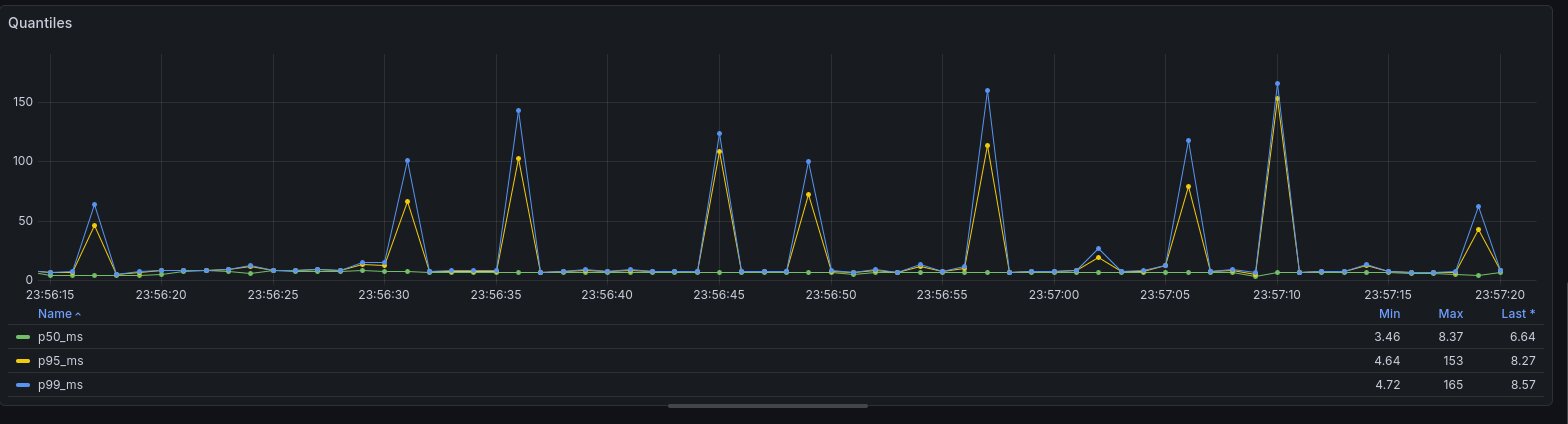
D’ailleurs, on voit des traces qui sont lentes. Rajoutons une vue pour lister toutes les traces lentes, et pouvoir immédiatement avoir le Trace ID et voir le détail de la trace!
SELECT
Timestamp,
TraceId,
SpanAttributes['http.route'] as route,
SpanAttributes['http.method'] as method,
Duration / 1000000 as duration_ms
FROM otel_traces
WHERE $__timeFilter(Timestamp)
AND ServiceName = 'python-tracing-example'
AND SpanKind = 'Server'
AND duration_ms > 100
ORDER BY Timestamp desc;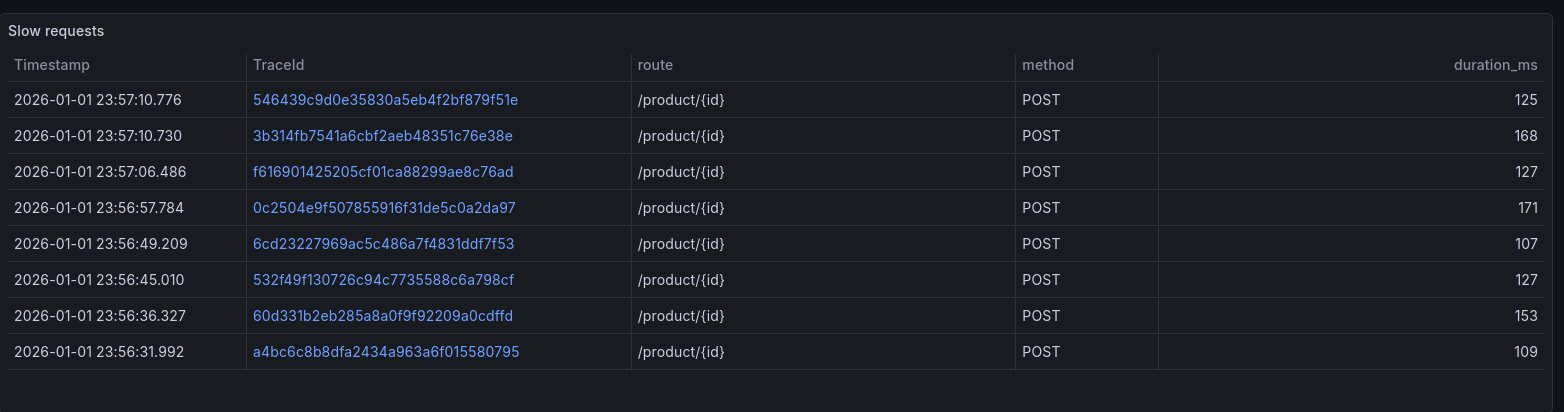
En cliquant sur une trace, je vois immédiatement que c’est ma base de données (sqlite) qui est lente pour certaines requêtes, sûrement à cause d’accès concurrents. En 2 secondes, mon investigation est terminée.
