J’étais à O’Reilly Velocity Londres les 19 et 20 Octobre 2017, et cet article résumera ma première journée de conférence.
Je ne parlerais pas forcément de tous les talks ou keynotes que j’ai vu, mais ceux qui furent selon moi les plus intéressants.
L’organisation de la conférence
Tout d’abord, bravo aux organisateurs ! La conférence est parfaitement organisée. Elle se déroulait à l’hôtel Hilton Métropole, et on sent le professionnalisme.
Il y a de l’espace, les salles sont grandes, bien équipées, l’image et le son sont parfaits. Il y avait en tout 6 salles de conférences (donc 6 talks en parallèle), et les keynotes étaient réalisées dans une énorme salle (en fait 2 salles classiques rassemblées).
Il y avait également un grande salle contenant l’espace sponsor avec des stands. C’est aussi dans cette salle que l’on prenait le repas du midi notamment. J’ai d’ailleurs trouvé ce repas assez moyen, mais bon ce n’est pas le plus important.
Concernant les sujets des talks et keynotes, c’est technique, assez spécialisé, et pile dans mon domaine. En même temps, une conférence qui titre Build & maintain complex distributed systems, ça ne pouvait que m’intéresser :)
Keynotes
Après être arrivé assez tôt, avoir pris mon petit déjeuner (gratuit chaque matin de conférence) et participé à un speed networking (histoire de faire connaissance avec d’autres participants et de parler un peu anglais), je m’installe confortablement pour les keynotes.
Cloud native: Security threat or opportunity?
Une Keynote intéressante fut celle de Liz Rice sur la sécurité des architectures dites Cloud natives: les vm, conteneurs, orchestrateurs, et tout ce qui va avec.
Tout d’abord, Liz Rice nous explique qu’aujourd’hui, on le sait pas forcément où le code tourne. On a des centaines de VM/serveurs, certaines applications sont composées de dizaines de microservices, et les containers et orchestrateurs rajoutent une couche de complexité au dessus de tout ça.
La speaker expliquait aussi la différence entre l’ancien temps (ou le présent si vous travaillez pour un grand groupe Français ^^) où les serveurs étaient patchés (à la main ?) et maintenus en vie sur de longues périodes, là ou aujourd’hui on va plutôt essayer de mettre en place des infrastructures immuables (en gros on pète et on reconstruit).
Mais quid de la sécurité dans ces nouvelles architectures ? Vu la multiplicité des briques logicielles et la complexité des architectures, elle doit être intégrée directement dans le pipeline de déploiement.
Par exemple, on peut scanner nos containers avant et après le build pour rechercher des vulnérabilités: voir les versions des produits déployés, vérifier que l’utilisateur lançant un process n’est pas root, vérifier l’isolation du container par rapport à l’host…
Concernant l’host, des OS spécialisés pour faire tourner des containers (CoreOS, RancherOS…) peuvent également être une solution. Je n’ai personnellement pas d’avis sur ces OS, ne les ayant jamais utilisés.
Bien sûr, les IDS traditionnels peuvent toujours être utilisés si besoin.
Concernant le réseau, là aussi il faut sécuriser les communications, que ce soit au niveau chiffrement, authentification, ou restrictions (j’évite que des services qui n’ont pas à discuter entre eux puissent le faire).
Enfin, des protections "au runtime" comme SELinux ou AppArmor ont été évoquées. La présentation s’est finie sur une petite démo de la faille Shellshock où un serveur httpd pouvait exécuter du code arbitraire.
En conclusion, une keynote intéressante, mais un détail méritait d’être évoqué et ne l’a pas été selon moi. La meilleure sécurité, c’est quand même d’essayer d’avoir une architecture la plus simple et comprehensible possible avec les contraintes de scalabilité/tolérance aux pannes de notre produit. Restez simple !
Why an interactive picture is worth a thousand numbers ?
Peut être ma keynote préférée des deux jours, ça envoyait du lourd ! Sara-Jane Dunn travaille pour Microsoft Research, et nous expliquait ici l’importance des visualisations par rapport notamment à des chiffres bruts.
