Un exemple d'infrastructure: création avec Terraform
Dans la partie précédente, nous avons vu comment créer des images de machines virtuelles. Dans cet article, nous allons déployer notre infrastructure.
L’infrastructure à déployer
Voici l’infrastructure que nous allons déployer aujourd’hui:
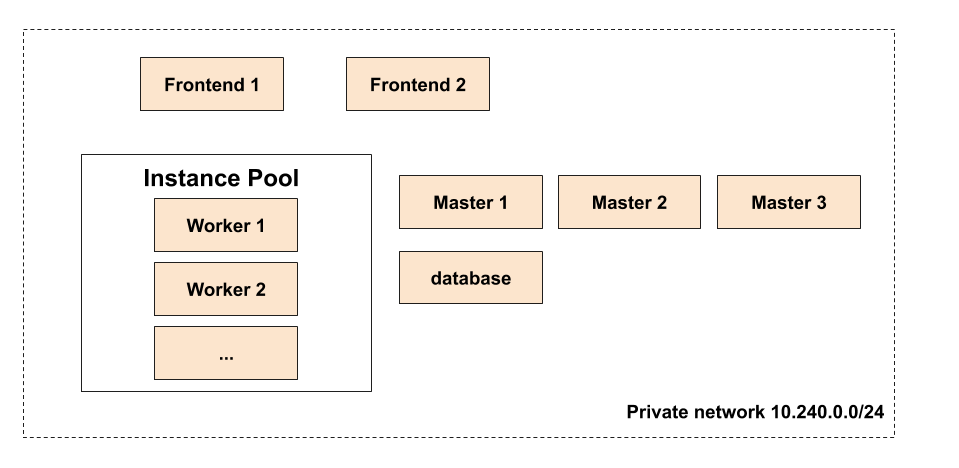
Cette infrastucture, qui est assez simple, est susceptible d’évoluer dans les articles suivants, notamment sur un article dédié au load balancing. Comme vous pouvez le voir, elle est actuellement composée de plusieurs éléments:
Les machines
-
Deux machines frontend qui seront les points d’entrées sur notre infrastructure.
-
Trois machines consul_master sur lesquelles nous déploierons, comme leurs noms l’indique, Consul dans un prochain article.
-
Un Instance Pool qui se chargera de gérer nos workers et sur lesquels nous déploierons nos applications. Comme indiqué dans la documentation d’Exoscale, un Instance Pool est un groupe de machines identiques dont la taille peut être variable (pour s’adapter aux besoins).
-
Une machine database sur laquelle nous déploierons une petite application qui simulera une base de données.
Réseau
-
Un réseau privé dans lequel sera placé toutes les machines. Un serveur DHCP (géré automatiquement par Exoscale) fournira aux interfaces privées une IP comprise dans la plage d’adresse
10.240.0.1-10.240.0.220. -
Un security group (notre firewall) qui nous permet d’accéder par SSH aux machines, et qui ouvrent les ports 80 et 443 en sortie des machines.
Une clé SSH publique sera créée et déployée sur les machines, et un fichier de configuration Cloud Init nous permettra entre autre de configurer l’interface eth1 de nos machines.
Terraform
Terraform est un outil développé par Hashicorp qui simplifie la gestion d’infrastructures. Vous définissez vos ressources (réseaux, machines virtuelles, clés ssh…) dans des fichiers d’une manière déclarative, et Terraform se chargera de les créer.
Comme toujours, avoir sa configuration dans des fichiers texte permet de la pousser sur Git et de traiter l’infrastructure comme du code (reviews de pull requests etc…).
Terraform gère l’infrastructure comme un graphe où chaque ressource peut avoir des dépendances sur d’autres. Par exemple, une machine peut avoir besoin d’une clé SSH. Cette machine peut être elle même dans un réseau privé. Terraform se chargera de créer (et détruire) les ressources dans le bon ordre.
