Dans cet article, je montrerais comment construire les images qui seront utilisées pour créer nos machines virtuelles.
La machine virtuelle, la base de tout.
Toutes nos applications tourneront sur des machines virtuelles. Ces machines virtuelles auront comme système d’exploitation Debian 10.
Mais je veux pouvoir gérer les images de ces machines. En effet, beaucoup de gens utilisent les images de base fournies par leur cloud provider, et passent ensuite du Ansible/Puppet… pour faire les mises à jour du système d’exploitation et pour installer un certain nombre d’outils "de base".
Pourtant, il est beaucoup plus efficace de construire en amont une image pour sa machine virtuelle, avec les mises à jour déjà appliquées, et les outils déjà installés. Cela permet:
- De déployer chez un cloud provider des distributions Linux ou des systèmes d’exploitations non disponibles par défaut.
- De gagner du temps et pas de perdre 5 minutes lors du déploiement de chaque nouvelle machine virtuelle pour installer toujours la même chose.
- De pouvoir facilement livrer une nouvelle image contenant par exemple des mises à jour de sécurité ou un nouveau outil: de cette façon, on a la garantie que toutes les nouvelles machines créées seront à jour.
- De savoir "où on en est" sur notre infrastructure: en mettant par exemple la date de construction de l’image dans le nom de cette dernière, on peut facilement savoir quelle machine reconstruire (le but étant d’avoir l’infrastructure la plus immutable possible, je dirais qu’il faut toujours se méfier des machines trop vieilles).
- De configurer notre image comme on le veut, comme par exemple avoir un partitionnement spécifique.
- Pourquoi pas même d’installer vos applications directement sur l’image, et donc de vous servir des images comme outil de packaging ?
Pour construire nos images, on utilisera Packer de Hashicorp. J’avais d’ailleurs réalisé un talk sur Packer dont vous pouvez retrouver les slides ici. Je vous conseille de les dérouler car elles contiennent pas mal d’infos intéressantes, notamment sur les les différentes stratégies de construction d’images. je parle notamment dans les slides de la construction d’images:
- En partant d’images de base
cloudfournies par les distributions (Debian, Ubuntu, RedHat…): c’est ce que nous allons faire dans la suite de cet article. - En répondant intéractivement aux questions d’un installer, avec Packer qui simule le clavier.
- Via des fichiers de description d’installations, comme par exemple les fichiers
kickstartde RedHat.
Packer
Packer est donc un outil servant à automatiser la création d’images pour machines virtuelles. Il a plusieurs avantages:
- Il est simple à installer et à utiliser.
- La recette des images est écrite en json, et donc se versionne très bien dans Git.
- Packer permet de construire et de déployer les images sur de nombreux cloud, ou bien de les construire avec des outils comme
qemuouvagrant.
Vous pouvez trouver les fichiers de configurations utilisés dans cet article sur Github.
La configuration de packer se décompose en plusieurs sections:
- variables: on peut déclare des variables dans cette section. Elles pourront être réutilisées ensuite dans le reste de la configuration.
- builders: cette section sert à configure le "quoi" qui démarrera notre machine virtuelle sur laquelle nous appliquerons des modifications
- provisioners: cette section sert à configurer les actions à exécuter sur la machine virtuelle, comme par exemple exécuter des scripts shell.
- post-processors: cette section sert à exécuter des actions
aprèsla construction d’une machine virtuelle, comme par exemple la pousser sur un cloud provider pour utilisation.
Construire notre image Debian 10
On va faire les choses assez simplement:
- Nous utiliserons le builder
qemu(avec l’accélérationkvm, Packer utilisera kvm par défaut si disponible sur la machine) pour construire notre image. Cela nous permet de dissocier la construction de l’image du cloud provider où elle sera utilisée, et il sera donc plus facile de faire du multi cloud si cela s’avère un jour nécessaire. - Nous nous contenterons de faire les mises à jour et d’installer quelques packages sur l’image.
- L’image sera ensuite poussée sur le cloud Exoscale.
La recette Packer
Comme dit précédemment, la configuration est trouvable sur Github.
Je ne vais pas détailler tout le fichier de configuration json de Packer (la doc Packer le fait très bien), mais il est quand même important d’expliquer comment la création de l’image est réalisée, et de ce qui se passe quand une machine démarre chez un cloud provider.