Vous avez compris l’idée: les spans sont des événements bruts qui, grâce à la puissance de Clickhouse (ou autres outils similaires), peuvent générer des métriques. Et c’est quasi sans limite grâce à la flexibilité du langage en terme d’aggregation et toutes les visualisations de Grafana sont utilisables.
De plus, sur des déploiements réels, vous avez également attachés à vos spans des attributs liés à l’infrastructure (hostname, pod name…).
Métriques métier
Mais encore mieux: vous pouvez utiliser tout ça pour générer des métriques à destination du business, notamment si, comme moi, vous attachez énormément de contextes via vos attributs de spans.
Pourquoi ne pas par exemple les 5 produits les plus vendus de la plateforme (bon, ok, j’en ai que 2 dans cet exemple mais ça marcherait pour plus)?
SELECT
SpanAttributes['product.id'] AS product_id,
count()
FROM otel_traces
WHERE $__timeFilter(Timestamp)
AND ServiceName = 'python-tracing-example'
AND SpanName = 'service_buy_product'
AND StatusCode!='Error'
GROUP BY product_id
LIMIT 5;
Ensuite, vous pourriez très bien dire "tiens, qui a acheté le produit 3ef49b1c-877f-4931-a2e4-daf679db4f11 récemment", et faire une requête listant les ID d’utilisateur ayant acheté ce produit.
Vous pourriez aussi construire des vues du type "combien de clients ont acheté 1 à 5 produits, 6 à 10, 10 à 20…)" via la visualisation Bar chart de Grafana, ou avoir des statistiques globales via la visualiation Stat, des Flame graph pour la latence… puis explorer les données au besoin via des requêtes spécifiques.
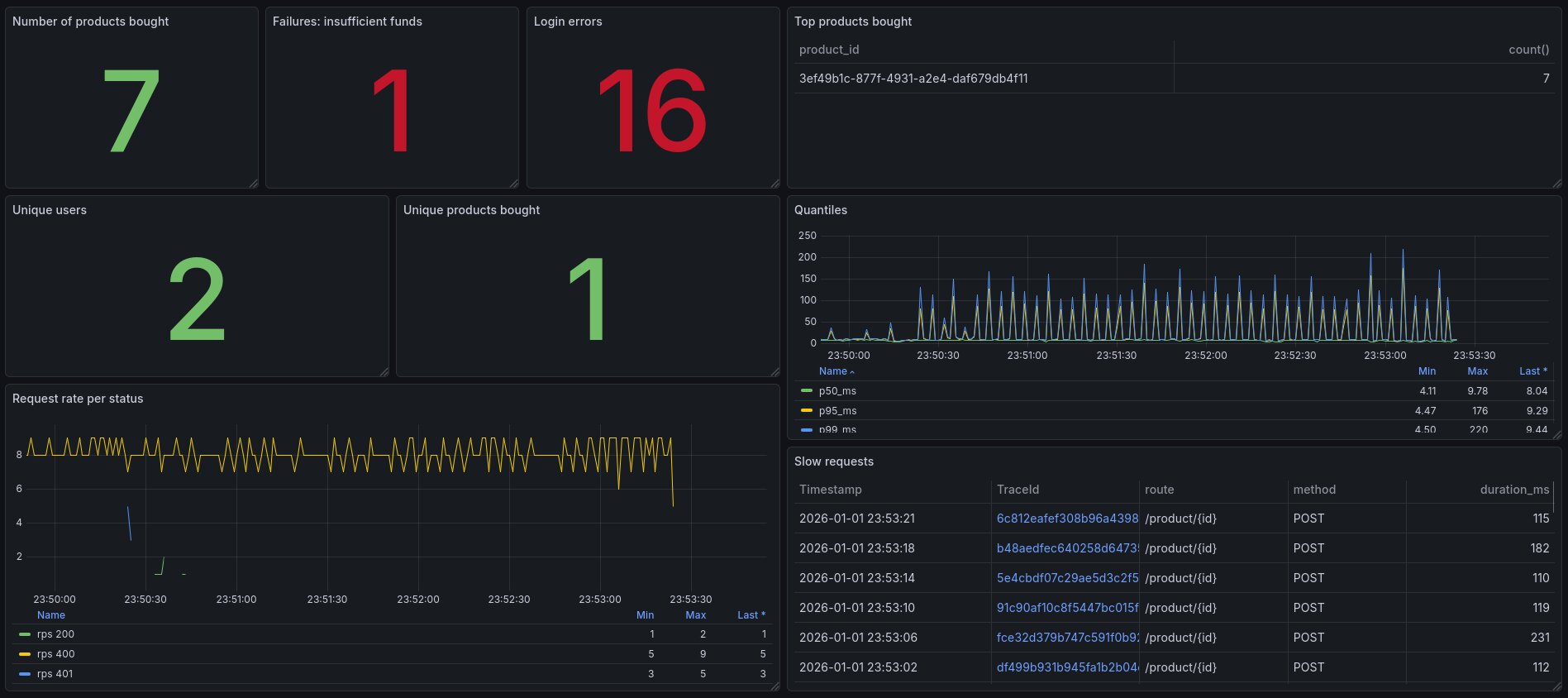
J’ai construit récemment sur un vrai projet un dashboard business 100 % à partir de spans, et c’est génial: simplicité, énorme flexibilité, possibilité d’explorer comment le service est utilisé d’un point de vue métier sous toutes formes de dimensions, corrélation avec les métriques techniques…