Terraform possède même une commande (terraform graph) permerttant de générer le graphe de vos ressources au format.dot. Voici le nôtre (cliquez pour agrandir):
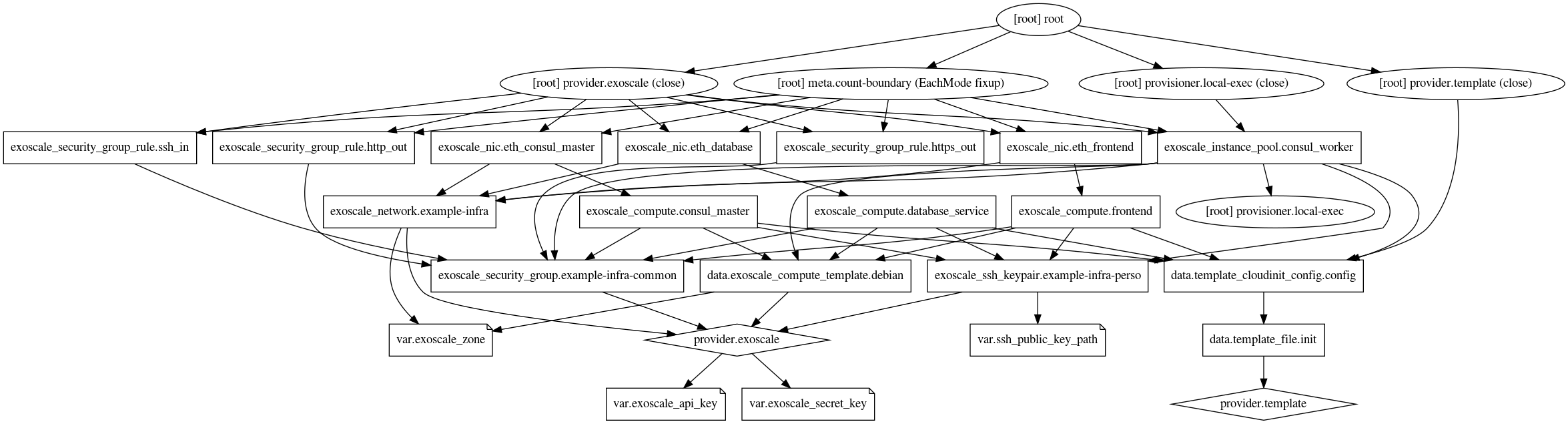
Comme tous les outils Hashicorp, Terraform est un outil très bien pensé, supporté par la plupart des Cloud du marché, et qui est devenu de facto un outil de plus en plus utilisé lorsqu’il faut gérer de l’infrastructure.
Le fichier state
Terraform maintient son état dans un fichier state. Ce fichier contient l’état de votre infrastructure vu par Terraform. Il ne faut jamais modifier ce fichier manuellement, Terraform s’en chargera lorsqu’il exécutera des actions.
Remote backend
Ce fichier peut être stocké sur votre système de fichier (par défaut), ou bien sur un remote backend. Cela est notamment utile pour plusieurs raisons:
-
Cela permet de conserver le fichier state si vous perdez votre ordinateur par exemple.
-
Il est plus simple de travailler en équipe et de partager son fichier state entre plusieurs personnes.
-
Certains backends supportent le chiffrement du fichier state. En effet, ce fichier peut contenir des informations sensibles à propos de votre infrastructure.
-
Enfin, certains backends permettent de poser un lock sur le fichier state. Cela permet d’éviter les opérations concurrentes sur l’infrastructure.
Vous pouvez retrouver dans la documentation les backends existants. Par exemple, le backend S3 est très intéressant.
Backend S3
Ce backend permet de stocker le fichier sur un stockage compatible S3. Il fonctionne par exemple sur l’Object Storage d’Exoscale qui est compatible S3.
Ce backend supporte aussi d’autres fonctionnalités seulement disponible sur Amazon, comme la gestion du chiffrement ou l’ajout du lock sur le fichier.
Pour le configurer (et aussi configurer le provider Exoscale présenté plus loin), vous devez définir quelques variables d’environnements:
export TF_VAR_exoscale_api_key=<exoscale key>
export TF_VAR_exoscale_secret_key=<exoscale secret>
export AWS_ACCESS_KEY_ID=${TF_VAR_exoscale_api_key}
export AWS_SECRET_ACCESS_KEY=${TF_VAR_exoscale_secret_key}Description de la configuration
Vous pouvez regarder les différents fichiers dont j’ai mis les liens précédemment pour voir à quoi ressemble la configuration de Terraform, mais voici quelques explications.