Aujourd’hui, on a de plus en plus de données, de logs… On calcule souvent des statistiques sur ces données, mais ces statistiques sont parfois trompeuses !
Deux jeux de données peuvent produire des statistiques (moyennes, médianes…) semblables alors que les données n’ont rien à voir.
De plus, on doit parfois partager ces données avec des collègues, pas forcément de notre domaine (par exemple avec des scientifiques en biologie alors que nous on est informaticien).
C’est là que les visualisations interviennent. Pouvoir représenter et explorer des données de façon graphique est devenu indispensable aujourd’hui.
La speaker, à l’aide de nombreux exemples, nous montrait comment des visualisations aident à résoudre des problèmes parfois très complexes. Les exemples venaient du monde de la biologie, où un chercheur a même avoué que sans l’outil de visualisation développé par la speaker, ces recherches n’auraient probablement pas abouties. Les visualisations lui avaient permis de voir son problème sous un angle totalement différent.
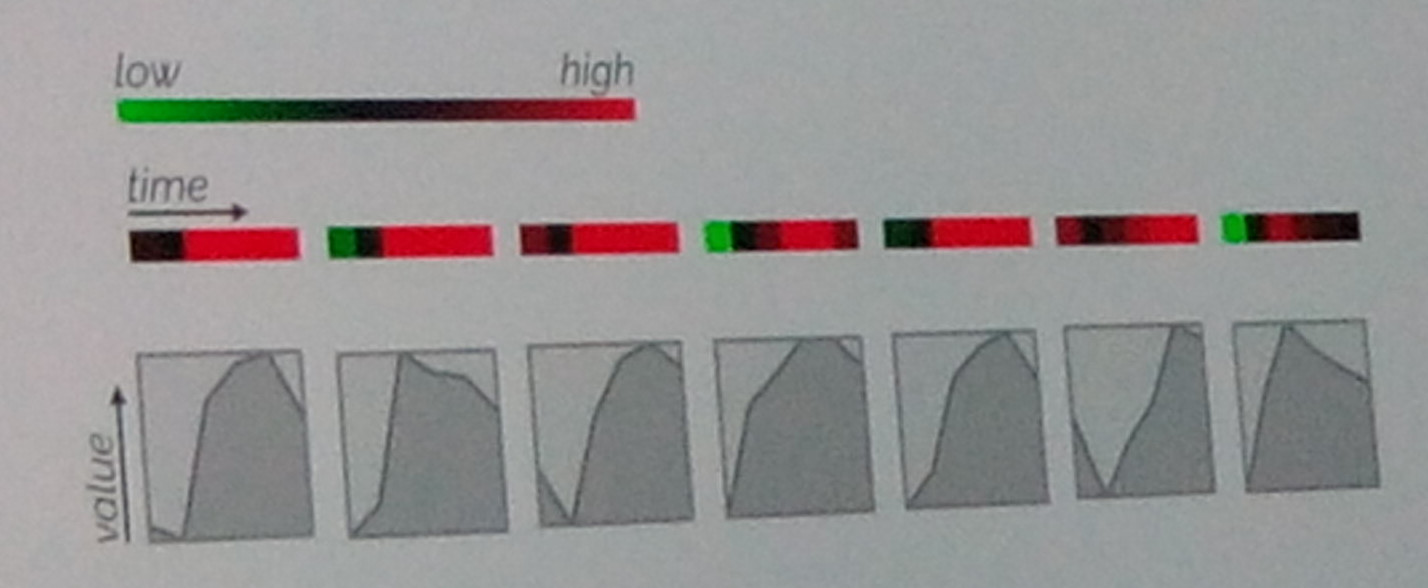
Ici, on voit clairement que la visualisation 2 (avec les courbes) est plus parlante que la première (avec les couleurs).
