J’ai récemment eu l’occasion de parler (rapidement) lors d’une table ronde de mon métier. J’avais préparé pour cette occasion des réponses à un certain nombre de questions, et je me dis qu’en faire un article peut être intéressant.
Pourquoi cet article
Je me suis rendu compte que l’on parle beaucoup du Cloud mais très peu de comment le Cloud est implémenté, et du travail de développeur chez un Cloud Provider.
Au cours de discussions où je parlais du Cloud avec des gens, j’ai souvent eu des retours me disant des choses comme "je me suis jamais demandé comment cela fonctionnait" ou bien "je ne pensais pas du tout à tous ses aspects en tant qu’utilisateur".
Pourtant, c’est un domaine très intéressant (bien qu’assez spécifique) où l’on ne s’ennuie jamais. J’entends souvent dire "Le Cloud c’est de la magie", vraiment ?
Bref, c’est quoi mon job ?
Le Cloud
Vous êtes peut être utilisateur de services Cloud pour déployer vos applications.
Vous cliquez sur un bouton, un groupe de machines se déploie, vous cliquez sur un autre bouton et un load balancer est installé devant ces machines, répartissant le trafic sur vos applications et exécutant des healthchecks.
Vous faites un appel API (utilisant une CLI par exemple), de nouvelles machines se déploient, le load balancer est automatiquement mis à jour. Un autre appel, et c’est un cluster Kubernetes qui se déploie…
Derrière tous ces services, il y a (entre autre) des programmes. Ces programmes, il faut les développer. C’est le travail d’un développeur ou d’une développeuse Cloud.
Développer sa stack Cloud
A Exoscale, nous développons notre propre solution Cloud. On ne se contente pas d’utiliser des solutions toutes faites, mais développons nos propres solutions, nos propres orchestrateurs, et c’est je pense un point très important.
On m’a parfois demandé "mais ça apporte quoi d’avoir sa propre solution et pas une solution toute faite" ? Cela a selon moi plusieurs avantages.
Déjà, pouvoir faire ses propres choix technologiques. A Exoscale, la majorité des programmes sont écrits en Clojure (même si l’on a quand même un peu de Java, Go, C, Python… car finalement chaque langage a son utilisation) et je pense que le choix de Clojure est en partie responsable de notre capacité actuelle à sortir rapidement (et maintenir et faire évoluer) des services fiables, le tout par de petite équipes (vous seriez je pense surpris de combien de personnes maintiennent les différents projets).
Mais cela sera sûrement le sujet d’un article dédié.
Ensuite, même quand vous utilisez des solutions Cloud toutes faites, vous allez devoir les maîtriser sur le bout des doigts, les forker, contribuer, parfois dériver de l’implémentation originale car cette dernière ne correspond pas ou plus à vos besoins (peut être que les mainteneurs originaux ne sont pas intéressés par vos changements car trop spécifiques ?)…
Bref, au final vous vous retrouvez également avec votre propre solution Cloud qui est un fork de l’originale (bonne chance pour les rebase), avec des centaines de milliers ou millions de lignes de codes à maintenir.
De plus, les solutions toutes faites sont conçues pour tourner de plein de façons différentes, sur plein de hardware différents, alors que vous, vous savez généralement ce que vous voulez. Bref, vous avez un paquet de code mort que vous devez quand même maintenir.
Parlons égalemement du tooling. Si vous utilisez une solution Cloud générique, et que vous proposez ensuite un produit seulement disponible chez vous, est ce que les mainteneurs de la solution générique approuveront l’ajout de votre solution spécifique dans leurs outils (Terraform, CLI…) ? Probablement que non.
Avoir sa propre solution permet de travailler rapidement, d’innover, et de sortir des produits Cloud fonctionnant avec des programmes simples et performants, sur une stack qu’on maitrise de A à Z.
Mais revenons au métier de développeur Cloud.