Je ne l’ai pas testé, mais il y aurait même un connecteur Metabase pour Clickhouse.
Des attributs système sur les spans?
Pourquoi ne pas attacher également des métriques purement techniques aux spans?
Avec des systèmes comme Prometheus, on ne récupère les métriques applicatives que de manière périodique (par exemple, toutes les 30 secondes). On manque parfois de visibilité sur ce qu’il se passe entre deux intervalles.
Utilisons les spans à la place. J’ai par exemple écrit ce middleware Python attachant les métriques du garbage collector à une span dans un middleware HTTP:
@app.middleware("http")
async def gc_stats(request: Request, call_next):
with tracer.start_as_current_span("gc_stats"):
span = trace.get_current_span()
response = await call_next(request)
stats = gc.get_stats()
span.set_attribute("python.gc.0.collections", stats[0]["collections"])
span.set_attribute("python.gc.1.collections", stats[1]["collections"])
span.set_attribute("python.gc.2.collections", stats[2]["collections"])
span.set_attribute("python.gc.0.collected", stats[0]["collected"])
span.set_attribute("python.gc.1.collected", stats[1]["collected"])
span.set_attribute("python.gc.2.collected", stats[2]["collected"])
span.set_attribute("python.gc.0.uncollectable", stats[0]["uncollectable"])
span.set_attribute("python.gc.1.uncollectable", stats[1]["uncollectable"])
span.set_attribute("python.gc.2.uncollectable", stats[2]["uncollectable"])
return responseL’appel à gc.get_stats() ne coûte rien, et grace à ça j’ai sur chaque requête HTTP les métriques actuelles (au moment de l’exécution de la requête) du garbage collector de Python.
