Je souhaite depuis longtemps intéger un système de commentaire à ce blog. Après avoir regardé un peu ce qui était disponible côté Open Source pour réaliser cela, j’ai décidé d’écrire mon propre outil: Commentator.
Pourquoi écrire un nouveau outil ?
Je voulais un outil répondant à plusieurs critères:
- Facile à déployer (pas de bases de données compliquées à déployer) et à administrer (en ligne de commande si possible).
- Avec un système de "challenges" pour éviter au maximum le spam.
- Avec un système de rate-limit basique, là aussi pour éviter le spam.
Isso avait l’air intéressant, mais finalement j’ai décidé d’écrire mon propre outil.
Les raisons ? Déjà, le fun. J’aime écrire mes propres outils pour mes propres besoins. Ensuite, car il est plus facile pour moi d’implémenter ce que je veux exactement de cette façon, en travaillant sur la stack technique de mon choix.
Et c’est comme cela que Commentator est né.
J’ai commencé à travailler dessus Samedi dernier, donc on est ici sur une version alpha, avec certaines parties du code à revoir (j’ai écris le projet d’une traite).
Il reste pas mal de choses que je souhaiterai améliorer, mais les principales fonctionnalités sont là, et j’ai mis le projet "en prod" pour ce blog.
Le code est comme d’habitude trouvable sur Github.
Ca marche comment ?
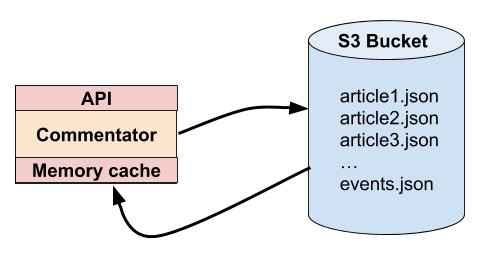
Commentator stocke les commentaires de vos article sur n’importe quel stockage compatible S3. Vous pouvez donc l’utiliser chez à peu près tous les Cloud Providers.
A part ça, Commentator est stateless, il est donc possible de l’héberger sur un provider ne supportant pas S3 tout en ayant un bucket S3 configuré chez un autre provider.
Commentator sauvegarde donc dans un bucket les commentaires pour chaque article. Chaque article dispose d’un fichier json contenant ses commentaires dans le bucket:
mon-bucket/article1.json
mon-bucket/article2.json
mon-bucket/article3.json
Les commentaires sont tout simplement stockés au format JSON. Voici par exemple le contenu (indenté correctement) possible d’un fichier de commentaire:
[
{
"content": "line1\nline2\nline3",
"author": "mcorbin",
"id": "06246983-acc9-4aaf-8ae3-9788bd708451",
"approved": false,
"timestamp": 1604940397620
},
{
"content": "line1\nline2\nline3\naaaaaa",
"author": "mcorbin",
"id": "9157ce3b-945f-4e35-ad9a-472f22b54c05",
"approved": true,
"timestamp": 1604940432062
}
]
J’ai ici deux commentaires. Chaque commentaire possède un champ "content" contenant le contenu du commentaire, un champ "author" contenant l’auteur du commentaire, un ID, un champ "approved" indiquant si le commentaire a été approuvé ou non par l’administrateur et un timestamp (seuls les commentaires approuvés sont affichés).
Commentator cache également en mémoire les commentaires des articles.
Quand un article est consulté, tous ses commentaires sont mis dans un cache pour une durée arbitraire (6 heures actuellement, mais je pense mettre plus), et ce cache n’est invalidé que si un commentaire de cet article est supprimé, mis à jour, ou un nouveau commentaire créé.
Cela permet d’éviter les allers-retours entre l’application et le store S3 à chaque consultation (les lectures étant bien plus fréquentes que l’ajout de commentaires), et donc d’améliorer grandement les performances tout en vous faisant économiser de l’argent (très peu de trafic sortant du store S3 vu que tout est en mémoire).