La difficulté du Cloud
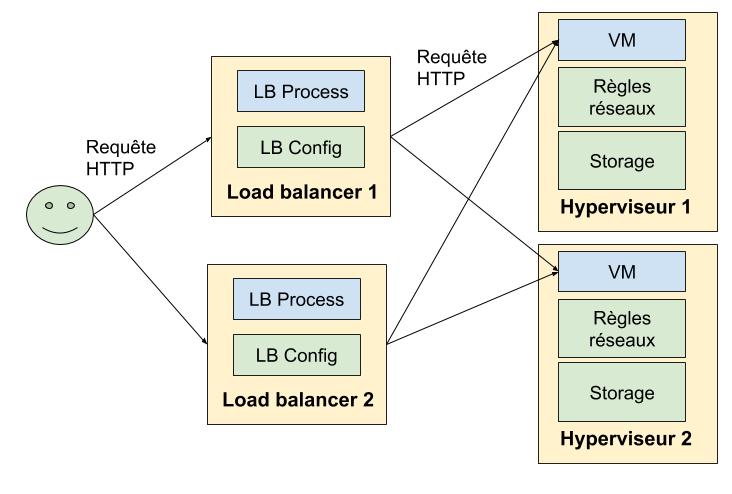
Un Cloud peut être vu qu’une certaine façon comme un système distribué. Prenons un exemple d’infrastructure toute simple: un groupe de machines virtuelles dans un réseau privé et avec un load balancer en front.
On a déjà ici différents composants; des machines, un réseaux privé, un load balancer. Chacun de ces composants est "déployé" quelque part:
- Les machines tournent sur des hyperviseurs. Le disque de la machine (en cas de stockage local) est également présent sur l’hyperviseur.
- Des règles réseaux (que ce soit pour les interfaces publiques ou privées) doivent être installées sur les hyperviseurs (comme vous vous en doutez il faut router les paquets là où il faut).
- Des machines hébergent le composant faisant le load balancing (à Exoscale, quand vous créez un load balancer vous avez d’ailleurs deux instances en actif/actif de déployée). Ce composant est configuré en fonction des machines du groupe de machine.
- Des règles réseaux doivent être ajoutées sur l’hyperviseur pour chaque machine derrière le load balancer (dans notre cas, pour faire de la décapsulation IPIP et du Direct Server Return notamment, si le sujet vous intéresse j’ai un talk de prêt sur le fonctionnement interne de notre load balancer, peut être que je le ferai au format vidéo à l’occasion).
J’oublie sûrement des trucs mais vous avez je pense saisi le problème: plusieurs composants distribués à différents endroits.
Une vue utilisateur ultra simplifiée serait:
De plus, par sa nature l’état d’une plateforme Cloud change constamment, par exemple lors d’actions utilisateurs:
- Un utilisateur ajoute une machine au groupe de machines, elle doit être automatiquement ajoutée au réseau privé et au load balancer. Et l’inverse pour sa suppression.
- Vous changez les règles de load balancing (par exemple, vous modifiez le healthcheck, le port de destination…) la configuration du load balancer doit être mis à jour.
- <Insérez ici tout ce que vous pouvez faire sur un Cloud: snapshot/restore, bidouilles réseaux, firewalling, déployer des clusters kube…>.
Mais aussi parce que nous, gestionnaires du Cloud, devons réaliser des actions sur la plateforme:
- Mises à jour.
- Migration (live) de machines virtuelles entre hyperviseurs. Bien sûr la machine doit migrer avec tout son état, règles réseaux incluses par exemple, et les règles doivent être nettoyées sur l’hyperviseur source.
- Plein d’autre choses ;)
Et bien sûr, les pannes et incidents:
- On gère de l’infrastructure physique, l’infrastructure physique ça pète, tout simplement.
- Il peut se passer plein de choses marrantes niveau réseau.
- Et bien sûr, aucun programme n’est parfait, malgré tous les efforts un bug peut arriver.
On a donc une sorte de système distribué où il peut se passer plein de trucs, et bien sûr en tant que client vous voulez juste que ça marche, et si possible 24H/24 et 7H/7 :D
On a donc besoin de programmes capables de piloter des machines virtuelles, des load balancers, configurer du réseau, des clusters Kubernetes… Et surtout de faire converger l’état global de la plateforme dans l’état voulu en cas de changement (volontaire ou non).