La speaker présentait ensuite quelques techniques pour créer des visualisations pertinentes. Cette slide montre bien par exemple qu’une visualisation à base de formes/graphes est largement plus pertinente qu’une visualisation à base de couleurs. L’intéractivité est aussi aujourd’hui la clé de visualisations pertinentes.
En conclusion, investissez du temps pour créer les outils permettant de visualiser vos données !
Talks
Consumer-driven contract testing with Pact and Docker
Ce talk, donné par Harry Winser, expliquait les stratégies et les outils et process développés pour valider des API HTTP dans une architecture microservice.
Les problèmes pour les API HTTP sont toujours les mêmes. Comment gérer la montée de version d’un service ? Comment je m’assure que les clients d’une version antérieure sont toujours compatibles avec la nouvelle version ?
Une solution peut être les consumer driven contracts. On définit un contrat d’interface pour notre API. Cela permet aux équipes de travailler de manière indépendantes, et d’écrire des tests pour valider nos contrats. Une phrase prononcée intéressante était write your consumer first.
Attention, ces contrats ne concernent que la partie API, et ne permet donc pas de vérifier la logique métier des applications.
Le speakeur utilisait dans son entreprise un format appelé Pact, Ce format permet de décrire une requête HTTP, et s’intègre facilement dans des pipelines de déploiements grâce à une intégration avec de nombreux langages/plateformes (comme par exemple la JVM).
Les contrats Pact sont stockés dans une base appelée Pact broker. Quand une application est build, son artifact (comme par exemple son .jar pour une application Java) est poussée dans un Nexus ou autre, et les contrats Pact de cette application (et pour cette version) dans le broker. Il est aussi important de stocker des stubs/mock de l’API de l’application, qui seront ensuite utilisés par la suite.
Dans l’intégration continue des consumers d’une API, on utilise les stubs de l’API générés précédemment et les fichiers Pact présent dans le broker pour vérifier que l’API correspond bien à un ou des contrats Pact et si les clients peuvent communiquer avec.
Par exemple, un client communiquant avec 3 API pourra tester si il valide le contrat Pact pour ces 3 services.
Il est aussi possible de tester différentes versions de l’API, pour voir si on garde une rétrocompatibilité en cas d’une montée de version par exemple. Ensuite, le résultat de ces tests sont publiés pour être exploités.
Ce talk était intéressant. Je n’avais jamais entendu parler de Pact, le format et l’écosystème autour semblent prometteurs.
Real-world consistency explained
Attention, on passe au meilleur talk des deux jours !
Ce talk, donné par Uwe Friedrichsen, parlait de systèmes distribués, de consensus, de niveaux d’isolations dans les base de données… Bref, d’un sujet super important mais que l’on ne croise pas souvent.
je consacrerais d’ailleurs un article sur ces sujets prochainement.
Le "passé"
Le speaker commence tout d’abord à parler du "passé" (les guillemets sont importante).
On a donc depuis longtemps des bases de données relationnelles, avec des propriétés ACID (Atomicité, Cohérence, Isolation, Durabilité), Ces base de données fonctionnent très bien, il est facile de raisonner avec (ACID apporte sur le papier des propriétés fortes intéressantes).