Je vais partir d’une autre image de base pour réaliser mon image. Cette image est l’image Cloud fournie par Debian, et est trouvable ici.
Ces images sont des images ayant déjà Cloud Init d’installé, et sont donc généralement utilisables telles quelles sur n’importe quel cloud provider.
Si vous ne savez pas ce qu’est Cloud Init, voici un petit résumé: c’est une collection de scripts Python qui se lancent lors du démarrage de la machine. Ces scripts Python vont faire plusieurs choses:
-
Chaque cloud provider expose une
datasource, qui est en fait un serveur HTTP exposant des informations sur la machine (zone, offering, ID de la machine, configuration réseau…). Cloud Init se connecte à ce serveur lorsque la machine démarre, va chercher ces informations, et configure la machine en fonction de ce qu’il a reçu.
Par exemple, c’est comme cela que les cloud providers déploiement vos clés SSH sur les machines: sans Cloud Init, vous ne pourriez pas vous connecter sur vos machines virtuelles.
C’est aussi Cloud Init qui gère généralement le redimensionnement d’un disque lorsqu’on l’agrandit. -
Il est également possible de passer à Cloud Init un fichier
yamldécrivant des actions à exécuter au démarrage de la machine. De nombreuses choses sont possibles: configuration des utilisateurs, commandes shell à exécuter, écriture de fichiers… Vous pouvez trouver quelques exemples ici.
Packer démarrera donc avec qemu une machine virtuelle Debian contenant Cloud Init. Une fois démarrée, Packer se connectera dessus via SSH et exécutera des actions (dans notre cas, il exécutera seulement un script shell).
Mais nous ne sommes pas sur un Cloud Provider, donc comment pouvons nous passer notre clé publique à la machine pour que Packer se connecte ? C’est là qu’intervient la datasource NoCloud. Nous allons passer à la machine un disque qui contiendra un fichier user-data. Ce fichier configurera une clé publique sur la machine.
Voici par exemple le contenu du fichier user-data:
#cloud-config
ssh_authorized_keys:
** ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQDWhO7XUDYZDzKi+3TDrmwAsx3r+xtiz1uUoBP69z7cKEHiehXuORdQxi4o9/mA9Nz+fRWm3Wy2aAvm4ZjCpSTx77wTICaJ3mlbRpYfQHqCRiV2Qgeo94GErTpR6xPsn699bJKIu+N/dEzg6l3SV5XWslFZ/7asRc+iS+ZRu3dm2thOWnPwKNcIx9q/VjafdMqzwmV9HIPhfVOhB4MxQcQe0vOf1788cT0ef/5sOyVeYkcNjMvFfX/qb3M/VjvdrCPTzW01c53elptWBp6EVjQG3PQIh2qmhgx594jE3b/ZfHVgfqdkabIsFgF7f+xU1HVchMh5Q4iCDiypZkR3GoBcbW56GMayPoZ7duiCKnLyJJ9VDkZexMuR5suOxrFf5FqLvHW7alxvbmEHofk/nwCniF/OCeq9++MAPJp28wDeM748Im6I/NXk0wRV7I6AXbFLAgkEdU4C/GZ2EinNkRDJJ39ISV03VssYAKCZlYfuK+JvNZbg3smEOQgDa0sJvyN81CCKDl48hk963uUZK7iKy/Vch/abz9eT1t5PABB/7pW+sui0ohpCBYoKQXW6JCXNjE0i7K8uhF9kYXj4PINQd0+ikzbzwmippTJAWlfZMSh4+bpyNQfAZNz9rmXp8PFV51wJRsTPH2Bqzayy4MwXWIV6X4xd2pKptb6J0aZDZQ== packer
Générons ensuite un disque contenant ce fichier:
cloud-localds seed.img user-data
Le fichier seed.img sera à passer à Packer, et Cloud Init exécutera automatiquement le contenu du fichier (et donc configurera notre clé publique).
C’est ce bloc dans la configuration json de Packer qui permettra de passer ce disque à la machine virtuelle:
"qemuargs": [
["-cpu", "qemu64,rdrand=on"],
["-drive", "file=output-qemu/debian-buster.qcow2,format=qcow2,if=virtio"],
["-drive", "file=seed.img,format=raw,if=virtio"]
],
On voit que l’on passe ici plusieurs paramètres à qemu:
- Le premier concerne la génération de nombre aléatoire, chose importante sur une machine virtuelle. Si je sujet vous intéresse, allez ici.