Variables
Il est possible de vérifier des variables dans la configuration. Par exemple:
variable "ssh_public_key_path" {
description = "Path to the ssh public key"
default = "/home/mathieu/.ssh/example-infra/id_rsa.pub"
}Ici, je déclare une variable nommée ssh_public_key_path. Cette variable a une description et une valeur par défaut.
Il est ensuite possible de surcharger cette variable lors de l’exécution de Terraform de plusieurs manières:
-
Passage d’une variable d’environnement nommée TF_VAR_<nom de la variable>, comme par exemple
TF_VAR_ssh_public_key_path. -
Passage lors de l’appel de Terraform en passant une option
-var="ssh_public_key_path=value". -
Ajout des valeurs des variables dans un fichier et passage de ce fichier lors de l’appel de Terraform de cette façon:
-var-file="file.vars.
Dans mon exemple de configuration, j’ai besoin par exemple de passer des variables pour configurer mon provider.
Configuration du provider
Il existe un grand nombre de provider Terraform. Les providers sont utilisés pour créer des ressources sur différents systèmes (Exoscale, Openstack, Cloudflare…). Voici par exemple comment configurer le provider Exoscale:
provider "exoscale" {
version = "~> 0.15"
key = var.exoscale_api_key
secret = var.exoscale_secret_key
}On voit qu’il est possible de configurer la version du provider utilisée par Terraform.
Configuration du backend S3
Voici un exemple où je configure le backend S3 pour le faire fonctionner sur Exoscale:
terraform {
backend "s3" {
bucket = "mcorbin-example-infra-tf"
key = "mcorbin-example-infra.tfstate"
region = "ch-gva-2"
endpoint = "https://sos-ch-gva-2.exo.io"
# Deactivate the AWS specific behaviours
#
# https://www.terraform.io/docs/backends/types/s3.html#skip_credentials_validation
skip_credentials_validation = true
skip_get_ec2_platforms = true
skip_requesting_account_id = true
skip_metadata_api_check = true
skip_region_validation = true
}
}On configure tout simplement le bucket où le fichier state sera stocké.
Les options skip_ sont là pour désactiver certains comportements spécifiques à S3. Il n’y a pas d’inquiétide à avoir, par exemple skip_credentials_validation ne veut pas dire que votre fichier state sera public.
Les datasources
Les datasources dans Terraform permettent de récupérer de l’information. Un exemple concret est par exemple récupérer un template de machine virtuelle selon différents critères. Ce template peut ensuite être utilisé dans les ressources décrivant les machines virtuelles par exemple.
Voici un exemple d’utilisation d’une datasource (cf le mot clé data) servant à récupérer le template que nous avons construit dans l’article précédent sur Packer:
data "exoscale_compute_template" "debian" {
zone = var.exoscale_zone
name = "Debian 10 1574286847"
filter = "mine"
}Comme nous le verrons ensuite, nous pourrons utiliser dans d’autres ressources les informations récupérées.
Cloud Init
Terraform permet bien sûr de déployer des machines virtuelles en passant un fichier Cloud Init. Cela se fait également via une datasource de manière très simple. Il est également possible de passer des variables au fichier Cloud Init chargé, qui sera donc un template (cela est utile pour avoir un fichier différent par host si besoin).
Count
Si vous voulez déployer une ressource plusieurs fois (comme par exemple déployer plusieurs machines virtuelles identiques), vous pouvez utiliser l’attribut count sur les ressources. Un exemple:
resource "exoscale_compute" "consul_master" {
count = 3
display_name = "consul-master-${count.index}"
template_id = "${data.exoscale_compute_template.debian.id}"
zone = var.exoscale_zone
size = "tiny"
disk_size = 20
key_pair = exoscale_ssh_keypair.example-infra-perso.name
security_groups = [exoscale_security_group.example-infra-common.name]
tags = {
ansible_groups = "consul-master"
}
user_data = data.template_cloudinit_config.config.rendered
}Je déploie ici 3 machines virtuelles (count = 3). A part leurs noms, ces machines seront identiques. On voit que j’utilise dans le nom de la machine (paramètre display_name) une variable ${count.index}. Mes machines seront donc nommées consul-master-0, consul-master-1 et consul-master-2.