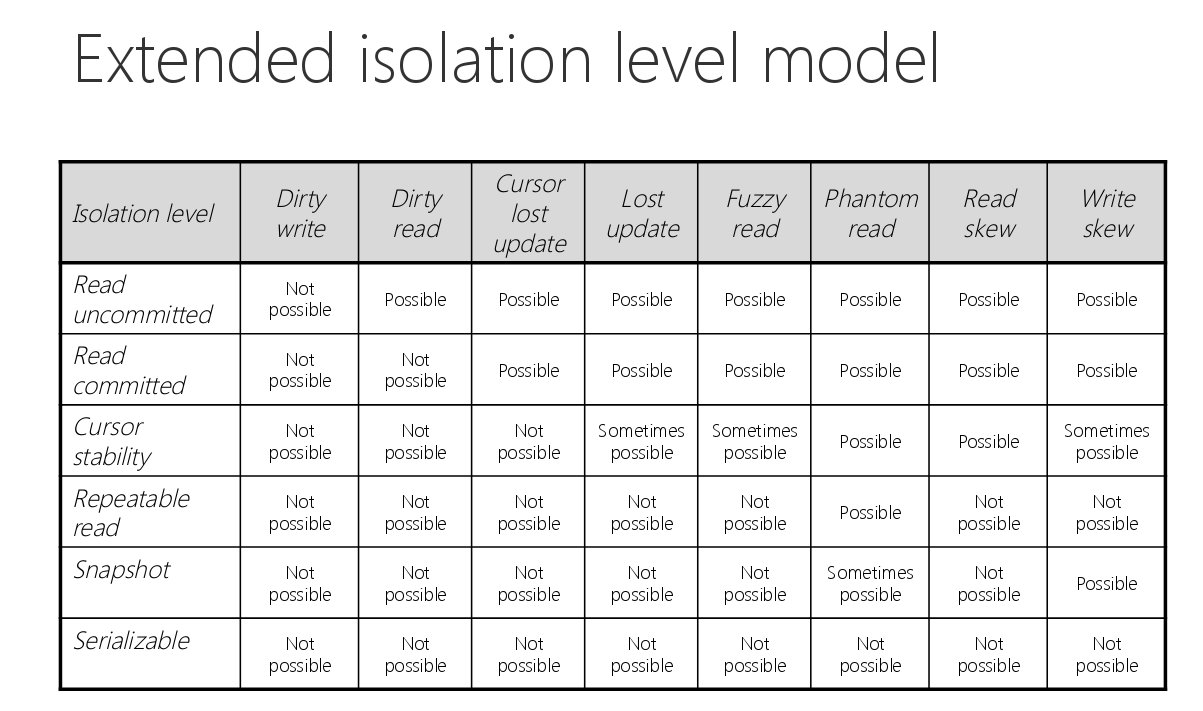
Mais (car il y a toujours un mais), ACID != Serializability (en résumé que les transactions sont exécutées sans se marcher dessus) ! Des anomalies peuvent apparaîtres, et les transactions ne sont pas si isolées qu’on ne le pense (d’où les différents niveaux d’isolations dans les bases de données: read commited, snapshot isolation, serializability…).
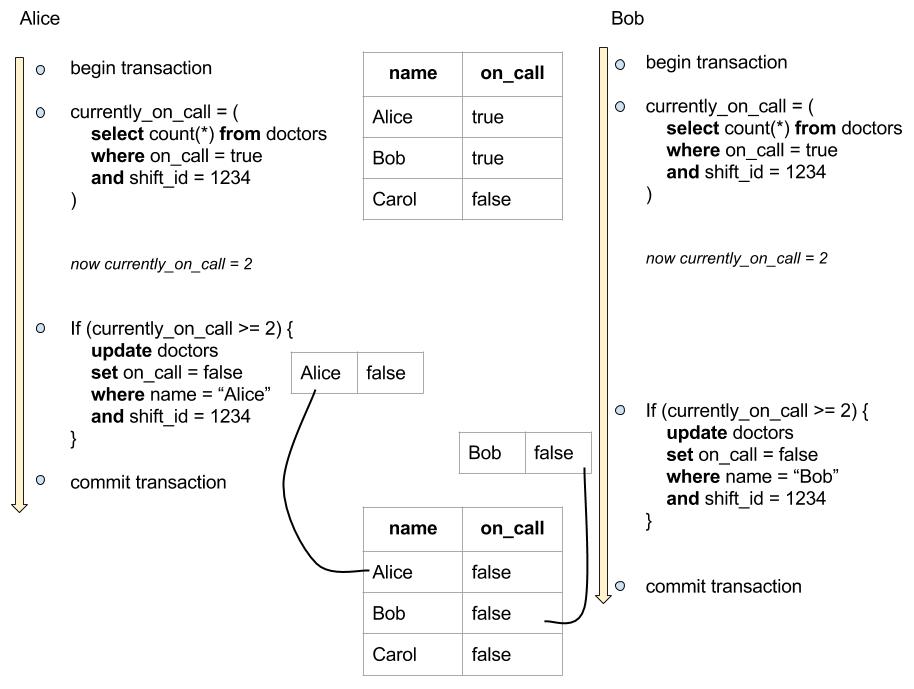
Exemple de write skew tiré de l’excellent Designing Data-Intensive Applications de Martin Kleppmann. Ici, deux transactions se chevauchent et provoquent un bug dans le système (plus aucun médecin n’est d’asteinte). Cette erreur peut se produire en snapshot isolation.