Quand un nouveau commentaire est ajouté, vous voulez être notifié pour pouvoir l’approuver.
Un fichier nommé events.json est gêré par Commentator dans le bucket. Lorsqu’un commentaire est créé, un nouveau événement est publié dans ce bucket. Voici à quoi ressemble un événement:
{
"timestamp": 1604943888444,
"id": "f5af61f2-2675-45f6-827b-4ea9f8470cca",
"article": "foo",
"message": "New comment 4e21a377-00a1-47f0-b5a1-b57b1262921a on article foo",
"comment-id": "4e21a377-00a1-47f0-b5a1-b57b1262921a",
"type": "new-comment"
}
Commentator dispose d’une API pour créer, récupérer et gérer les commentaires, les événements et les challenges. Mais parlons avant de présenter l’API du choix de S3, d’antispam et de challenges.
Le choix de S3
S3 est devenu de facto un standard. Disponible partout, avec des librairies disponibles dans tousles langages pour intéragir avec, son utilisation est je pense un atout pour le projet.
Rappelez vous: les commentaires et événements sont juste des fichiers JSON stockés sur S3. Enrichir le projet, écrire du tooling (pour consommer les événements et envoyer des emails par exemple) peut se faire super facilement.
J’aime cette approche où n’importe qui, depuis n’importe quel langage, peut écrire ses scripts pour intéragir avec les fichiers présents sur S3.
Cela permet également de n’avoir aucun état local (comme une base SQLite) dans le projet.
J’utilise l’object store compatible S3 d’Exoscale (mon employeur).
Il est de plus possible de créer chez Exoscale des clés API restreintes à un seul bucket, et autorisant seulement quelques appels (comme ajouter ou supprimer un objet). Cela me permet de ne pas avoir des clés API pouvant faire n’importe quoi qui trainent sur les serveurs.
A 0.01800 €/mois le GB de données stockées (chez Exoscale), c’est aussi très économique. Si on considère qu’un commentaire fait 4KB (ce qui est déjà pas mal), on se rend compte que notre facture sera à peine quelques centimes pour un très grand nombre de commentaires.
Antispam
Commentator intègre du rate limiting basique par IP (ou en vérifiant le header x-forwarded-for). Un utilisateur ne peut poster un commentaire qu’une fois toutes les 10 minutes.
Pour créer un commentaire, un utilisateur doit également résoudre un challenge (répondre à une question). Les challenges se définissent dans le fichier de configuration du projet. Par exemple (au format EDN):
:challenges {:c1 {:question "1 + 4 = ?"
:answer "5"}
:c2 {:question "Les ? de l'archiduchesse sont-elles sèches? Archi-sèches ?"
:answer "chaussettes"}}
On a ici deux challenges. Chaque challenge a un nom (qui est le nom de sa clé, comme c1 ou c2 ici), une question et une réponse.
Le format des questions et des réponses est libre, donc n’importe qui peut écrire ses propres challenges (à notez que la vérification des réponses n’est pas sensible à la casse).
Il est également facile comme cela d’écrire des scripts pour générer des milliers de challenges, et de faire de la rotation de challenges très rapidement.
Quand un utilisateur crée un commentaire, un nom de challenge et la réponse donnée par l’utilisateur sont également envoyés au serveur. Le commentaire n’est accepté par le système que si la réponse correspond à celle configurée pour ce challenge.
Actuellement, il est toujours facile pour un utilisateur connaissant un nom de challenge et la réponse associée d’écrire un script pour envoyer un commentaire toutes les 10 minutes (pour éviter le rate limiter), mais je prévois de régler ce soucis en faisant des rotations de challenges dans le futur (un challenge déjà utilisé serait inutilisable pour une longue période).
Une autre solution serait de générer dynamiquement des challenges côté backend, et donc de pouvoir avoir des challenges à usage unique.