Cet exemple montre aussi comment cette ressource de type exoscale_compute référence d’autres ressources et variables:
-
Le template est configuré en récupérant l’ID exposé par la datasource de type template présentée précédemment:
"${data.exoscale_compute_template.debian.id}" -
La zone est configurée via
var.exoscale_zone -
La keypair, le security group, et les user data (pour cloud init) sont également configurés via référencement.
Il est également possible d’itérer sur des ressources déclarées avec un count. Par exemple, je souhaite placer ces machines dans un réseau privé. Cela se fait de cette façon:
resource "exoscale_nic" "eth_consul_master" {
count = length(exoscale_compute.consul_master)
compute_id = exoscale_compute.consul_master.*.id[count.index]
network_id = exoscale_network.example-infra.id
}La variable exoscale_compute.consul_master.*.id[count.index] permettra de créer une ressource de type exoscale_nic par machine virtuelle, et donc permettra d’attacher chaque machine au réseau.
Init
La première commande Terraform à lancer est terraform init. Cette commande sert tout simplement à initialiser le backend utilisé.
Plan
Une fois que votre configuration est écrite, vous pouvez lancer terraform plan. Cette commande crée et affiche le plan d’exécution. Ce dernier permet de voir toutes les actions que réalisera Terraform: création, suppression, mise à jour de ressources. Il peut par exemple être intéressant d’attacher la sortie de terraform plan en commentaire d’une pull request lorsque l’on travaille avec Terraform.
Il est toujours important de regarder ce que va faire Terraform avant de réaliser un déploiement. En effet, il est très facile de détruire des ressources avec Terraform. Une ressource est détruite (ou reconstruite) si:
-
Elle a été supprimée du plan.
-
Un champ immuable a été mis à jour. Par exemple, si je change le template utilisé par une machine virtuelle, Packer essayera de la recréer (donc de détruire la machine existante et de la reconstruire).
-
Si la ressource dépend d’une autre ressource qui sera elle même détruite. Comme dit précédemment, si une ressource est détruite ou reconstruite, les ressources dépendantes le seront aussi.
Apply
La commande terraform apply appliquera les modifications à votre infrastructure. Terraform affichera encore une fois le plan, et demandera une confirmation.
Destroy
La commande terraform destroy vous permet de détruire votre infrastructure.
Cycle de vie
Terraform présente selon moi une difficulté majeure: la gestion du cycle de vie des ressources.
Reprenons mon exemple précédent: je veux changer le template utilisé par mes machines virtuelles. Vous voulez probablement faire ça régulièrement sur certaines machines (cf mon article précédent sur Packer où j’expose quelques raisons pour reconstruire régulièrement ses templates).
Par défaut, Terraform voudra détruire et recréer toutes mes machines. Bien sûr, ce n’est pas ce que nous voulons. Ce problème se retrouve un peu partout dans Terraform (vous modifiez une ressource et Terraform décide que cela provoquera la reconstruction de votre infrastructure).
Il est possible de contrôler le comportement de Terraform sur ce point.
depends_on
Tout d’abord, il est possible de forcer la dépendance entre deux ressources via l’option depends_on sur une ressource. Cela peut être utile parfois pour forcer une destruction qui ne se produirait pas par défaut par exemple.
lifecycle
L’option lifecycle sur une ressource permet, comme son nom l’indique, de contrôler le cycle de vie d’une ressource. Voyons quelques exemples.
ignore_changes
ignore_changes permet d’indiquer à Terraform de ne pas reconstruire une ressource si le ou les attributs spécifiés ont été mis à jour.
Par exemple, sur une ressource de type exoscale_compute, indiquer:
lifecycle {
ignore_changes = [key_pair]
}permettra d’éviter la reconstruction de la machine si la keypair référencée par la ressource est modifiée.
prevent_destroy
Cette option indiquer tout simplement à Terraform de ne jamais détruire la ressource. Par exemple, si j’indique prevent_destroy = true pour une ressource de type exoscale_compute et que j’essaye de détruire cette resource, j’obtiendrais:
Error: Instance cannot be destroyed
on master.tf line 2:
2: resource "exoscale_compute" "consul_master" {
Resource exoscale_compute.consul_master[1] has lifecycle.prevent_destroy set,
but the plan calls for this resource to be destroyed. To avoid this error and
continue with the plan, either disable lifecycle.prevent_destroy or reduce the
scope of the plan using the -target flag.create_before_destroy
Une fois ajoutée sur une ressource, cette option permet de recréer une ressource avant sa destuction.