- Le deuxième spécifie le chemin vers l’image qui sera créée par Packer (c’est cette image qui sera envoyée sur le cloud provider).
- Le troisième est notre fichier
seed.imgqui contient donc notre fichier yaml.
Il nous reste une dernière chose à configurer pour se connecter sur la machine: la clée privée à utiliser par Packer.
Cela se configure dans le builder qemu, via l’option ssh_private_key_file. Nous allons passer le chemin vers notre clé privé (qui doit être la clé associée à la clé publique présente dans le fichier seed.img) via une variable d’environnement.
Dans la section variables du fichier Packer, vous pouvez voir:
"ssh_private_key_file": "{{env `PACKER_PRIVATE_KEY`}}"
Ensuite, dans la section builders, vous trouverez:
"ssh_private_key_file": "{{user `ssh_private_key_file`}}",
Nous n’aurons donc qu’à configurer la variable d’environnement PACKER_PRIVATE_KEY pour pouvoir se connecter sur la machine.
Comme dit précédemment, je n’exécuterais qu’un script shell sur notre machine qui installera quelques packages, mettra Cloud Init à jour (de façon assez sale, en téléchargeant le paquet via wget :D) et configurera la datasource Exoscale.
Un premier essai
Vous devriez maintenant pouvoir construire votre image. Commentez toute la partie post-processors du fichier debian.json et lancez:
PACKER_PRIVATE_KEY=/home/mathieu/.ssh/infra/id_rsa packer build debian.json
En modifiant bien sûr la valeur de PACKER_PRIVATE_KEY, et votre image devrait se construire !
Si tout se passe bien, vous devriez voir les logs d’exécution de Packer et à la fin un message indiquant =⇒ Builds finished. The artifacts of successful builds are: -→ qemu: VM files in directory: output-qemu.
En effet, l’image finale devrait être dans output-qemu/debian-buster.qcow2.
Si vous avez un problème, vous pouvez regarder les logs ou utiliser un client vnc (comme remmina) sur Linux pour vous connecter sur la machine en cours de construction si besoin (le port vnc est défini comme étant 6000 dans mon exemple).
Changer la taille de l’image
La taille virtuelle d’une image sur le cloud Exoscale doit être de 10G au minimum. Il faut donc mettre à jour la taille de notre image. Pour cela, nous utilisons un post-processors de type shell-local:
{
"type": "shell-local",
"inline": ["qemu-img resize output-qemu/debian-buster.qcow2 10G"]
}
La taille virtuelle de notre image sera maintenant de 10G. Cela se vérifie facilement:
qemu-img info output-qemu/debian-buster.qcow2
image: output-qemu/debian-buster.qcow2
file format: qcow2
virtual size: 10G (10737418240 bytes)
disk size: 522M
cluster_size: 65536
Format specific information:
compat: 1.1
lazy refcounts: false
refcount bits: 16
corrupt: false
du -sh output-qemu/debian-buster.qcow2
523M output-qemu/debian-buster.qcow2
La taille de notre image sur le disque est de 523M, mais la taille virtuelle est bien de 10G.
Pousser l’image sur Exoscale
Le post processor exoscale-import nous permet d’importer sur le Cloud Exoscale notre image fraîchement construite. Sa configuration est très simple:
{
"type": "exoscale-import",
"api_key": "{{user `exoscale_api_key`}}",
"api_secret": "{{user `exoscale_api_secret`}}",
"image_bucket": "mcorbin.fr.images",
"template_name": "Debian 10 {{timestamp}}",
"template_description": "Debian 10 template",
"template_username": "debian"
}
Les variables d’environnements EXOSCALE_API_KEY et EXOSCALE_API_SECRET serviront à configurer les credentials nécessaires au post processor. On spécifie aussi le bucket sur lequel sera poussée l’image (en effet, les images sont d’abord poussées sur l’object store compatible S3 d’Exoscale avant d’être enregistrées).
Le nom de l’image contiendra le timestamp de la date de création.
Si vous relancez le build en configurant les nouvelles variables d’environnements et en utilisant un bucket vous appartenant dans image_bucket, l’image devrait être maintenant visible sur Exoscale !