le problème du mode serializable dans une base de donnée est la grande perte de performance associée (il faut par exemple parfois locker complètement les tables pour avoir ce niveau d’isolation, ce qui diminue fortement les performances).
De plus, les configurations par défaut des bases de données n’activent pas la sérialization.
Ces configurations par défaut, couplées à une méconnaissance des différents niveaux d’isolations des bases de données, peuvent causer de sérieux soucis (et difficilement détectables) en production.
En conclusion, les bases de données ACID sont très utiles, fournissent un certain nombre de garanties, mais il faut faire attention car des problèmes de cohérences peuvent toujours se produire.
Vous croyez le monde des transactions facile ?
Le "présent"
Cloud, NoSQL, microservices… On a maintenant des architectures distribués. Et cela doit vous inquiéter ! Notamment les architectures microservices, où un mauvais découpage peut avoir des conséquences désastreuses.
Parlons maintenant un peu de NoSQL. On avait avant les propriétés ACID pour les bases de données traditionnelles, on parle parfois de BASE (Basically Available, Soft state, Eventual consistency) pour les base de données NoSQL.
Mais en dehors de l’aspect technologique, un gros problème de ces base de données est le marketing et le buzz qui font que les gens l’utilisent sans n’avoir aucune connaissance sur la technologie ou des systèmes distribués en général.
Les choix de base de données se font donc pour des raisons non techniques, ce qui conduit inévitablement à la catastrophe. Anecdote personnelle, mais j’ai déjà vu des décideurs hésiter entre entre Couchbase et Cassandra (wtf) ou entre Cassandra et Redis (wtf^10000), sans même vraiment connaître ni le besoin ni ces technos !
Un grand nombre de projets n’ont pas besoin de bases NoSQL. Le speaker donnait l’exemple de MySQL qui peut très bien traiter plusieurs milliards d’enregistrements.
Les base de données NoSQL ont des use cases, mais il est limité ! Il faut également très bien comprendre les garanties (et l’absence de garanties) qu’offrent les base de données NoSQL, notamment les garanties de cohérences des données et de disponibilité de la base.
Le speaker a ensuite présenté différents problèmes pouvant se produire dans une base de données distribuée, comme par exemple le fameux read your own write, ou alors que contrairement à une croyance populaire, définir un quorum en lecture ne veut pas dire avoir un état cohérent.
Etait également présenté quelques techniques pour gérer ces problèmes de cohérences, comme par exemple le read repair. Etait évoqué également les difficultés à travailler côté développement avec une base de données BASE, où l’absence de transactions et les joies des systèmes distribués peuvent causer des surprises.
En conclusion
Il existe aujourd’hui une multitude d’outils, ces derniers étant quelque part entre ACID et BASE niveau cohérence des données, le choix des technologies doit donc se faire de manière intelligence.
Attention au marketing et aux promesses des vendeurs qui viennent vous vendre du rêve. Attention aux base de données NoSQL et aux architectures distribuées en général, et toujours se poser la question "est ce que j’ai vraiment besoin de ça ?".
Il faut également comprendre son système, et les différents incidents qui peuvent se produire. Même les personnes d’administrant pas mais utilisant les outils doivent le comprendre, comme par exemple les développeurs. Ces derniers doivent connaître les potentiels problèmes pouvant se produire avec des bases de données NoSQL (ou même SQL avec un niveau d’isolation faible) pour pouvoir les requêter correctement.