Prenons par exemple le cas d’une ressource de type exoscale_compute. Si on modifie le template de la ressource, Terraform voudra par défaut détruire puis reconstruire la ressource.
Grâce à l’option create_before_destroy = true, la nouvelle machine sera créée avant la destruction de l’ancienne machine.
Provisioners
Les provisioners permettent tout simplement d’exécuter une action après la création d’une ressource, comme par exemple exécuter un script ou bien déployer un fichier sur une instance nouvellement créée.
Cela permet par exemple d’attendre qu’un service soit démarré avant de considérer une machine comme créée par Terraform.
Par exemple, si j’ajoute sur une ressource de type exoscale_compute:
provisioner "local-exec" {
command = "echo 'create' && sleep 10"
}
provisioner "local-exec" {
when = "destroy"
command = "echo 'destroy' && sleep 20"
}Le premier provisioner sera appelé lors de la création (ou recréation) d’une ressource, et le second lors d’une destruction. Dans mon exemple de configuration, j’utilise par exemple un provisioner de type local-exec pour ajouter des tags sur les machines virtuelles de mon instance pool.
Comme indiqué dans la documentation de Terraform, il ne faut pas abuser des provisioners. De plus, certains problèmes existent avec les provisioners. Par exemple, si j’ajoute sur une ressource:
lifecycle {
create_before_destroy = true
}
provisioner "local-exec" {
command = "echo 'create' && sleep 10"
}
provisioner "local-exec" {
when = "destroy"
command = "echo 'destroy' && sleep 20"
}Bizarrement, le provisioner destroy ne sera pas appelé (cf cette issue sur Github).
Terraform vs gestionnaire de configuration
Terraform est très bon pour créer de l’infrastructure, mais selon moi pas pour configurer des serveurs ou faire de l’orchestration (même si cela peut être possible via les provisioners).
Je pense qu’il est important de ne pas essayer d’utiliser un seul outil pour tout faire. Il vaut mieux restreindre Terraform à faire ce qu’il fait bien, et utiliser par exemple Ansible pour la configuration, le déploiement d’applications, l’orchestration… Nous verrons ça dans les articles suivants.
De même, je préfère éviter de créer de l’infrastucture avec Ansible (la capacité de Terraform à gérer les dépendances entre ressources étant un gros plus).
Pour aller plus loin
Je n’ai pas parlé de tout ce qui est possible de faire avec Terraform. Par exemple, les modules permettent de créer des morceaux de configurations réutilisables. Cela est très utile pour éviter d’avoir à se répéter, par exemple pour la création de machines virtuelles partageant certaines choses en commun.
Terraform ne se limite pas à la création d’infrastructure. Il permet de configurer des applications comme RabbitMQ, PostgresSQL, MySQL… Vous pouvez jeter un coup d’oeil à la liste des providers disponibles. A vous de trancher ce qui doit être géré par Terraform ou par un autre outil.
Il n’est pas toujours évident de mettre à jours des ressources nécessitant une destruction avec Terraform (surtout si ces ressources sont référencées par d’autres ressources). Utiliser les provisioners comme par exemple dans cet article d’Hashicorp peut fonctionner, mais il est selon moi plus simple (et plus sûr) de dupliquer l’infrastructure dans ce cas (et donc faire du déploiement blue/green).
Terraform est aussi un outil dangereux: un mauvais terraform destroy peut détruire toute votre infrastructure. Faites toujours très attention à ce que vous faites, et n’hésitez pas à utiliser prevent_destroy sur vos ressources.
N’hésitez pas non plus à découper votre déploiement en plusieurs projets Terraform (par environnement, client, provider etc…), ce sera comme cela plus simple à gérer.
C’est tout pour cet article, dans l’article suivant on parlera de déploiement et d’Ansible.