Et finalement, voilà ce que je fais: développer ces programmes.
Agents et Orchestrateurs
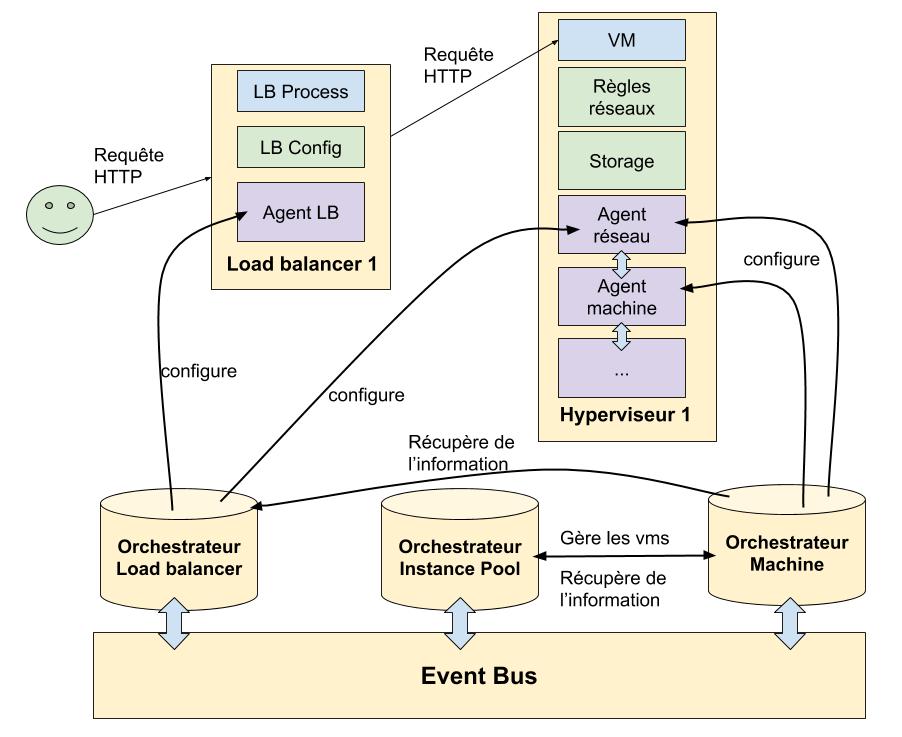
On peut sûrement faire la distinction entre deux types de programmes chez un Cloud Provider. Les agents et les orchestrateurs.
les agents sont des daemons simples qui reçoivent des ordres. Par exemple, un agent tourne sur les hyperviseurs, expose une API qui lui permet par exemple de configurer le réseau d’une machine virtuelle. L’agent ne prend pas de décision, il reçoit un ordre ("configure moi cette machine virtuelle", "démarre cette machine", "configure ce load balancer", "configure ce réseau"…) et l’applique.
Les orchestrateurs sont les donneurs d’ordres, et sont l’intelligence de la plateforme. C’est eux qui vont coordonner les agents (voir parler avec d’autres orchestrateurs) pour faire converger la plateforme dans l’état voulu.
C’est un domaine passionnant.
Là aussi, voici une vue simplifiée de ce qu’il se passe en réalité:
Il y a plein de problèmes "marrants" à régler lors de l’écriture d’orchestrateurs ou d’agents, comme par exemple:
- Eviter les race conditions (actions sur la même entité en parallèle) , Ne pas perdre d’actions
- pouvoir déclencher des exécutions de jobs depuis de multiples sources (actions utilisateurs, actions d’administration, événements…)
- Savoir récupérer "l’état du monde" pour une entité et construire et exécuter le job qui fera converger l’entité vers l’état voulu (les orchestrateurs sont très déclaratifs).
- Gestion des retry et de l’alerting.