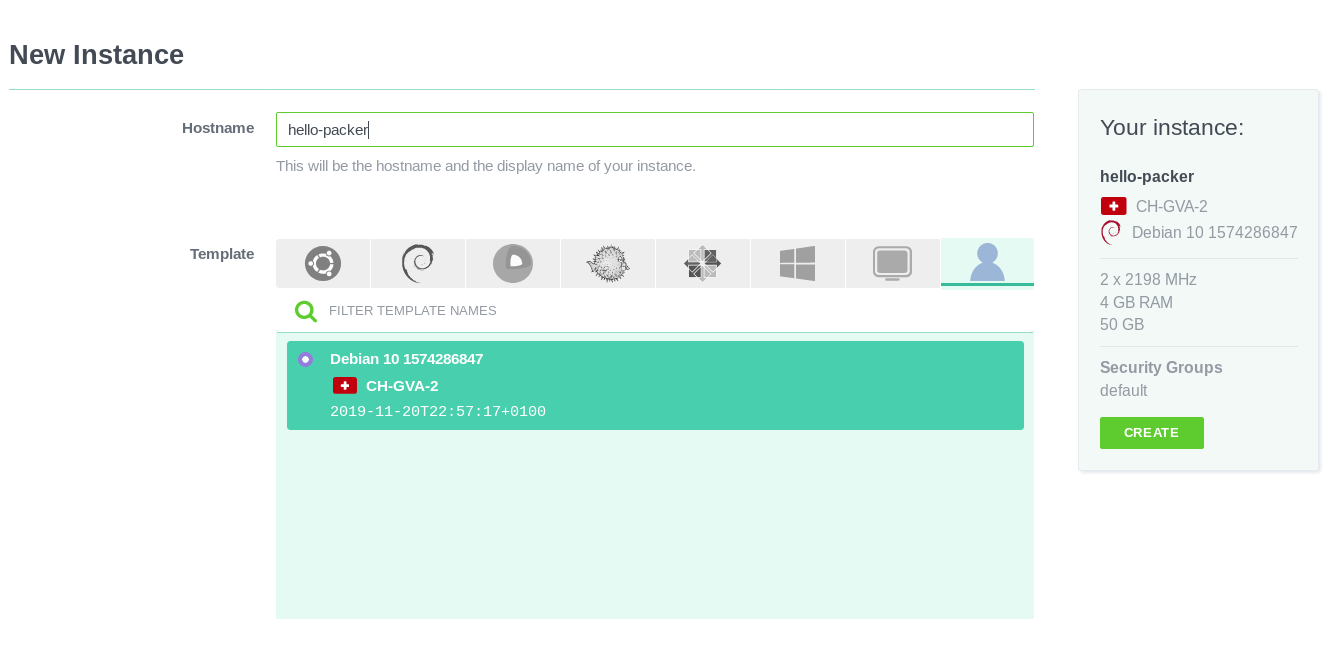
Pour information, le temps entre le lancement du build Packer sur mon ordinateur portable et le moment où l’image est disponible sur le Cloud Exoscale est de 3 minutes 30.
Aller plus loin
Tout cela peut se faire dans une plateforme d’intégration continue type Jenkins. Le but est vraiment que vous puissiez livrer à tout moment une nouvelle image.
Il est également très important de tester ses images.
Avant de les pousser en prod, exécutez des tests dessus: est ce que l’image boot correctement, est ce que les services dessus sont bien démarrés, est ce qu’il n’y a pas de problèmes de sécurité sur l’image… Ces tests doivent aussi se lancer sur votre plateforme d’intégration continue.
Nous avons utilisé dans cet article la datasource Cloud Init nocloud. Il existe une autre datasource, appelée nocloud-net qui permet de faire presque la même chose: avec nocloud-net, on ne passe pas un disque à Cloud Init, Packer exposera via HTTP un répertoire contenant le fichier user-data. Ce dernier sera récupéré par Cloud Init lors du démarrage de la machine virtuelle.
Attention, nocloud-net n’est pas supportée sur toutes les versions de Cloud Init.
La suite
Nous avons vu dans cet article comment construire des images. Dans le prochain article, nous créerons notre infrastructure (machines virtuelles, réseau…) avec Terraform.