C’est pas comme si on avait 10000 commentaires/secondes sur nos blogs, donc avec un peu de travail une solution pour éviter que quelqu’un maintienne une liste des challenges et de leurs réponses doit pouvoir se faire assez facilement (si vous avez des idées, j’attends vos suggestions).
API
L’API se décompose en deux parties: une API publique et une API admin. L’API consomme et renvoie du JSON.
Je ferai prochainement une documentation complète pour l’API, mais voici un résumé rapide.
Publique
POST /api/v1/comment/<article>: Ajoute un commentaire pour un article. Les champs attendus sontauthor,content,challengeetanswer.GET /api/v1/comment/<article>: Retourne les commentaires pour un article.GET /api/v1/challenge: Retourne un challenge choisi aléatoirement.
Admin
L’API admin est utilisable en passant un token (défini dans la configuration du projet) dans le header Authorization.
GET /api/admin/event/: Retourne les événements.GET /api/admin/event/<event-id>: Supprime un événement par ID.GET /api/admin/comment/<article>: Liste tous les commentaires pour un article, approuvés ou non.POST /api/admin/comment/<article>/<comment-id>: Approuve un commentaire pour un article.GET /api/admin/comment/<article>/<comment-id>: Récupère un commentaire pour un article.DELETE /api/admin/comment/<article>/<comment-id>: Supprime un commentaire pour un article.DELETE /api/admin/comment/<article>: Supprime tous les commentaires pour un article
Configuration
Le projet se configure via un fichier de configuration EDN (qui est en gros ce qu’aurait dû être json). Par exemple:
{:http {:host "127.0.0.1"
:port 8787}
:admin {:token #secret "my-super-token"}
:store {:access-key #secret #env ACCESS_KEY
:secret-key #secret #env SECRET_KEY
:endpoint "https://sos-ch-gva-2.exo.io"
:bucket "mcorbin.fr.test.comment"}
:comment {:auto-approve false
:allowed-articles ["foo"
"bar"]}
:logging {:level "info"
:console true
:overrides {:org.eclipse.jetty "info"
:org.apache.http "error"}}
:challenges {:c1 {:question "1 + 4 = ?"
:answer "5"}
:c2 {:question "1 + 9 = ?"
:answer "10"}}}
On retrouve une section :http pour la configuration du serveur, :admin pour le token admin, :store pour la configuration du store S3.
On remarque l’utilisation de readers EDN. J’utilise ici #env pour lire la valeur depuis une variable d’environnement. J’ai rendu le reader #secret obligatoire pour les valeurs sensibles, cela me permet (en utilisant la librarie exoscale/cloak) de manipuler dans le programme des secrets sans les log/print/sérialiser par erreur.
La section :comment contient une clé :auto-approve pouvant être passée à true pour ne pas avoir à approuver les commentaires. La liste allowed-articles définit une liste d’articles autorisés à recevoir des commentaires. Je génère cette ligne via un script pour un blog, et cela permet de désactiver les commentaires si besoin.
La partie :logging contient la configuration du logger (basé sur unilog).
Et enfin, :challenges contient mes challenges (j’ai généré pour mon blog 250 challenges via un script).
La suite
Comme dit précédemment, le projet n’est qu’à ses débuts. Il peut y avoir des bugs.
La première chose que je ferai au cours du prochain mois est de nettoyer la codebase, ajouter plus de tests, écrire la documentation… Bref, rendre le projet présentable.
Ensuite, un peu d’outillage pour la gestion des événements, la relecture et la validation des commentaires ne ferait pas de mal (rien qu’un script shell basé sur curl et jq serait intéressant au début).
Je suis également un horrible développeur frontend. Si un dev frontend a un peu de temps, je serai preneur d’une Pull Request pour ajouter un block HTML et les scripts/css associés (si possible sans aucune dépendance externe) pour intégrer proprement Commentator dans un site web.
J’ai bien fait un truc aujourd’hui mais c’est du code bien dégueulasse, donc si ça vous dit j’attends vos contributions dans le dossier integration de dépôt Git.
J’attends vos commentaires en bas de page !