Nous avons résolu ces problèmes au fil du temps pour arriver à notre solution actuelle qui continue d’ailleurs d’évoluer (et certaines librairies utilisées sont open source et disponibles sur Github).
Cette solution est derrière tout nos nouveaux projets depuis un petit moment déjà, et c’est très efficace.
Vous êtes intéressé par le sujet ? Nous devrions publier une série d’articles sur les orchestrateurs et notamment sur notre implémentation de notre offre de Kubernetes managé en début d’année prochaine sur le blog d’Exoscale.
Le reste de la plateforme
Facturation, API Gateway, outils de stream processing, gestion des utilisateurs et organisations… sont également des choses importantes sur lesquelles on doit intervenir.
Bien sûr, il y a également chez un Cloud Provider des équipes frontend, des ingénieurs réseaux (gérer le routage interne dans les datacenters mais aussi externe), systèmes, hardware, des personnes travaillant sur le tooling (vous fournissant de supers intégrations Terraform, CLI… dès la sortie d’un nouveau produit), des équipes orientées avant vente…
On retrouve des compétences très vastes, de l’infrastructure physique (design de rack, choix et gestion du hardware…) jusqu’au frontend, et être en contact permanent avec des personnes travaillant dans tous ces domaines est super intéressant et enrichissant.
Les compétences nécessaires pour un développeur Cloud
On m’avait demandé quelles sont les compétences nécessaires pour développer des produits Cloud.
En plus des compétences traditionnelles de développement (et tous les à côtés: CI/CD, monitoring, logging…), avoir une affinité avec le monde du système et du réseau est je pense important.
Mes années d’expérience d’administrateur système me sont grandement utiles, et bien qu’épaulé par des experts systèmes et réseaux (car certains produits demandent des connaissances pointues dans ces domaines) il faut comprendre les technologies et protocoles avec lesquels on travaille.
Il est difficile par exemple d’écrire des agents intéragissant avec le réseau si vous ne connaissez rien en réseau. Nous (les dev) sommes également d’astreintes, donc savoir aller voir ce qu’il se passe niveau réseau pour des produits comme le load balancer est utile ;)
Mais je le redis, je ne suis pas par exemple expert réseau, et les collègues experts sur ces sujets (ops, système, réseau, virtualisation…) sont indispensables, notamment lors du design des produits et en cas de problème critique. Nous (développeurs et développeuses) sommes accompagnés par ces experts pour implémenter les solutions.
Une autre compétence dont on ne parle très peu et qui est je pense très utile (qu’on soit dev, ops, quel que soit le domaine métier d’ailleurs), est d’arriver à garder en tête la vue d’ensemble du fonctionnement des produits que l’on développe.
Bien sûr, il y a de la documentation etc… Mais je pense que pouvoir réfléchir sur le produit dans son ensemble (dès sa conception, pendant son implémentation, pendant sa vie) est très important.
C’est comme cela que l’on peut détecter des erreurs de design, réfléchir aux différents scénarios de pannes possibles, réfléchir à comment faire communiquer les différents composants, réagir rapidement en cas de problèmes… Bref, je pense qu’avoir cette vue d’ensemble sur les produits et sur la façon dont ils interagissent entre eux (et savoir ensuite documenter et implémenter cette vue d’ensemble) est indispensable.
Enfin, la simplicité. Je pense que concevoir des solutions simples et efficaces, reconnaître les avantages et inconvénients des technologies et outils est la clé de la réussite dans l’informatique.
On parle d’ailleurs souvent de pénuries dans nos métiers. Si les gens arretaient de monter des usines à gaz (ou suivre la hype aveuglément) il faudrait selon moi déjà beaucoup moins de monde dans les projets ;)
Conclusion
Travailler sur un produit tech, dont nous sommes nous même utilisateur, le tout entouré de super collègues, c’est cool.
Les challenges techniques sont là, et c’est très satisfaisant de mettre ce genre de produits en prod et ensuite de voir les gens commencer à les utiliser (même ce blog est derrière le load balancer dont je parle dans cet article par exemple !).