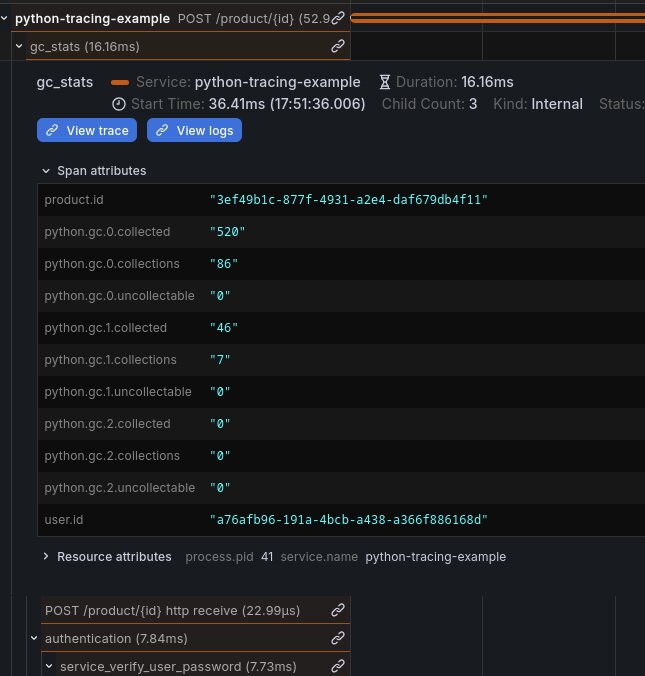
C’est d’ailleurs très intéressant car c’est courant de faire du Python avec plusieurs process (c’est comme ça que fonctionne gunicorn pour du web par exemple où chaque worker est un process dédié, et ça marche très mal voir pas du tout avec des systèmes comme Prometheus), et on a déjà le PID en span attribut.
On pourrait imaginer faire la même chose pour d’autres métriques (cpu, heap…) selon les langages.
L’unification des métriques, logs et traces
Il est donc possible depuis les spans (qui sont donc des events bruts mais pourtant énormément de contexte), de dériver des logs ET des métriques.
Il est également possible concernant la partie métrique, d’avoir des métriques métiers générées depuis les spans.
On part d’une seule source de vérité (les spans) et on dérive tout le reste. Le tout en s’appuyant sur un standard de l’industrie (Opentelemetry) pour l’implémentation côté applicatif. Tout le monde est gagnant ici.
Sampling
Bien sûr, tout ce que je décris ne fonctionne plus (ou moins bien) si on sample (= garde seulement un certain pourcentage) les traces.
Par expérience, le sampling n’est pas nécessaire dans beaucoup de cas. Je travaille sur une infrastructure avec des centaines de milliers de spans par seconde, et ça ne coûte au final pas très cher à stocker même avec 2 mois de rétention.
Clickhouse compresse très bien les données (c’est vraiment hallucinant), et le coût du stockage n’est pas très élevé. Même l’Opentelemetry Collector scale très bien avec quelques replicas.
Après, rien n’empêcherait de sampler si besoin (par exemple: garder les spans top level/business et les erreurs et sample le reste). Mais franchement, c’est de l’optimisation prématurée dans beaucoup de cas.
Et comme dit dans mon article précédent sur les traces, plus de trace veut aussi dire moins de logs, donc côté coût on s’y retrouve bien.
Une span Opentelemetry est envoyée à la fin de son exécution
Il y a quand même un point à garder en tête concernant les traces, notamment quand on les compare aux logs.
Quand vous générez un log, par exemple logger.info("hello"), il est quasi immédiatement (il y a un peu de buffering) écrit dans la sortie standard.
Pour une span Opentelemetry, c’est complètement différent: elle a une date de début, ET une date de fin: la span ne sera pas émise par l’application tant que celle ci n’est pas terminée.
Imaginons une fonction durant une minute. Si vous avez un log au début de la fonction, vous aurez immédiatement ce log visible dans la sortie standard. La span, elle, ne sera émise qu’au bout d’une minute, à la fin de la fonction.
C’est vraiment pour ça que garder les logs pour les erreurs ou l’audit, ou pour suivre l’exécution d’actions longues et complexes peut quand même avoir un intérêt. Bien sûr, les spans "enfants" (appels de sous-fonctions par exemple) seront disponibles si elles s’exécutent rapidement, mais la vue complète de la trace ne sera disponible qu’à la fin.
Gardez bien ça en tête.
Conclusion
C’est la fin de cet article. J’espère vous avoir convaincu à utiliser les traces.
TL:DR: Configurez des spans avec des attributs riches dans vos applications, et dérivez tout (logs, métriques techniques et business, dashboards…) depuis.