Et surtout, surtout, pas de transactions entre différents services/outils de storage.
Encore merci au speaker pour ce talk génial, que l’on devrait diffuser à chaque personne prononçant les mots NoSQL et microservice en entreprise.
Surviving failure in RabbitMQ
Ce talk donné par Lorna Mitchell traitait des queues de messages et plus particulièrement de RabbitMQ.
La speakeur commençait par décrire l’utilité d’une queue de message: asynchronisme/communication entre applications, mise en place assez facile, nombre de workers ajustables en fonction de la charge…
Mais comme d’habitude, on peut avoir des erreurs. Un message peut ne pas être traité. Il faut donc se poser la question les garanties de traitement de notre système (at least once, at most once…).
Ces garanties de traitements nous forcent donc à réaliser du code défensif (par exemple avec une garantie at least once au niveau du broker, il est possible d’éviter de traiter deux fois le même message en faisant le travail côté application).
Il est également possible d’essayer de récupérer des erreurs en poussant un message traité comme erreur dans un exchange particulier du broker (dead letter dans RabbitMQ), pour éventuellement le traiter ultérieurement.
La speakeur insistait également sur l’obligation de monitorer les queues de messages, comme par exemple en reportant le nombre de messages dans les différentes queues, ou encore le temps de traitement des messages par les workers.
Configurer une taille de queue maximale et un TTL sur les messages pour éviter qu’une queue grandisse pour toujours peut également être intéressant. De plus, les messages rejetés peuvent éventuellement être injectés dans l’exchange dead letter et traités ensuite.
En conclusion, un talk intéressant sur les queues de messages, avec RabbitMQ comme exemple.
Traefik: Make load balancing great again
Ce talk donné par Emile Vauge nous présentait Traefik. Tout d’abord, ça fait du bien d’enfin voir un speaker Français ;)
Emile nous expliquait donc ce qu’est Traefik, que je connaissais déjà très bien pour connaître l’équipe autour et avoir déjà utilisé Traefik.

Traefik est donc un reverse proxy conçu pour les infrastructures d’aujourd’hui, c’est à dire où les serveurs et applications vont et viennent. Les solutions de load balancing traditionnelles ne sont pas vraiment prévues pour ce genre d’infrastructures (bien que beaucoup d’efforts sont actuellement fait sur des produits comme HAproxy pour que ce soit le cas).
Traefik peut donc se brancher sur un backend (un orchestrateur comme Kubernetes ou Mesos, Docker Swarm, Consul, Etcd…) et générer sa configuration à partir de celà. En cas de changement sur le backend (par exemple, un nouveau pod démarre sur votre cluster Kubernetes), Traefik mettra automatiquement à jour sa configuration.
Traefik supporte également nativement Let’s Encrypt pour générer des certificats.
Plusieurs slides étaient consacrés aux dernières releases de Traefik, et la quantité de nouveautés à chaque release est impressionnante: Custom headers, statd/datadog integration, proxy protocol, HTTP2, Websockets…
On a également eu droit à une démo où on pouvait voir la réactivité de Traefik lorsque la configuration du backend change, et des stickers ;)
Bravo à Emile et à toute la team de Containous pour le travail accompli. Je suis sûr que Traefik est un produit que l’on rencontrera de plus en plus.
Conclusion
Cette première journée s’est ensuite terminée dans un bar/restaurant privatisé pour l’occasion avec pizza/bières gratuites ;)
j’ai aussi découvert ce superbe nom de restaurant sur le chemin du retour vers mon Airbnb:

J’aimerais conclure par la chose qui m’a le plus plût durant cette conférence: les gens (speaker comme spectateurs) savaient de quoi ils parlaient et connaissaient les tradeoff des différentes technologies qu’ils ou elles utilisent.
Personne ne vendait de solutions miracles, et beaucoup de gens étaient très critiques envers le buzzword driven development. Et ça, ça fait plaisir !